Grafana(https://grafana.com/)
Grafana는 수집된 정보를 시각화하여 보여주는 도구입니다.
클라우드기반실에서는 우리 회사의 사내외에서 사용 중인 클러스터 및 서비스의 메트릭 정보를 수집하여 상태를 확인 및 예측을 할 수 있도록 대시보드를 구성하고 있으며, 이번 가이드에서는 Orca(사내 구축한 클러스터로 DEV / STG / PROD 가 있으며, 이중 Orca는 DEV 입니다.)에 배포한 서비스를 모니터링하고 Resource Request와 Limit을 설정하는 방법에 대해 알아보도록 하겠습니다.
시작하기 전에
이 작업을 위해서는 개발한 서비스가 Orca에 배포되어 있어야 합니다.
여기서는 Orca Cluster에 아래와 같이 Pod가 배포되어 있다고 가정합니다.
- namespace : fantasy
- pod : backend
- scale : 1개
Grafana 접속
Dashboard 선택
로그인 후 왼쪽 위의 Menu > Dashboard 순서로 갑니다.
Dashboards에서, HancomCloud-IDP > Pod Monitor를 선택합니다.
Pod Monitor
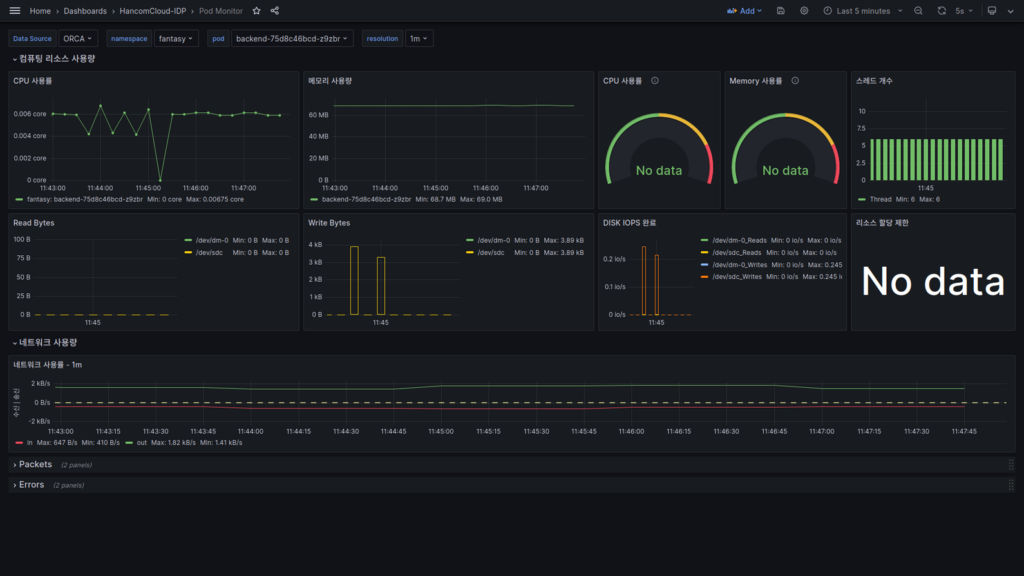
Pod Monitor Dashboard에 들어왔습니다.
아래의 순서로 설정하여 배포한 서비스를 모니터링해 보겠습니다.
관찰할 매트릭의 수집 범위 및 갱신주기 선택
화면 오른쪽 위에서 관찰할 매트릭의 시간 대역 및 갱신주기를 선택합니다.
서비스 성능 평가가 목적이므로 시간대역은 5분, 갱신주기는 5초로 선택합니다.
내 서비스 선택
배포된 서비스를 선택합니다.
- Data Source : Orca
- namespace : fantasy
- pod : backend
- resolution : 1m
Data Source는 클러스터를 선택할 수 있습니다. namespace는 서비스를 배포한 것을 선택하면 됩니다.
pod는 여러 개를 선택할 수 있으며, 여기서는 backend라는 Deployment를 배포하여 backend.*의 값을
가지는 항목을 선택했습니다.
resolution은 얼마나 자세히 보여줄 것인지 결정하는 항목으로 1분을 선택했습니다.
