요약
이 글은 HWP 포맷의 구조와 문서 정보 저장 방식을 다룹니다. HWP 포맷의 설명과 파일 구조를 중심으로, 문서 정보가 저장되고 관리되는 방식을 상세히 살펴봅니다. 마지막으로, HWPX 포맷에 대한 내용을 간단히 예고합니다.
서론
현대 사회에서 인공지능 기술은 다양한 분야에서 혁신을 이끌고 있으며 데이터의 중요성은 날로 증가하고 있습니다. 특히 자연어 처리와 같은 AI 응용 분야에서는 데이터가 큰 역할을 하고 있는데 이 데이터를 학습하고 가공하여 정확한 예측이 가능해지기 때문입니다.
이러한 맥락에서 워드프로세서 포맷 중 하나인 HWP 포맷은 AI 학습에 있어서 장점이 될 만한 요소들을 가지고 있습니다.
- 단순한 텍스트 외에도 이미지, 표, 차트 등의 다양한 요소로 구성되어 풍부한 정보를 제공할 수 있습니다.
- 제목, 단락, 표 등의 다양한 형식으로 구조화되어 있어 AI 모델이 문서를 이해하고 분석하는데 도움이 될 수 있습니다.
이번 시간에는 오랫동안 생산되고 유통되어 온 HWP 포맷의 구조에 대해 알아보고 문서의 정보들이 어떻게 녹아들어 있는지 확인해 보는 시간을 가져보겠습니다.
HWP 포맷이란?
HWP 포맷은 한글과컴퓨터에서 개발된 문서 포맷으로 한글 97 버전에서 처음 공개되었습니다. 이 포맷의 세부내용은 한동안 공개되지 않았으나, 2010년에 들어 공개되었습니다. 자세한 사항은 한글과컴퓨터 공식 홈페이지에서 확인해 보실 수 있습니다.
다만 포맷에 대한 기본 지식이 없다면 이해하기 어려울 수 있습니다. 그래서 이 블로그 글을 통해 조금 더 쉽게 설명해 드리겠습니다.
HWP 포맷은 바이너리 형식으로 마이크로소프트에서 개발한 CFB(Compound File Binary File Format, 이하 CFB)으로 구성되어 있습니다. 이 포맷은 여러 데이터 스트림을 단일 파일 안에 저장하기 위한 방식으로 FAT(File Allocation Table)와 유사합니다. 간단히 말해 파일 내부에 폴더 구조가 포함된 포맷이라고 이해하시면 됩니다.
HWP 파일 내부에는 다음과 같은 정보들이 포함되어 있습니다.
- File Header
- DocInfo
- DocOptions
- BodyText
- Script
- |HwpSummaryInformation
- PrvImage
- PrvText
이러한 구성요소들은 파일 구조를 통해 효율적으로 관리되고 간단하게 그림으로 표현하면 아래와 같습니다.
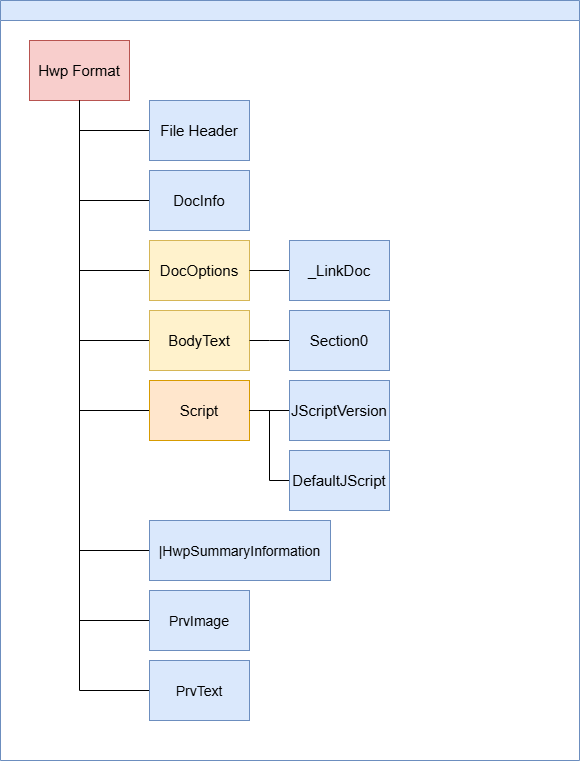
1. File Header
간혹 CFB의 헤더 정보와 HWP의 파일 헤더 정보를 혼동하시는 분들이 계십니다.
HWP 파일은 CFB로 구성되어 있어서 파일 최상단부에 나타나는 정보는 Compound File Header 정보입니다. 이는 CFB를 구성하기 위한 정보입니다.

반면 HWP 포맷에서 사용하는 파일 헤더에는 한글 문서에서 사용하는 포맷 정보가 포함되어 있습니다.
따라서 두 헤더 정보는 서로 다른 목적과 내용을 가지고 있어 구분하는 것이 중요합니다.

