시작하며…
이번 글을 어떤 주제로 어떻게 작성해 나가야 할지 많은 고민을 하였습니다.
현재 여러 기업에서 ChatGPT와 같은 LLM을 개발하고 서비스 제품을 개발 중이거나 출시 하더라도 계속해서 성능 향상을 도모해야 할 것입니다.
또한 LLM을 개선하고 학습시키는 모델링 개발자 외에도 많은 팀원들, 유관부서 사람들과 소통하고 협업해야 할 것입니다.
그래서 저는 이 글이 개발자뿐만 아니라 인공지능 개발에 함께 동참하는 사람들이 어떻게 모델을 학습하고 개선해 나가는지를 조금이라도 알고 이해했으면 좋겠다는 마음에서 LLM에 대한 내용을 조금 쉽게? 작성하였습니다.
모델 학습에 있어 많은 요소들이 필요하고 그중 하나라도 문제가 생긴다면 모델 성능에 큰 영향을 줄 수 있기 때문에 AI 개발을 조금이라도 같이 이해하고 어려운 문제들을 함께 풀어나갈 수 있기를 희망하며… 글을 시작하도록 하겠습니다.
1. LLM의 등장
2022년 11월 30일, OpenAI의 ChatGPT 출시는 IT 업계를 비롯한 전 세계를 뒤흔들었습니다. 이 애플리케이션 기반의 챗봇 AI는 인간 피드백을 기반으로 한 강화 학습(RLHF)을 통해 성능을 높였으며, 그 결과는 사람이 답변하는 것과 유사한 수준으로 놀라움을 안겨주었습니다.
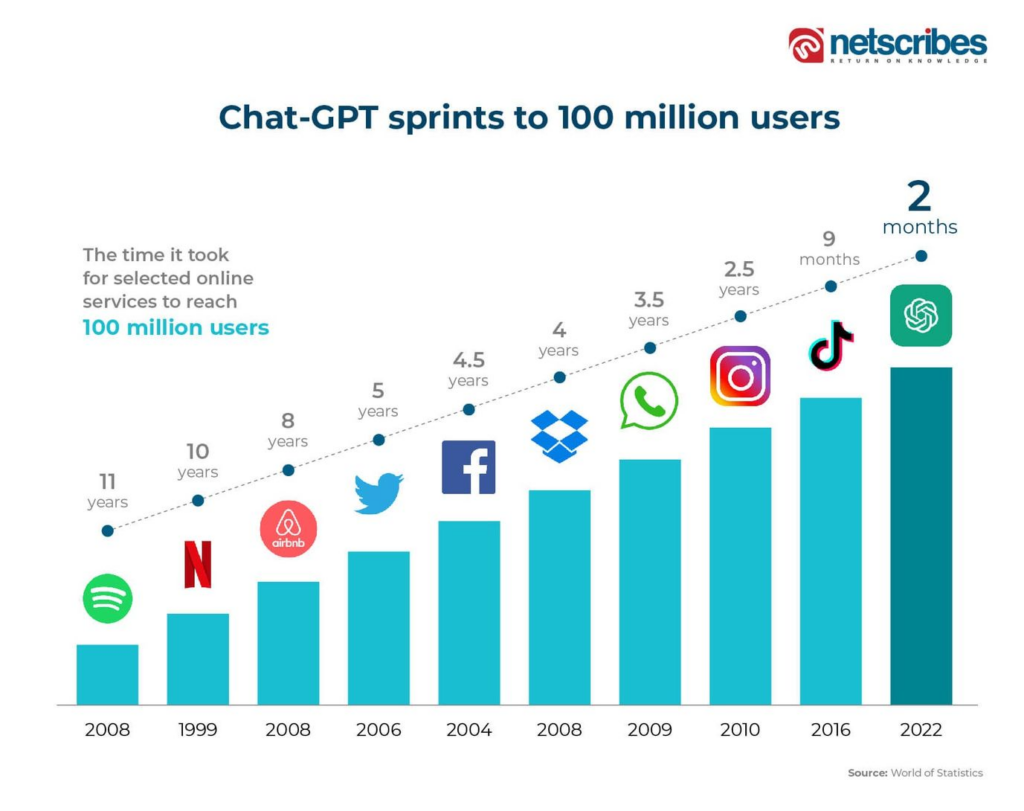