리소스 모니터 패널
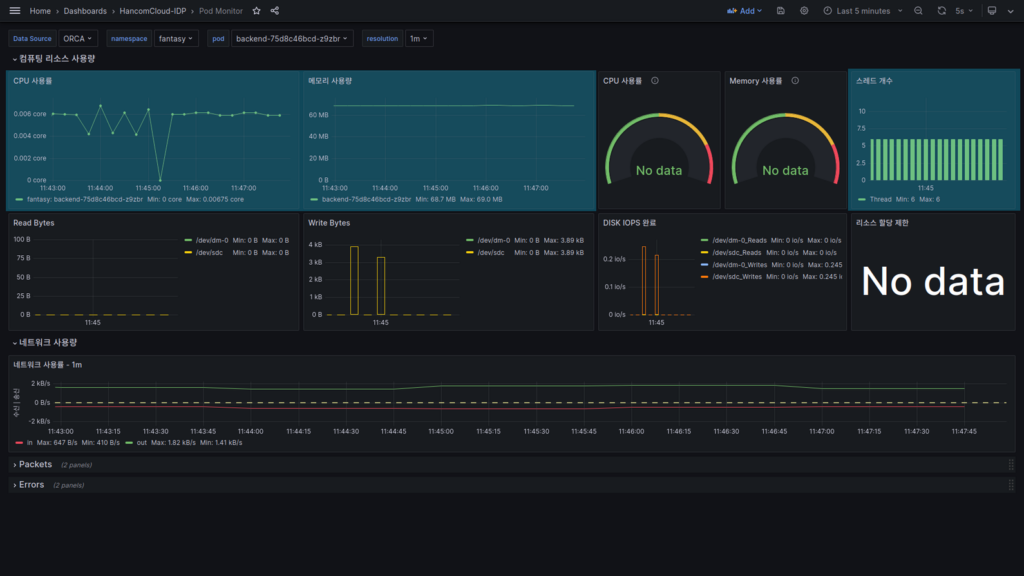
여기서는 서비스가 사용하는 HW 리소스의 사용량이 표시됩니다.
- CPU 사용률은 쿠버네티스의 관리 단위인 Core로 표시됩니다.
- 메모리 사용량은 Container 단위로 표시가 됩니다. 서비스가 Kill 된 경우 여기서 확인할 수 있습니다.
- 스레드 개수는 현재 서비스가 사용하는 개수가 표시됩니다.
리소스 제한 대비 사용률
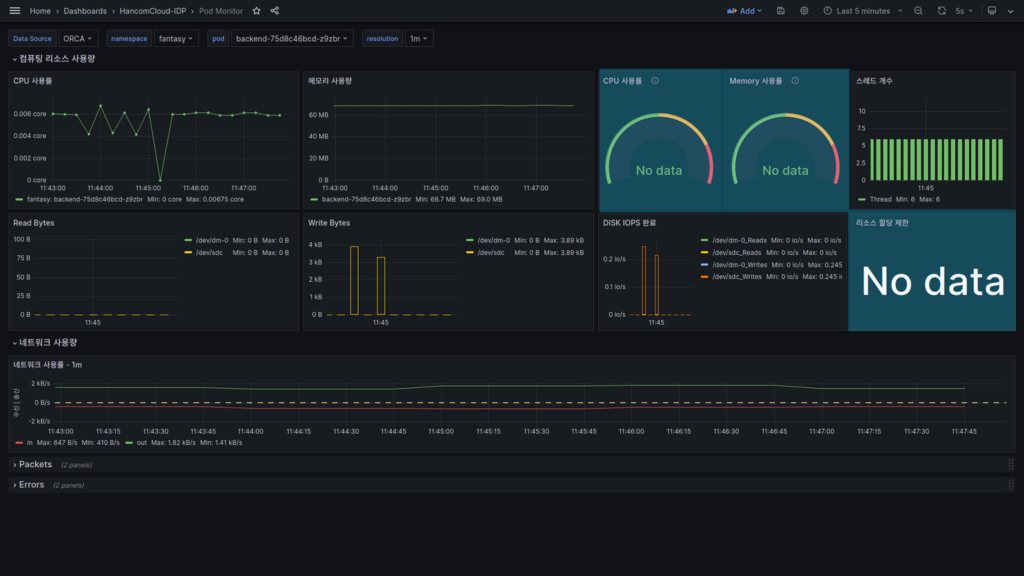
배포한 Pod의 리소스 제한이 걸려있다면 할당 내용과 제한량을 기준으로 한 사용량이 표시됩니다.
