한컴테크를 통해 한컴의 기술을 공유합니다. 한컴의 프로그래밍, 프레임워크, 라이브러리 및 도구 등 다양한 기술을 만나보세요. 한컴 개발자들의 다양한 지식을 회사라는 울타리를 넘어 여러분과 공유합니다. 한컴이 제공하는 기술블로그에서 새로운 아이디어와 도전을 마주하고, 개발자가 꿈꾸는 미래를 실현하세요.
우리가 복잡한 Machine Learning 세계에서 쉽게 ML 모델을 구축하고, 서비스를 런칭하고, 유지 가능하도록 하는 MLOps 플랫폼, Kubeflow에 대해 알아보도록 하겠습니다. 들어가기에 앞서, 과연 MLOps가 무엇인지에 대해서부터 알아보는 시간을 가지도록 하겠습니다.
우리가 배우는 대부분의 단기 머신러닝 교육 과정에서는 ML 모델만을 만드는 데 초점을 맞췄습니다. ML 시스템에 대해서는 잘 다루지 않죠. 그래서 많은 분들이 전체적인 ML 시스템은 생소하실 텐데요. 그림 1에서 볼 수 있듯이, ML 모델은 전체 ML 시스템 내에서 5%밖에 차지하지 않습니다. ML 모델보다는 모델 외적인 부분에 더 신경을 써야할 수 있다는 말이 됩니다. ML 시스템 내에서는 데이터의 수집, 처리부터 모델의 서빙 및 모니터링까지 모든 단계가 망라되어 있습니다. 그런데 이 수많은 요소들은 누가 관리할까요? 또, 이 요소들을 일일히 손수 만들고, 실행할까요? 엄청 불편할 것 같은데요? 해결책으로 이것들의 관리를 쉽게 도와주는 MLOps가 있습니다!
1-2. DevOps는 들어봤는데, MLOps는 뭐지?
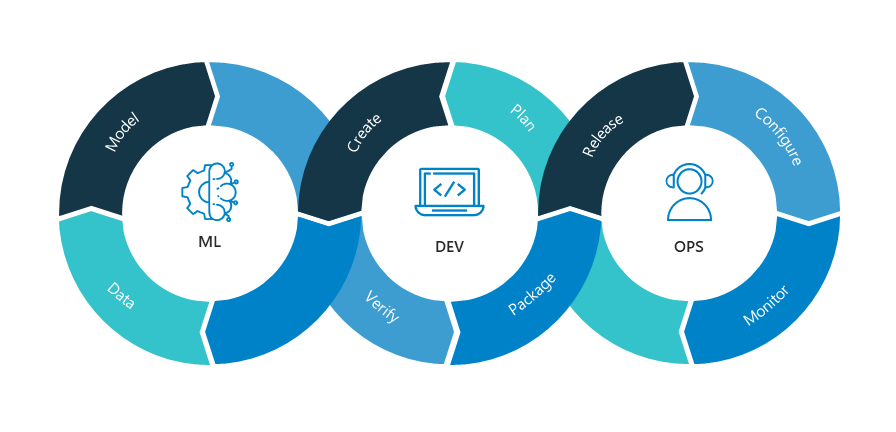
지속적 통합(CI, Continuous Integration)과 지속적 배포(CD, Continuous Delivery)를 목표로 Development(개발)와 Operation(운영)을 합친 말인 DevOps는 한 번쯤 들어보셨을 겁니다. 서비스 개발과 운영을 일원화하여, 운영을 효율적으로 만들어 주는 것이 DevOps라는 개념인데요. 이러한 개념을 Machine Learning 시스템에 적용하여, 지속적 통합(CI, Continuous Integration)과 지속적 배포(CD, Continuous Delivery)에 추가로, 지속적 학습(CT, Continuous Training)까지 확장한 것이 바로 MLOps 입니다.
MLOps란 데이터의 준비 및 전처리, 모델의 생성 및 실험 그리고 프로덕션까지 모든 기계 학습 과정을 프로덕션 시스템으로 가져오는 과정입니다. 이 과정에서 data scientists, ML researchers, operation professionals 간의 소통이 유기적으로 이루어지게 됩니다. MLOps를 채택함으로써, Machine Learning 프로세스의 자동화를 높이고, 생산 모델의 품질을 향상시키는 동시에, 비지니스 요구사항에도 포커싱할 수 있습니다.