출처 : http://www.netscribes.com
2. 오픈소스 LLM의 등장
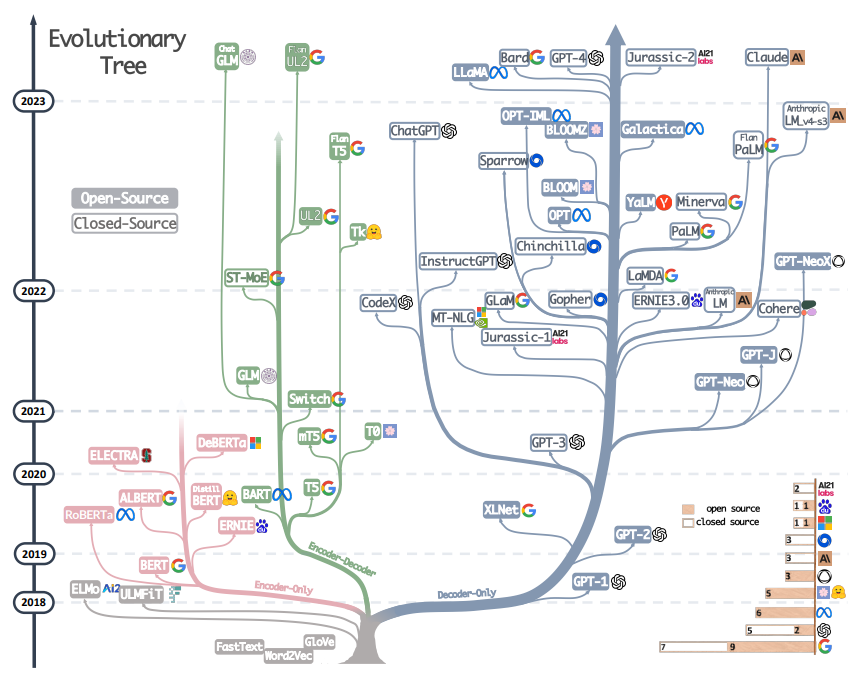
출처: https://arxiv.org/abs/2304.13712
2023년 상반기까지 LLM 기술은 Big-Tech League라고 할 정도로 LLM 기술의 진입장벽은 높았습니다. 수십, 수백억 개의 파라미터를 가진 Foundation 모델(=pretraind base model) 을 연구하고 만들기 위해선 천문학적인 학습 비용이 들 뿐만 아니라 모델 아키텍처나 학습 데이터의 세부정보 공개를 꺼려 했기 때문입니다.
그러나 Meta의 오픈 소스 LLM인 Llama의 등장으로 오픈소스 LLM 이 더욱 각광을 받고 있습니다. 이 오픈소스 LLM 은 작은 모델이 큰 모델과 경쟁할 수 있고, 적당한 양의 데이터로 모델을 Fine-tuning 함으로써 적은 예산과 컴퓨팅 연산으로 학습시킬 수 있게 되었습니다.
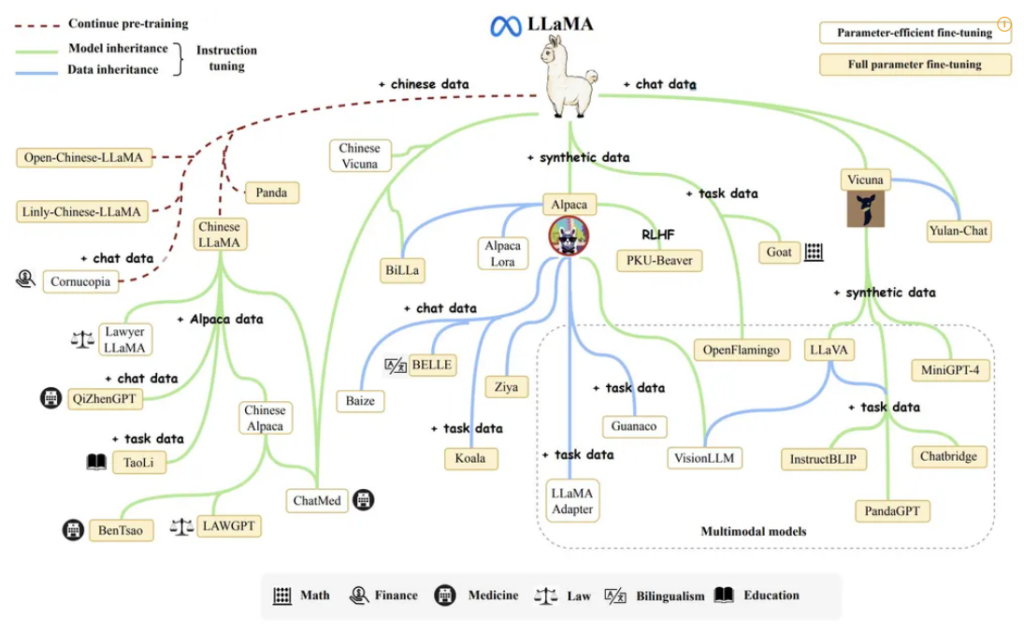
출처 : https://namu.wiki/w/LLaMA
3. LLM의 기술
한컴 AI 연구팀에서는 인공지능 논문들을 읽고 세미나를 통해 서로 이해한 정보를 공유하고 심도 있게 모델 아키텍처와 실험 연구를 분석한 후 여러 방법들을 고안해 내며 자체 테스트를 통해 성능 향상을 이끌어내고 있습니다.