현재 배포한 서비스에서는 할당량 제한이 없어 No data로 표시되지만, 제한이 걸려있는 경우 아래와 같이 정보가 표시됩니다.
Disk IO 정보
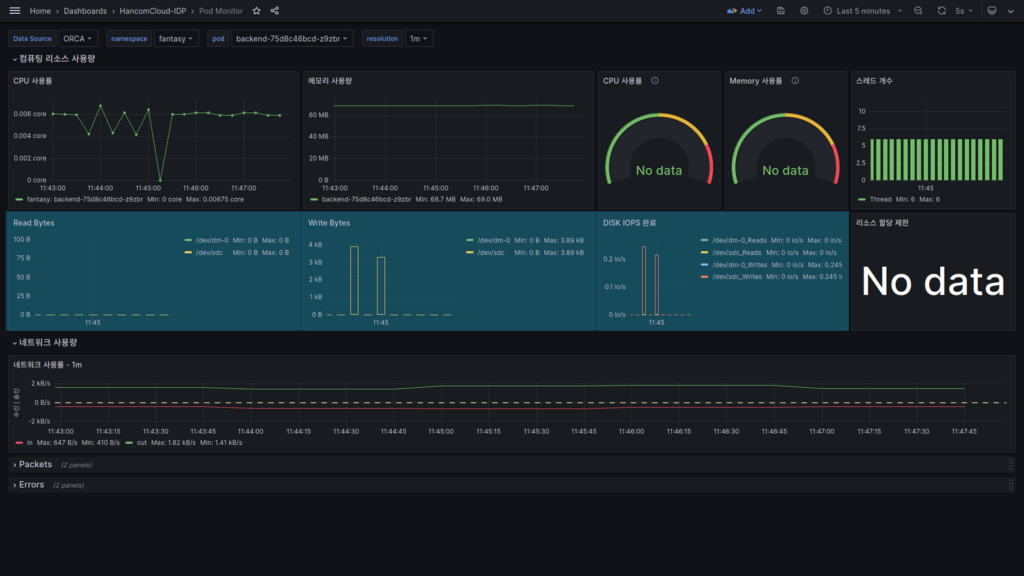
컨테이너 단위의 내부 Disk IO 정보가 표시됩니다.
네트워크 정보
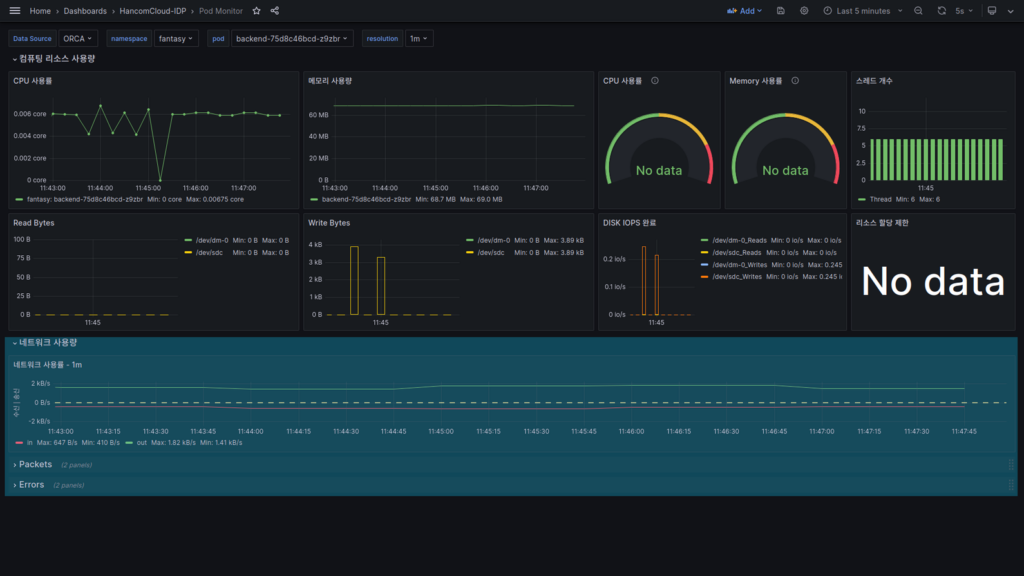
Pod 단위의 네트워크 사용 정보가 표시됩니다.