HWP 포맷의 파일 헤더에는 다양한 정보가 저장되어 있습니다. 위 이미지에서 확인할 수 있듯이 파일 헤더에는 한글 문서 인식 정보가 포함되어 있습니다. 이 정보는 서명 정보부터 시작해서 문서 버전, 파일 인식 정보들로 구성됩니다. 이러한 정보들을 통해 한/글은 HWP 파일이 어떤 문서인지 판단해서 처리하고 있습니다.
| 자료형 | 길이 | 설명 | |
|---|---|---|---|
| BYTE array[32] | 32 | SIGNATURE (HWP Document File) | |
| DWORD | 4 | 문서 버전 | |
| DWORD | 4 | 범위 | 속성 |
| bit 0 | 압축 여부 | ||
| bit 1 | 암호 설정 여부 | ||
| bit 2 | 배포용 문서 여부 | ||
| … | |||
위 표에 따라 파일 헤더를 해석해보면
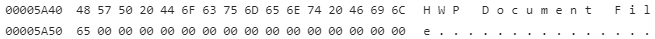
32바이트 영역에 서명정보가 포함되어 있습니다.
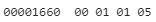
서명 정보 뒤엔 버전정보로 “5.1.1.0”이 나타나고 있으며
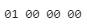
속성값으로는 bit0인 압축만 설정되어 있어 이 문서가 압축되어 있음을 확인할 수 있습니다.
2. DocInfo
문서에서 사용된 글꼴, 글자 속성, 문단 속성 등 문서에서 공통으로 사용되는 정보들을 담고 있는 스트림입니다.
DocInfo의 정보를 확인하기 위해 헥사사 에디터로 파일을 열어보면 알아볼 수 없는 값들로 채워져 있어 당황하신 분들이 많을 것 같습니다. 이번에 설명할 DocInfo와 바로 뒤에 설명할 Section 스트림은 파일 용량을 절약하기 위해 zlib으로 압축된 상태로 저장되어 있습니다.
간단하게 한/글에서 “도구 탭 > 환경설정 > 파일 > 한글 문서(*.hwp) 압축 저장 설정”을 해제한 후 파일을 저장하면 압축되지 않은 상태로 문서가 저장되어 아래와 같이 원본 데이터를 확인할 수 있습니다.

이제 압축되지 않은 DocInfo의 정보를 살펴보겠습니다. 저장된 정보들이 File Header처럼 단순해 보이지 않습니다. DocInfo는 File Header와 다르게 논리적으로 연관된 여러 종류의 정보가 저장되어 있어 레코드 형식으로 구성되어 있습니다. 이를 해석하기 위해선 레코드 형식에 대해 알아볼 필요가 있습니다.
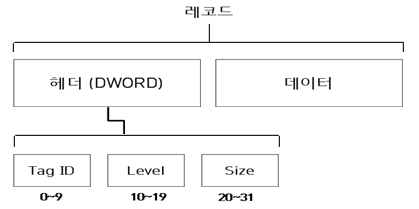
공개된 문서에 의하면 HWP 포맷에서 사용되는 레코드는 위와 같이 구성되어 있습니다. 이 문서를 참고해서 DocInfo를 같이 읽어보며 레코드가 어떻게 구성되는지 알아보겠습니다.

(1) 맨 처음 Tag ID로는 “10 00”이 들어 있습니다.
0x0010은 HWPTAG_BEGIN으로 사용되는 값으로 DocInfo에서 사용되는 HWPTAG_BEGIN은 HWPTAG_DOCUMENT_PROPERTIES입니다.
| Tag ID | Value | 의미 |
|---|---|---|
| HWPTAG_DOCUMENT_PROPERTIES | HWPTAG_BEGIN | 문서 속성 |
| HWPTAG_ID_MAPPINGS | HWPTAG_BEGIN + 1 | 아이디 매핑 헤더 |
| HWPTAG_BIN_DATA | HWPTAG_BEGIN + 2 | 바이너리 데이터 |
| HWPTAG_FACE_NAME | HWPTAG_BEGIN + 3 | 글꼴 |
| … | ||
다음으로는 HWPTAG_DOCUMENT_PROPERTIES가 어떤 속성인지 알아봐야 합니다.
문서에서 HWPTAG_DOCUMENT_PROPERTIES를 찾아보면 아래와 같은 정보들이 저장되어 있음을 알 수 있습니다.