지금부터는 인공지능 개발자들이 어떻게 LLM 기술을 다루는지 전반적인 지식들을 함께 이야기해 보고자 합니다.
A. Encoder – Decoder
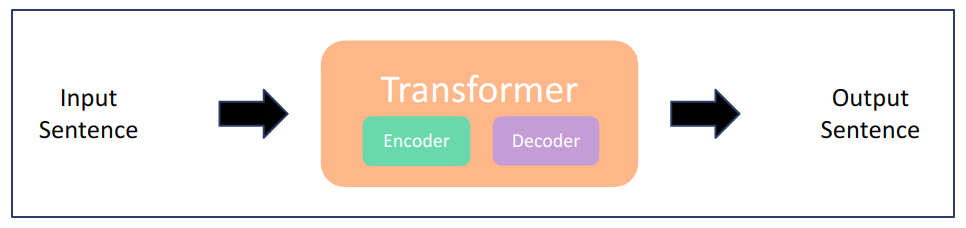
입력이 필요한 생성 Task (Transformer, Seq2Seq 모델)
- 번역 (Translation)
- 요약 (Summarization)
- 대화형 시스템 (Chatbot)
B. Encoder
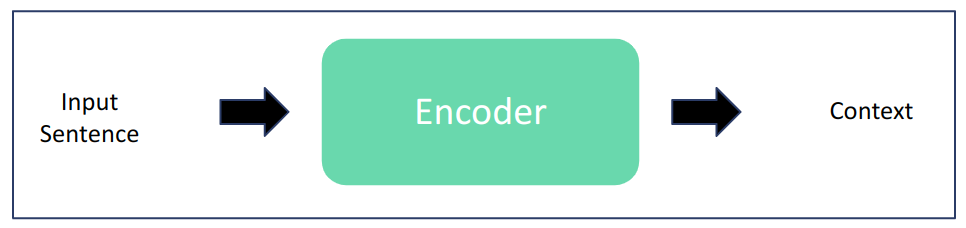
입력 데이터로부터 이해가 필요한 Task (BERT모델)
- 문장 분류 (classification)
- 개체명 인식 (NER : Named Entity Recognition)
- 질의응답 (QA : Question Answer)
C. Decoder
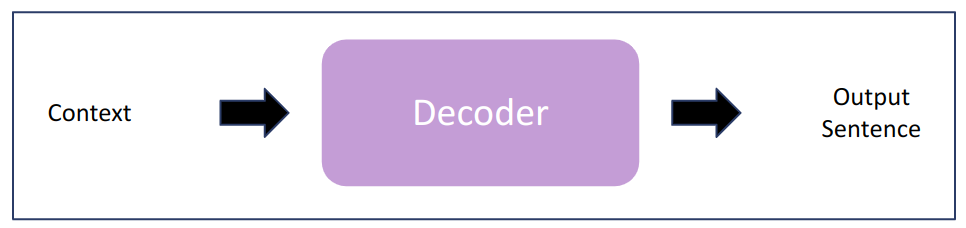
입력 데이터로부터 적절한 텍스트를 생성하는 Task (GPT 모델)
- 텍스트/이미지 생성 (generation)
Encoder, Decoder 모델들은 분명한 장단점들이 존재하며 프로젝트에 필요한 도메인에 따라 모델을 달리하여 개발을 진행해왔습니다.
Encoder 모델과 Decoder 모델은 각기 다른 길을 가며 영역을 넓혀왔습니다. Encoder 모델의 대표 모델은 BERT 모델로 BERT는 특정 Task를 해결할 수 있는 데이터만 있다면 이전 머신러닝으로 해결했던 방법보다 쉽고 빠르게 모델을 학습할 수 있게 했습니다. Encoder 기반의 모델 기술을 통해 우리는 많은 Task들을 자동화할 수 있었습니다. Decoder 모델의 GPT도 마찬가지로 생성에 특화된 모델을 파라미터 수와 아키텍처를 일부 변경하여 GPT2, GPT3 모델로 출시하며 나날이 발전해 왔습니다.