TX(Transmitt)는 녹색, RX(Receive)는 적색으로 표시가 되며 RX의 시각적 편의를 위해 아래로 표시되어 있으며 Negative 값은 아닙니다.
서비스 성능 평가하기
여기서는 서비스 성능을 평가하여 Production에 배포할 서비스의 아래 내용을 정의하는 예제를 보입니다.
- min, max Replicas
- Resource Request / Limit
- Request를 대비 HPA(Horizontal Pod Autoscaling)
타겟 서비스에 초당 10개의 동시 접속자를 발생시키고, 1개의 연결당 400MB의 메모리를 할당하는 동작 테스트를 2분간 진행합니다.
- 평가 테스트 시간은 2분 이상을 추천합니다.
- 우리의 목적은 서비스가 죽더라도 Endpoint 유저가 발생시키는 Request가 실패하지 않는 것입니다.
- 평가 도구는 팀 내에서 개발한 WhiteFox(https://gitlab.hancom.io/fantasy.h/white-fox)를 사용했습니다.
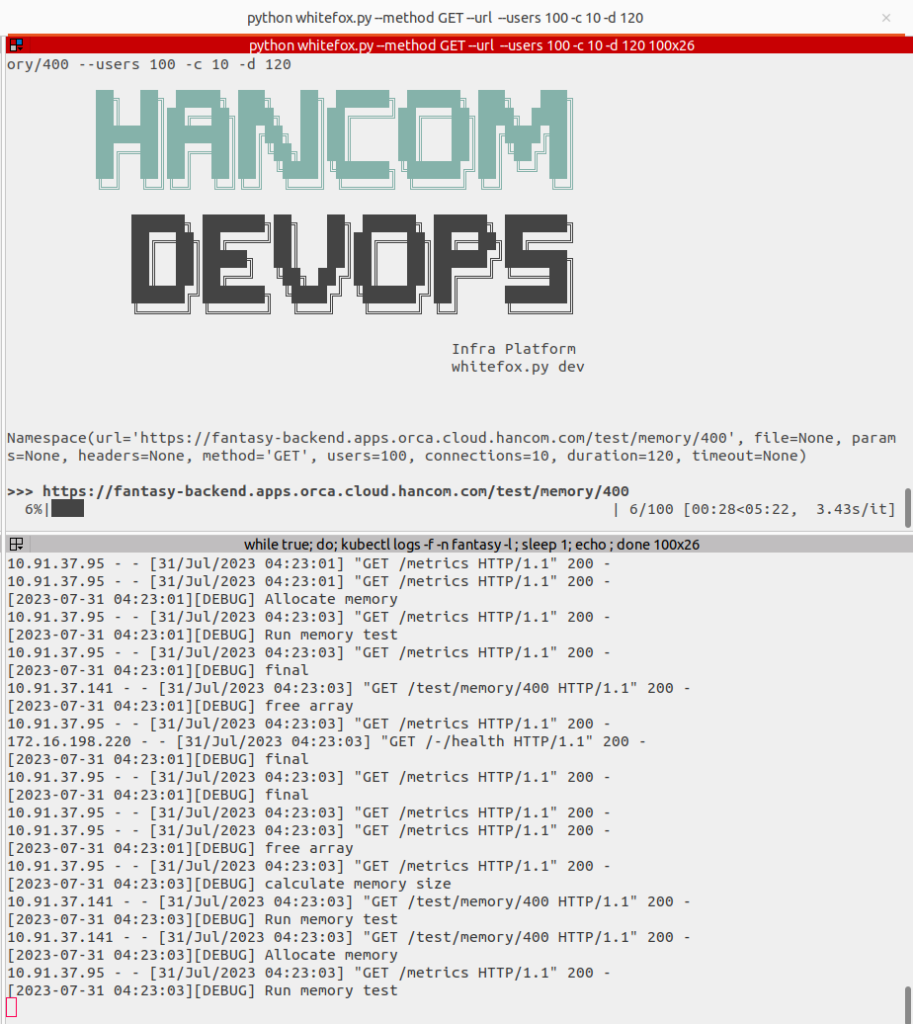
평가를 시작합니다.