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT16 | 2 | 구역 개수 |
| 문서 내 각종 시작번호에 대한 정보 | ||
| UINT16 | 2 | 페이지 시작 번호 |
| UINT16 | 2 | 각주 시작 번호 |
| UINT16 | 2 | 미주 시작 번호 |
| UINT16 | 2 | 그림 시작 번호 |
| UINT16 | 2 | 표 시작 번호 |
| UINT16 | 2 | 수식 시작 번호 |
| 문서 내 캐럿의 위치 정보 | ||
| UINT32 | 4 | 리스트 아이디 |
| UINT32 | 4 | 문단 아이디 |
| UINT32 | 4 | 문단 내에서의 글자 단위 위치 |
| 전체 길이 | 26 | |
(2) Tag ID 다음으로는 “A0 01” 값이 나타납니다. 이 값은 레코드의 사이즈 정보를 나타내며 16진수 1A(10진수, 26)으로 위 표에 나타난 전체 길이와 동일함을 확인할 수 있습니다.
(3) 확인한 Tag ID와 사이즈 값으로 HWPTAG_DOCUMENT_PROPERTIES 레코드가 차지하는 영역을 알 수 있습니다.
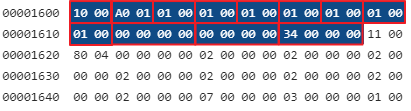
지금까지 알아낸 정보로 HWPTAG_DOCUMENT_PROPERTIES 레코드 영역을 바이트 단위로 읽어 해석해 보면 아래 표와 같은 정보를 얻을 수 있습니다.
| Tag ID | 0x0010 (HWPTAG_DOCUMENT_PROPERTIES) |
| Tag Size | 0x001A |
| 구역 갯수 | 0x001A |
| 페이지 시작 번호 | 0x001A |
| 각주 시작 번호 | 0x001A |
| 미주 시작 번호 | 0x001A |
| 그림 시작 번호 | 0x001A |
| 표 시작 번호 | 0x001A |
| 수식 시작 번호 | 0x001A |
| 리스트 아이디 | 0x0000 |
| 문단 아이디 | 0x0000 |
| 문단 내에서의 글자 단위 위치 | 0x0034 |
3. DocOptions
이 스토리지에는 연결 문서, 배포용 문서, 공인인증서 등의 정보가 스트림으로 저장됩니다.
4. BodyText (Section)
문서의 본문에 해당하는 실제 내용이 저장됩니다. BodyText 스토리지는 본문의 구역 수에 따라 여러 개의 Section 스트림으로 구성됩니다. (예] 구역이 2개일 경우 BodyText는 Section0, Section1을 포함합니다.)
이 스트림은 표의 내용이나 본문의 구성 등 실제 본문이 어떻게 이루어져 있는지 확인할 수 있습니다. 본문에서 사용되는 데이터 레코드는 종류가 다양하고 복잡하므로 다음 시간에 자세히 살펴보겠습니다.
5. Script
“도구 > 스크립트 매크로” 기능에 정의된 스크립트 정보가 기록된 스토리지입니다.
6. |HwpSummaryInformation
문서 요약 정보가 저장되어 있으며, “파일 > 문서정보” 대화상자에서 확인할 수 있습니다.
문서 요약 정보는 마이크로소프트의 PropertySet 구조로 되어 있으며 자세한 설명은 이 링크에서 확인하실 수 있습니다.
7. PrvImage
문서의 미리 보기 이미지로 문서의 첫 번째 페이지 이미지가 저장되어 있습니다. 최신 버전에서는 PNG 포맷으로 저장됩니다.
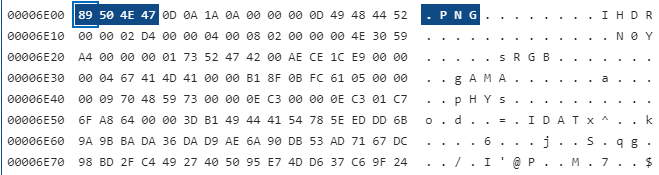
8. PrvText
문서의 미리 보기 텍스트로 문서의 첫 번째 페이지 내용이 저장되어 있습니다. 유니코드 문자열로 저장됩니다.
마치며
여기까지 HWP 포맷이 문서 정보를 저장하는 방식에 대해 간략히 살펴보았습니다. HWP 포맷은 바이너리 형식으로 저장되어 사람이 직접 읽기 어렵고, 특정 소프트웨어에서만 열람 및 수정이 가능하도록 설계되었습니다.
반면, 개방형 포맷인 HWPX 포맷은 오픈 XML 기반의 포맷으로 데이터가 구조화되어 있어 사람이 내용을 쉽게 이해할 수 있도록 설계되었습니다.
다음 시간에는 HWPX 포맷은 HWP 포맷과는 어떤 차별화된 방식으로 정보를 저장하는지 알아보겠습니다.
📌 한/글 문서 파일 형식 시리즈
👉 1편: 한/글 문서 파일 형식 : HWP 포맷 구조 살펴보기↗
2편: 한/글 문서 파일 형식 : HWPX 포맷 구조 살펴보기↗
3편: 한/글 문서 파일 형식: Python을 통한 HWP 포맷 파싱하기 (1)↗
4편: 한/글 문서 파일 형식: Python을 통한 HWPX 포맷 파싱하기 (1)↗