이 Encoder와 Decoder 모델의 학습 방식의 가장 큰 차이점은 데이터 처리에 있습니다. Encoder 모델에 필요한 데이터는 labeled dataset을 활용하였고 Decoder 모델은 unlabeled dataset을 활용하였습니다.

Labeled Dataset은 명확하게 정답을 제시하여 모델 학습을 할 수 있지만 label이 있는 데이터를 정제하거나 확보하는 것은 많은 비용이 듭니다.
Unlabeled Dataset은 데이터를 얻기는 쉽지만 광범위한 데이터를 통해 해당 데이터가 어떤 데이터인지 모델이 추론할 수 있도록 학습시켜야 합니다.
각 모델들은 학습 방식과 모델 아키텍처를 다르게 하면서 기존 모델의 한계를 극복하고 발전해 왔습니다. 특히, 2022년에 등장한 InstructGPT와 ChatGPT는 이러한 발전의 대표적인 사례 중 하나입니다. 이 모델들은 다양한 분야의 대용량 plain text corpus(말뭉치)를 학습시킨 모델로 Encoder의 문제해결 능력도 Decoder 모델이 충분히 잘할 수 있음을 보여주었고, 자연어 영역에서 거의 모든 Encoder Task를 대체할 수 있음을 입증했습니다.
LLM은 Decoder-Only 아키텍처뿐만 아니라 Encoder-Decoder 아키텍처도 적용 가능합니다.
LLM 모델은 각 아키텍처마다 학습 방식이 조금씩 다르지만 공통적으로 Block을 쌓아 학습을 진행하며 layer size, batch size, hidden size, attention Heads, token embedding 등의 값을 변형시켜 모델을 학습시킵니다.
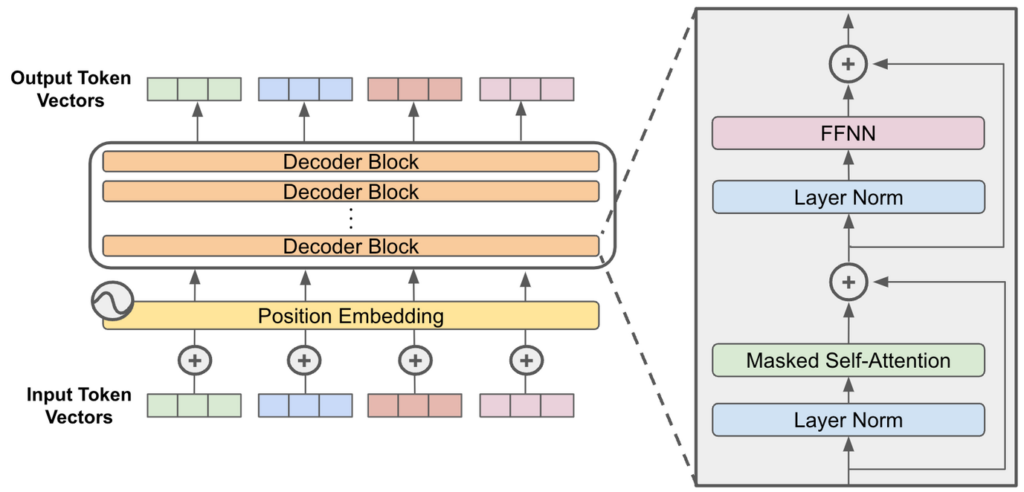
출처 : https://cameronrwolfe.substack.com/p/decoder-only-transformers-the-workhorse
3-2. LLM 학습
기본적으로 LLM 학습 기본 구성은 Pre-training, Fine-tuning, 프롬프트로 나눌 수 있습니다.
- Pre-training : 대용량 코퍼스를 학습시켜 자연어를 학습시키는 작업
- Fine-tuning : pretrained 모델을 의도에 맞는 학습 데이터를 사용하여 pre-training 모델을 미세조정
- 프롬프트: 최종 모델에 사용자가 원하는 형태의 출력을 얻기 위해, 모델이 사용자의 의도를 잘 파악할 수 있게 글을 잘 쓰는 방법
A. Pre-training
밑바닥부터 pre-training 용 학습 데이터를 구축하고 모델을 만드는 것은 현실적으로 어렵습니다. 그렇기 때문에 오픈소스 LLM이 각광받게 되었고 현재 공개된 pretrained LLM을 활용하는 방법이 많이 연구되고 있습니다.