위 화면은 평가 진행률을 표시했으며, 아래는 서비스의 로그를 출력했습니다.
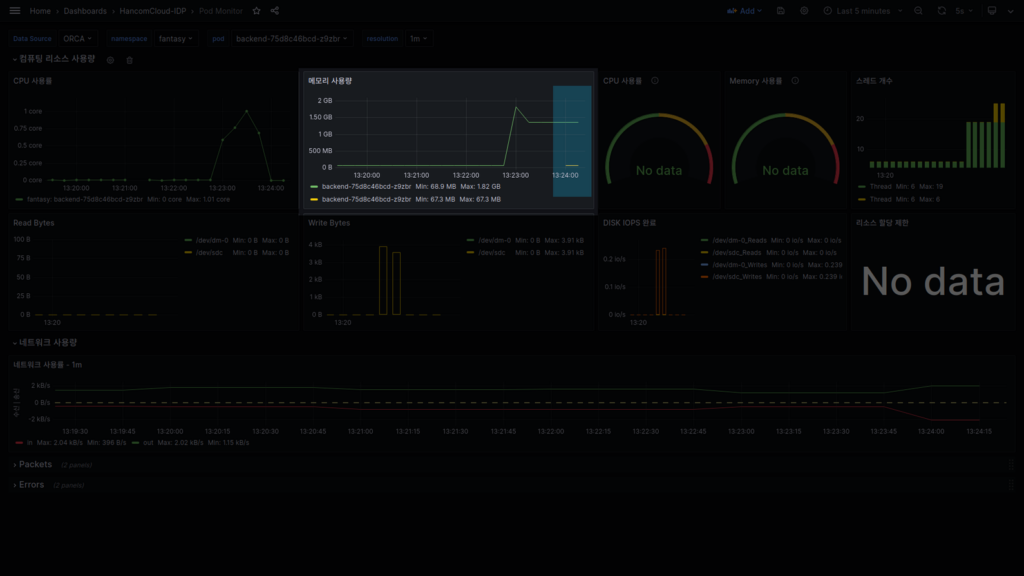
평가를 시작하고 얼마 되지 않아 서비스가 Kill 되었습니다.
대시보드의 “메모리 사용량” 패널 부분을 보면 기존과는 다르게 새로운 항목(노란색)이 추가된 것을 볼 수 있습니다.
메모리 사용량은 Pod의 Container 단위로 출력되도록 하였고, Pod는 1개만 선택된 상태이기 때문에 해당 패널에서 새로 생기는 부분은 Container가 새로 떴다는 것을 의미하고, 이는 “기존에 떠 있는 Container(녹색)는 Kill 되었다”라고 볼 수 있습니다.