기존 DevOps와 MLOps가 가지는 몇가지 차이점이 있는데요.
Team 구성 : ML 프로젝트 팀에서는 일반적으로 데이터 분석, 모델 개발, 실험에 중점을 두는 data scientists 또는 ML researchers가 포함됩니다. 팀 구성원 중에는 프로덕션 수준의 서비스를 빌드 가능한 software engineer가 없을 수도 있습니다.
개발 단계 : ML은 기본적으로 실험의 연속입니다. 실험자는 특성, 알고리즘, 모델링 기법, 매개변수 구성을 다양하게 시도하여 최적의 조합을 찾아냅니다. 이 끊임없는 과정 안에서 효과적이었던 결과와 아닌 결과를 추적하고, 그것들의 재사용성을 극대화하고, 조합해가면서, 결과를 최대한 끌어올립니다.
테스트 단계 : ML 시스템 테스트는 다른 소프트웨어 시스템 테스트보다 더 복잡합니다. 일반적인 단위 테스트 및 통합 테스트 외에도 데이터 검증, 학습된 모델 품질 평가, 모델 검증이 필요합니다.
배포 단계 : ML 시스템에서 배포는 오프라인으로 학습된 ML 모델을 예측 서비스로 배포하는 것만큼 간단하지 않습니다. ML 시스템에서는 모델이 자동으로 재학습되고, 배포하기 위해, 파이프라인을 제공합니다. 이 파이프라인을 사용하면 데이터 과학자가 배포하기 전 새 모델을 학습시키고 검증하기 위해 수동으로 수행되어야 하는 단계를 자동화해야 합니다.
프로덕션 단계 : ML 모델은 최적화되지 않은 코딩뿐만 아니라 끊임없이 변화하는 데이터로 인해 성능이 저하될 수 있습니다. 즉, ML 모델은 기존 소프트웨어 시스템보다 다양한 방식으로 손상될 수 있기 때문에 이러한 손상 가능성을 고려해야 합니다. 따라서, 데이터를 추적하고 모델의 성능을 모니터링하여 값이 기대치를 벗어나면 알림을 전송하거나 롤백해야 합니다.
2. ML Work Flow
ML 시스템을 개발하고 배포할 때, 데이터의 수집부터 모델의 배포 및 모니터링까지 시스템의 흘러가는 과정을 ML Work Flow라고 합니다. ML Work Flow는 일반적으로 몇가지 유형의 단계로 구성되고, 반복되는 프로세스입니다. 그리고 이 ML Work Flow가 잘 작동될 수 있도록, MLOps가 도와주고 있습니다.
ML Work Flow는 크게 2가지의 단계로 나뉘게 됩니다. 실험 단계(Experimental phase)와 프로덕션 단계(Production phase) 이 2단계별로 자세히 알아볼까요?
실험 단계(Experimental phase) : 초기 가정을 기반으로 모델을 개발하고, 원하는 결과가 나올 때까지, 모델을 반복적으로 테스트하고 업데이트하는 단계.
문제를 정의하고, 데이터를 모으고 분석합니다.
ML 알고리즘을 선택하고, 코딩합니다.
데이터와 모델 학습을 가지고, 실험합니다.
가장 효율적인 처리와 가능한 가장 정확한 결과를 보장하기 위해 모델 하이퍼 파라미터를 조정합니다.
프로덕션 단계(Production phase) : 개발된 모델 및 시스템을 배포하는 단계.
교육 시스템에 필요한 형식으로 데이터를 변환합니다. 모델이 학습 및 예측 중에 일관되게 작동하도록 하려면 변환 프로세스가 실험 및 생산 단계에서 동일해야 합니다.
ML 모델을 훈련시킵니다.
ML 모델을 온라인 예측 또는 배치 모드 실행을 위해 서빙합니다.
모델의 성능을 모니터링합니다.
마치며
이번 포스팅에서는 MLOps가 무엇인지, ML Work Flow가 어떤 단계를 거쳐 흘러가는지 알아봤습니다. 시중에는 ML Work Flow는 물론, ML 시스템을 구축하고, 운영을 도와주는 MLOps 과정을 도와주는 ML 플랫폼이 많습니다. 다음 포스팅에서는 MLOps계에서 가장 인기를 얻고 있는 플랫폼인 Kubeflow에 대해 알아보도록 하겠습니다.