보통 공개된 언어들은 영어 기반의 모델이기 때문에 한국어를 잘 이해하는 LLM을 만들기 위해 기존 pretrained LLM에 한국어 데이터를 추가 학습하는 방법을 사용합니다. 이러한 방식을 Adaptive Pre-training라고 합니다.


Adaptive Pre-training은 기존 모델에 특정 도메인을 추가로 pre-training 하는 방식으로 한국어 도메인을 추가하는 방식이라고 할 수 있습니다. 여기서 한국어 expansion 방식을 사용하여 Token 수를 줄이고 모델을 한국어 특성에 맞게 효율적으로 구성할 수도 있습니다.

출처 : https://arxiv.org/abs/2402.14714
영어 모델을 바로 한국어 학습 데이터로 Fine-tuning 하게 되면 token 수, 리소스 낭비가 되기도 하며 소형 LLM일수록 한국어 언어를 잘 이해하지 못할 수 있습니다.
이러한 단점을 보완하기 위해 Vocabulary Expansion 방식을 적용한다면 token을 줄여 더 긴 문장을 생성할 수 있으며 Fine-tuning 시 한국어를 더 잘 이해시킬 수 있습니다.
B. Fine-tuning
Fine-tuning은 말 그대로 pretrained 모델을 미세조정하는 방식입니다. 이 방식은 원하는 도메인을 추가 학습시킴으로써 비교적 적은 양의 데이터로도 빠르게 정확한 모델을 만들 수 있습니다.
Fine-tuning은 labeled dataset을 사용하여 모델의 가중치를 조정함으로써 특정 작업의 성능을 향상시킵니다. 그렇기 때문에 데이터 셋의 선택은 매우 중요하며 요약이나 번역과 같은 데이터 셋을 Fine-tuning 하게 되면 특정 작업에 맞게 조정되고 Inference(모델 연산) 결과는 Fine-tuning에 치중될 수밖에 없습니다.
Fine-tuning을 진행하는 방식에는 크게 2가지 방식이 있습니다.
- Full Fine-tuning
- 모든 모델 가중치를 업데이트하여 향상된 기능을 갖춘 새로운 버전의 LLM을 만듭니다.
- 계산 시에 Gradient, Optimizer 등의 추가 요소들을 계산해야 되기 때문에 많은 컴퓨팅 리소스가 필요합니다.
- Fine-tuning 용 학습 데이터가 적으면 학습효과가 부족하고, 적은 데이터 셋에 의해 overfitting 될 가능성이 높습니다.
- PEFT(Parameter Efficient Fine-tuning)
- PEFT는 파라미터의 일부만 업데이트하고 나머지 부분은 Freeze 하기 때문에 Full Fine-tuning 보다 적은 리소스로 효율적으로 weight을 미세조정할 수 있습니다.
- 일부만 미세조정을 하면 Training 가능한 파라미터가 줄어들고 원래 LLM의 weight을 유지하여 이전에 학습된 정보의 손실을 방지합니다.
- 여러 가지 방법이 있지만 Low-Rank Adaptation (LoRA or QLoRA) 이 가장 좋은 성능을 내는 것으로 알려져있습니다.
Fine-tuning은 4가지 동작 방식으로 학습합니다.
- Forward Pass : 네트워크를 통해 입력 데이터를 전달하여 예측 데이터들을 계산합니다.
- Loss : 예측값과 원하는 값(ground-truth)을 비교하여 Loss 나 오류의 측정값을 구합니다.
- Backward Pass : 네트워크를 통해 역방향으로 작동하여 Weight 과 bias에 대한 손실 기울기(gradient of the loss)를 계산합니다.
- Update Weights : 기울기(gradient)의 반대 방향으로 Weight과 bias를 미세조정합니다.