첫 Container(녹색)의 메모리 사용량
- 최솟값 : 68.9MB
- 최댓값 : 1.82GB
새로 뜬 Container(노란색)의 메모리 사용량
- 최솟값 : 67.3MB
- 최댓값 : 67.3MB
이 두 값을 비교해 보면, backend라는 서비스의 최소 필요한 메모리는 68.9MB 이상이며 1.82GB를 할당하다가 어떠한 이유에서인지 쿠버네티스에 의해서 OOM(Out of Memory) Signal을 받았습니다.
먼저 이 서비스의 IDLE-Time의 리소스 사용량은 아래와 같습니다.
- CPU : 5m Core
- RAM : 68.9MB
이를 기반으로 Resource request는 아래와 같이 설정할 수 있습니다.
- CPU : 10m Core
- RAM : 100Mi
측정에 나온 값보다 2~30% 추가로 지정합니다.
그리고 Resource Limit는 다음과 같이 설정할 수 있습니다.
- CPU : 1010m Core
- RAM : 2Gi
그리고, 이 값을 기준으로 HPA 값을 정의한다면
- targetCPUUtilizationPercentage : 80000
- targetMemoryUtilizationPercentage : 1500
Request 리소스 대비 CPU 0.8Core, 또는 메모리 사용량이 1.5GB에 도달하는 경우 Autoscaling을 진행할 수 있습니다.
그럼, 몇 개로 증가할지 정하면 됩니다.
1개의 커넥션당 400MB의 메모리를 사용했고, 관측된 메모리의 양은 1.8GB이므로 4개의 커넥션 언저리에서 Kill 되었다는 걸 알 수 있습니다. 우리의 요구사항은 10개의 커넥션이므로 이를 가지고 단순 계산하면 1개의 Pod가 3개의 커넥션을 커버할 수 있다고 볼 수 있습니다.
그럼, 4개의 Pod가 생성되면 10개의 커넥션은 커버가 될 수 있으나 혹시 모르니 1개를 더 지정하도록 하여 scale 값을 정의합니다.
- min : 1
- max : 5
갑자기 많은 양의 부하가 발생하면 Pod가 생성되기 전에 Killed 될 수 있습니다.
그 경우를 대비해서 min 값을 2~3개로 정의하는 것도 좋습니다.
resources:
requests:
cpu: 10m
memory: 100Mi
limits:
cpu: 1010m
memory 2Gi
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 80000
targetMemoryUtilizationPercentage: 1500위의 값으로 helm chart를 반영하여 다시 배포합니다.
그리고 평가를 다시 진행합니다.
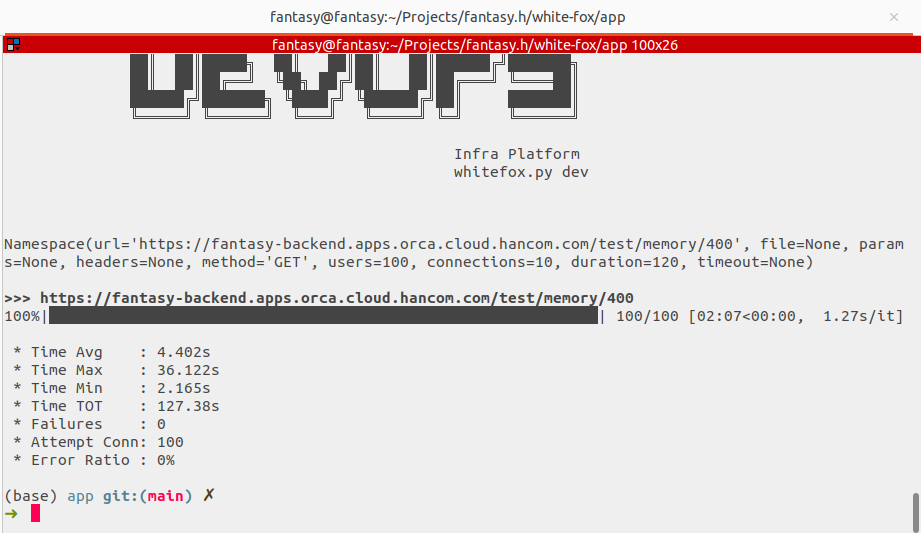
평가가 실패 없이 성공적으로 끝났습니다.
평가 확인하기
상단 Pod의 콤보 박스를 열어 모든 backend Pod를 선택합니다.
메모리 사용량 패널 우측의 더 보기(…)을 선택하여 view 화면을 크게 엽니다.
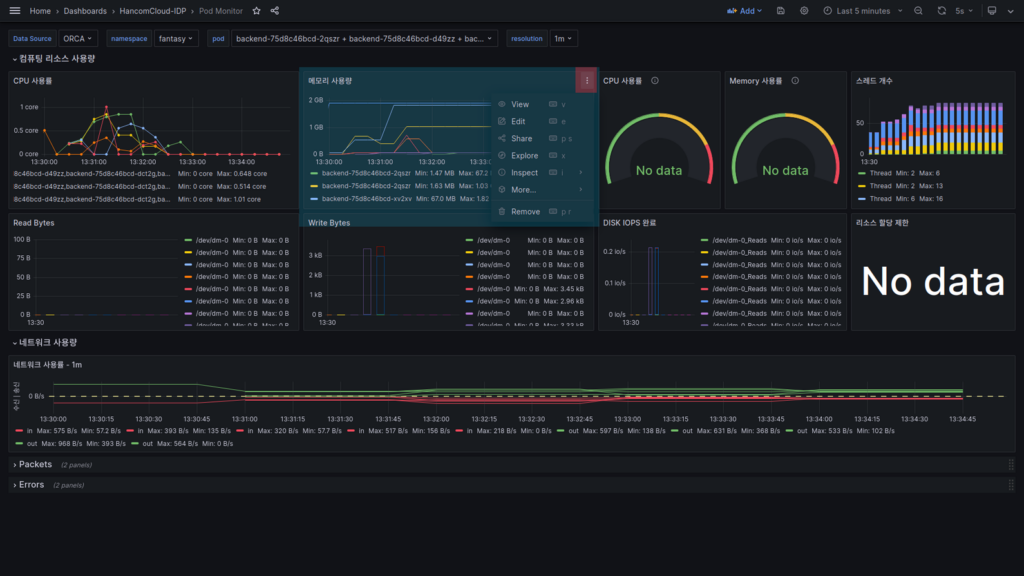
그러면 아래처럼 전체화면으로 볼 수 있습니다.
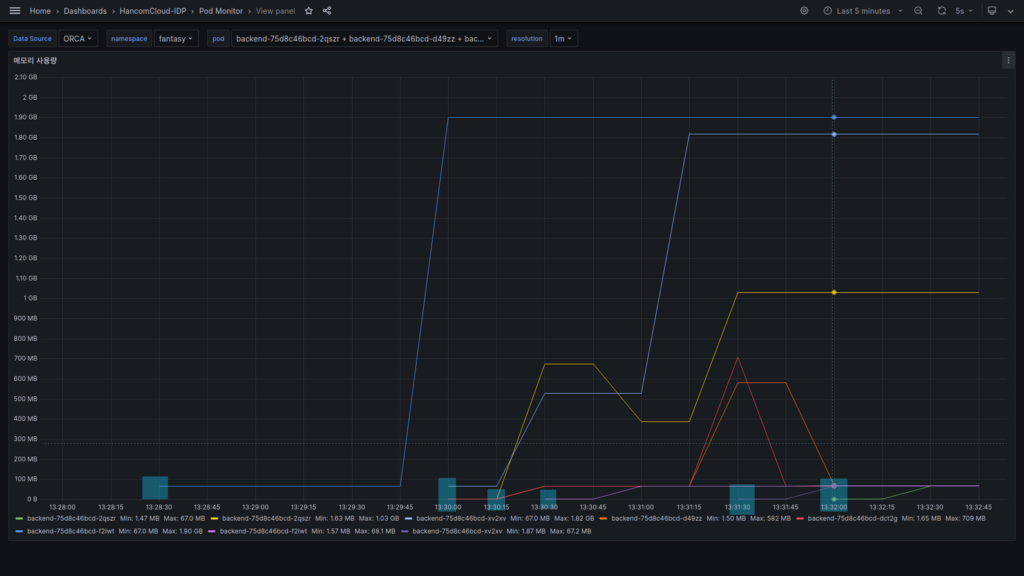
위 화면에서 파란색 박스로 표시한 곳은 Container가 시작된 부분입니다.