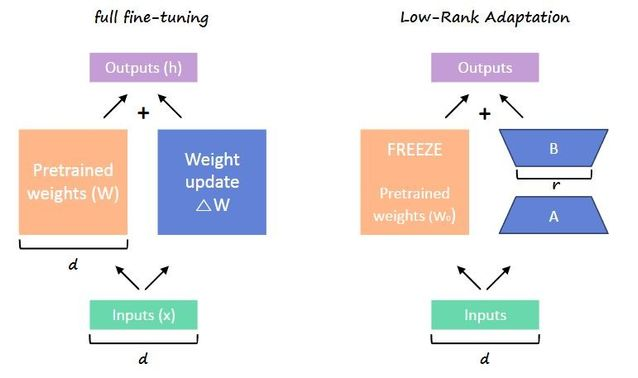
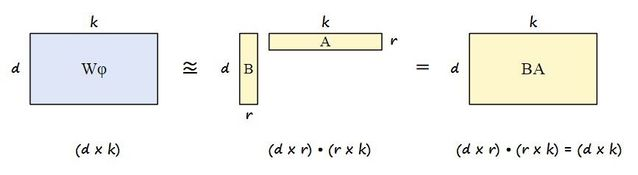
LoRA는 사전 학습된 대규모 언어 모델의 가중치 행렬을 구성하는 모든 가중치를 미세 조정하는 대신 이 큰 행렬에 근사하는 두 개의 작은 행렬을 미세 조정하는 개선된 미세 조정 방법입니다.
LoRA matrix와 같은 행렬이 LoRA 어댑터를 구성합니다. 그런 다음 이 미세 조정된 어댑터는 사전 학습된 모델에 로드되어 추론에 사용됩니다.
QLoRA는 LoRA와 유사한 효율성을 유지하면서 사전 학습된 모델이 양자화된 4비트 가중치(LoRA는 8비트)로 GPU 메모리에 로드되는 훨씬 더 메모리 효율적인 LoRA 버전입니다.
QLoRA는 LoRA와 비교하고 가장 빠른 학습 시간으로 최적의 성능을 달성하기 위한 QLoRA hyperparameter의 최적의 조합을 찾는 것이 핵심입니다
C. 프롬프트
프롬프트는 LLM을 사용하여 일반적으로 특정 작업을 위해 특정 형식의 질문이나 프롬프트를 제공하는 것을 의미합니다.
프롬프트를 생성하는 프롬프트 엔지니어링은 모델에게 원하는 작업을 수행하도록 유도하고 지시하여 결과물의 품질을 높일 수 있는 입력값들의 조합을 찾는 작업을 수행하는 것입니다.
LLM의 성능은 프롬프트의 퀄리티에 의해 크게 좌우되며, 입력값이 조금만 달라져도 완전히 다른 결과물을 생성할 수 있어 의도한 대로 결과가 잘 나오는지 테스트하고 확인하는 작업이 필수입니다.
프롬프트의 구성요소는 4가지로 구분할 수 있습니다.
- Instruction : 모델이 수행해야 하는 특정 작업이나 지시사항을 입력합니다.
- Context : 모델이 더 나은 답변을 할 수 있도록 유도하는 외부 정보나 추가 내용을 포함합니다.
- Input : 답을 구하고자 하는 질문을 입력합니다.
- Output : 결과물의 유형이나 형식을 나타내는 요소를 말합니다.
프롬프트에도 여러 가지의 방식이 존재하며 zero-shot, one-shot, few-shot Prompting 방식이 있습니다.
1. Zero-Shot Prompting
Zero-Shot Prompting은 모델에게 예제없이 질문이나 요청을 하는 기법입니다. 이 기법에서는 모델이 사전에 학습한 데이터와 지식을 바탕으로 주어진 문제를 해결하려고 시도합니다.
예를 들어, 사용자가 “겨울에 여행하기 좋은 곳을 소개해 주세요.”라고 입력하면, 모델은 다음과 같이 겨울에 여행하기 좋은 곳을 소개해 줍니다.
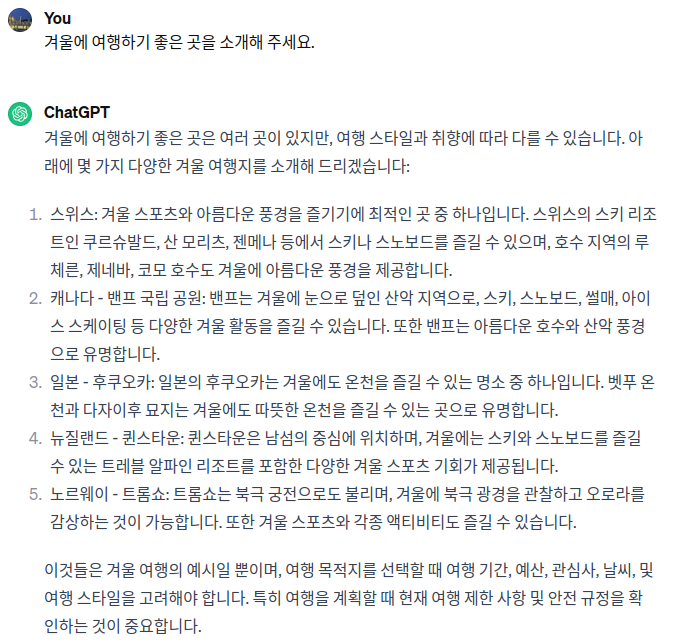
Zero-Shot Prompting을 사용하여 원하는 답변을 얻으려면, 위와 같은 단순한 프롬프트보다는 구체적인 요청 내용이나 형식 등이 추가된 프롬프트가 좋습니다.