처음 파란색 선의 Container는 새로 배포한 이후 첫 Pod입니다.
그 후로 Autoscaling에 의해 5개의 Pod가 생성된 것을 알 수 있습니다.
우리 설정 때문에 1Pod = 1Container 입니다.
여기서 이상한 점은, 전체 Pod 개수를 5개로 지정했는데 5번 생성이 되었다는 점입니다.
이건 한 개 이상의 Pod에서 2개 이상의 컨테이너가 생성되었다는 걸 의미하며, 이 말은 컨테이너가 Killed 되었다는 의미입니다.
위 그림에서 3개의 Pod가 2개씩 화면에 표시되고 있습니다. 5개 중 3개의 서비스가 떨어졌다(서비스를 실행중이던 Application이 killed 되었다)는 것을 알 수 있지만 평가상 모든 Request는 성공했습니다.
결론
먼저 처음에 계획했던 목적은 다음과 같습니다.
서비스가 죽더라도 Endpoint 유저가 발생시키는 Request가 실패하지 않는 것
그리고 목적을 만족하기 위해 다음과 같이 설정했습니다.
- Replicas
- min: 1
- max: 5
- Resource
- Request:
- cpu: 10m
- memory: 100Mi
- Limits:
- cpu: 1010m
- memory: 2Gi
- Request:
- Autoscaling:
- targetCPUUtilizationPercentage: 80000 (800m Core)
- targetMemoryUtilizationPercentage: 1500 (1.5Gi)
초기 구성에서 2분간 초당 10개의 동시접속 처리를 실패하던 것이, 위의 Autoscaling구성을 통해 2분동안 모든 요청을 실패없이 수행하는 서비스를 제공했습니다.
단, 두 번째 테스트에서 위 구성으로 Endpoint 유저의 request에 실패는 없었으나 서비스 로딩이 오래 걸리는 경우 Replica의 개수가 적으면 실패가 발생할 수 있습니다.
이런 경우를 예방하기 위해 초기 Replica의 개수를 증가하거나 Autoscaling의 기준점을 더 낮게 하여 문제를 예방할 수 있습니다.
이 가이드처럼 Grafana를 활용함으로써 몇 가지 이점을 얻을 수 있습니다.
- 시각적인 모니터링: Grafana를 통한 시각적인 대시보드를 통해 서비스의 성능 및 리소스 사용 상황을 실시간으로 모니터링할 수 있습니다. 이를 통해 빠르게 문제를 감지하고 조치할 수 있습니다.
- 자동화된 운영: Helm chart 및 Autoscaling을 통한 설정들은 자동화된 배포 및 운영을 가능하게 합니다. 이는 운영팀의 업무 간소화와 안정적인 배포 프로세스를 유지하는 데 도움이 됩니다.
- 성능 향상: 리소스 사용 패턴을 모니터링하고 최적화함으로써 서비스의 성능을 향상시킬 수 있습니다. 사용 패턴에 따라 리소스를 동적으로 조절하여 항상 최상의 성능을 유지할 수 있습니다.
- 테스트와 검증 간소화: 가이드에서 설명한 대로 테스트를 수행하고 설정을 검증함으로써 새로운 서비스 배포나 구성 변경 시의 안정성을 보다 간편하게 테스트할 수 있습니다.
이러한 장점들은 안정성, 효율성, 비용 절감 등 다양한 측면을 개발팀에서 예측하는 데 도움을 줄 수 있을 것입니다. 개발 중이거나 배포한 서비스에서 적극 활용하여 우리의 고객들에게 안정적인 서비스를 제공할 수 있길 바랍니다.