다음의 프롬프트에는 대상, 범위, 형식 등을 추가로 지정해 주었습니다.
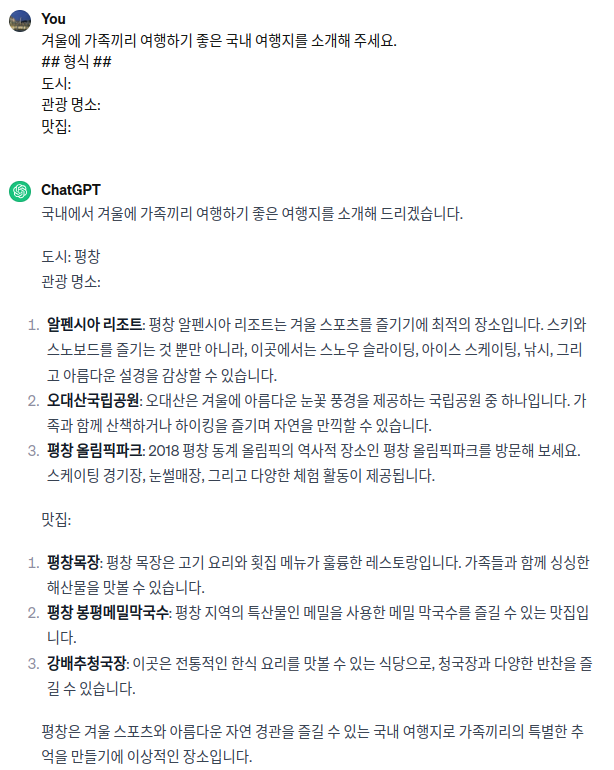
2. One-Shot Prompting
One-Shot Prompting은 모델에 하나의 예시를 포함하여 입력을 제공하는 기법입니다. 모델에게 작업 예시를 보여주고, 그다음에 비슷한 유형의 작업을 지시합니다.
예를 들어, 질문-답변 쌍을 제시한 후 새로운 질문에 대한 답변을 요청할 수 있습니다.

이전에서 소개한 Zero-Shot Prompting을 사용했을 때, 형식이나 요청 내용을 구체적으로 입력했음에도 때때로 원하는 답변을 얻지 못하는 경우가 발생합니다. 모델은 두 가지 이상의 Task, 또는 모호한 지시문이 있는 경우 사용자가 원하는 답변을 얻기 어렵습니다. 이런 경우 생성할 답변의 구성을 사전에 알려주는 One-Shot Prompting을 사용하는 것이 좋습니다.
3. Few-Shot Prompting
Few-Shot-Prompting은 여러 개의 예시를 포함하여 모델에 입력을 제공하는 기법입니다.
두 개 이상의 예시를 보여줌으로써 모델이 제공된 예시에서 문맥과 패턴을 학습하고(learning), 새로운 입력에 대해 비슷한 방식으로 결과를 생성합니다.

Few-Shot Prompting은 두 가지 이상의 복잡한 작업의 정확도를 높이는 데 탁월합니다. 조건이나 제한 사항이 필요할 때도 Few-Shot Prompting을 사용하면 더 좋은 결과물을 얻을 확률이 높습니다.
위의 예시에서 문장의 개수를 3개 미만으로 지시하고, 예시 문장에서도 동일하게 2개 또는 3개의 문장을 구성하였습니다. 이렇게 구체적인 설정과 예시를 제공하면 모델이 작업 내용을 이해하는 데 도움을 줍니다.
4. CoT(Chain-of-Thought) Prompting
추가로 프롬프트 기법에서 사용할 수 있는 방법으로 CoT 기법이 있습니다. CoT Prompting은 복잡한 문제를 해결하기 위해서 풀이 과정이나 추론 과정을 모델에게 제시하는 기법입니다. 모델이 단순히 최종 답을 제시하는 것이 아니라, 문제를 해결하기 위한 논리적인 단계나 추론 과정을 차례대로 기술하도록 합니다. 복잡한 수학 문제나 추론이 필요한 질문에 대해 다른 기법보다 더 정확하고 논리적인 답변을 제공합니다. 문제의 난이도, 복잡도에 따라 예시를 1~5개 정도 제시해 줍니다.
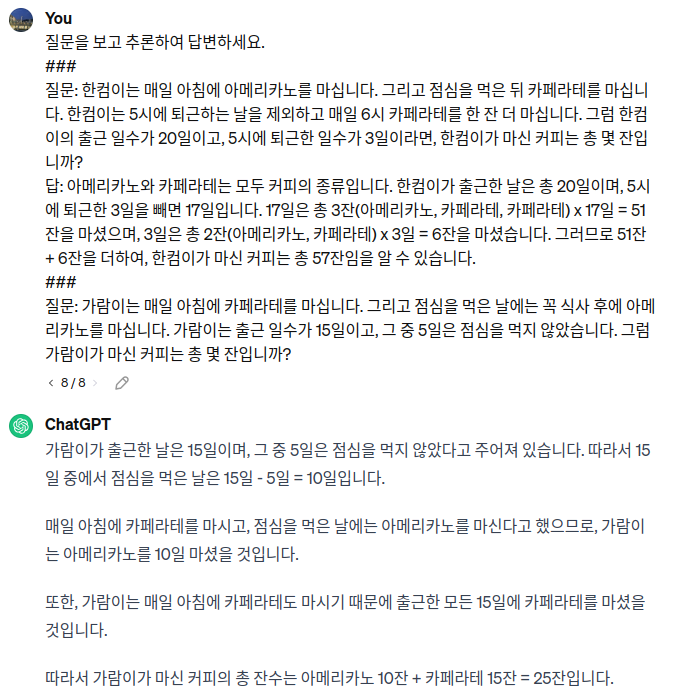
입력에서 추론 예시를 제시하지는 않으나, “단계별로 천천히 생각해 보세요.”라는 Magic word 프롬프트로 모델이 추론 과정을 거치도록 유도할 수 있습니다.
위의 기법과 비교하여 정답률이 떨어질 수 있으나, 예시를 생성하지 않아도 되기 때문에 시간과 비용을 줄일 수 있습니다. 이렇게 Magic word를 사용하여 추론을 유도하는 기법을 ‘Zero-Shot CoT Prompting’이라고 명명하기도 합니다.

이 방식은 질문에 모호한 단어나 문장이 포함되거나, 좀 더 복잡한 계산이 필요한 경우에는 추론 성능이 저하되므로 주의가 필요합니다.
4. 결론
LLM의 성능을 높이기 위해선 여러 복합적인 방법들이 동원되어야 하고 정해진 답이 없기 때문에 많은 연구와 실험이 필요한 분야입니다. 그러나 성능에만 초점을 맞춰 개발하다 보면 다른 문제에 직면할 수도 있습니다.
LLM 기술에서 주의해야 할 점이 몇 가지 있는데 개인정보 보호, 편향성, 윤리적 문제 등의 이슈는 여전히 해결되어야 할 과제입니다. 다양한 LLM들의 발전은 우리에게 무한한 가능성을 제시하면서도 동시에 책임 있는 사용과 연구의 중요성을 강조하고 있습니다.
기술의 발전을 긍정적으로 바라봄과 동시에 적절한 규제와 윤리적인 문제 해결을 위한 노력이 필요함을 우리는 인식하고 있어야 합니다.
마치며
지금까지 LLM의 발전과 모델 학습 방식에 대해 설명해 왔습니다.
내용이 조금 어려울 수도 있지만 모델 학습 내용을 잘 모르셨거나 궁금해하신 분들에게 많은 도움이 되셨길 바랍니다.
모든 분들이 전반적인 LLM 개념을 이해하고 함께 소통할 수 있는 날이 오기를 바라며 저는 이만 글을 마무리하도록 하겠습니다.
감사합니다.
Reference
- http://www.netscribes.com
- https://arxiv.org/abs/2304.13712
- https://namu.wiki/w/LLaMA
- https://cameronrwolfe.substack.com/p/decoder-only-transformers-the-workhorse
- https://arxiv.org/abs/2402.14714
- https://arxiv.org/abs/2106.09685
- https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
- https://medium.com/@alexmriggio/lora-low-rank-adaptation-from-scratch-code-and-theory-f31509106650
- https://openai.com/