안녕하세요, 한글과컴퓨터에서 웹 프론트엔드 개발을 맡고 있는 7년 차 개발자 이나안입니다 😎
신규 프로젝트를 맡게 되면 SSR(Server-Side Rendering)을 활용할지부터 고민하게 되는 요즘입니다. SSR을 기본 렌더링 방식으로 채택한 Next.js의 인기가 날로 높아지고 있는 데다가 CSR(Client-Side Rendering) 프레임워크의 대표주자인 React에서도 SSR을 손쉽게 구현할 수 있게 되면서 더욱 그렇습니다.
한편, SEO(Search Engine Optimization; 검색 엔진 최적화)에 대한 요구도 최근 부쩍 늘었습니다. 마케팅 비용이 적게 책정된 프로젝트일수록 이러한 경향이 두드러지는데, 아무래도 별도의 광고 없이도 검색 엔진을 통해 자연스러운 유입 트래픽을 확보할 수 있다는 점이 크게 작용하는 것으로 보입니다.
이 글을 통해 저는 그간 다양한 프로젝트에 SSR과 SEO를 적용하며 얻은 경험과 배운 점을 나누고자 합니다. SSR을 도입해야 하는지, SEO를 잘하고 있는지 의구심을 갖고 계셨다면 이 글이 그러한 의구심을 해소되는 계기가 되면 좋겠습니다 🙂
SEO 개념 잡기
검색 엔진의 동작 원리
검색 엔진이 우리의 웹 사이트를 검색 결과로 표현하기까지 1. 크롤링 → 2. 인덱싱 → 3. 랭킹이라는 보이지 않는 세 단계가 필요합니다.

출처 – DALL·E 3에게 ‘검색 엔진이 웹 사이트를 크롤링, 인덱싱, 랭킹하는 일련의 과정을 하나의 이미지로 표현해줘’ 라고 명령했을때 출력된 그림
(1) 크롤링 (crawling)
검색 엔진들은 웹 크롤러(혹은 스파이더)라고 불리는 일종의 봇을 운영하고 있습니다. 웹 크롤러들은 인터넷 세상을 돌아다니며 검색 결과로 표현할 웹 사이트들의 페이지 데이터를 수집합니다. 이러한 수집 행위를 크롤링이라고 합니다.
(2) 인덱싱 (Indexing)
크롤링 된 데이터들은 검색 엔진 내에서 검색 결과로 노출할 수 있는 형태로 분류하고 저장됩니다. 이를 인덱싱이라고 합니다.
(3) 랭킹 (ranking)
인덱싱된 데이터들에는 키워드 관련성과 사이트 신뢰도 등을 토대로 우선순위가 매겨집니다. 이를 랭킹이라고 합니다. 우선순위가 높을수록 검색 결과상에서 더 위에, 더 많이 노출됩니다.
SEO란?
SEO는 결국 크롤링-인덱싱-랭킹이 잘 이뤄지도록, 그러니까 검색 엔진이 내 웹 사이트를 잘 수집하고 잘 저장해서 높은 우선순위를 매길 수 있도록 웹 사이트에 취하는 모든 조치를 의미합니다. 이렇게 SEO가 잘 이뤄진 웹 사이트는 일명 ‘상위 노출’ 됩니다.
여기서 핵심은 SEO 전략을 짜는 데 있어서 크롤링-인덱싱-랭킹 각각에 다른 접근 방식이 필요하다는 겁니다.
예컨대, 잘 크롤링-인덱싱되는 데는 크롤러가 웹 사이트에 방문했을 때 페이지가 잘 준비되어 있고, 페이지의 구조가 표준적이며, 크롤러가 수집하는 요소들을 빼먹지 않고 채워두는 것이 중요합니다.
하지만 잘 랭킹 되는 데에는 훨씬 더 복잡한 전략이 필요합니다. 우선은 웹 페이지 내에서 핵심 키워드가 적절히 위치하고 적당히 분포되어 있어야 하고요, 무엇보다도 우리 사이트를 사람들이 좋아하고, 자주 방문하게 할 만한 요소를 갖추는 것이 중요합니다.
이에 대한 좀 더 자세한 내용은 뒤에서 다시 다루도록 하겠습니다.
CSR vs SSR
CSR과 SSR 사이엔 여러 차이점이 있지만, 일단은 딱 한 가지만 보면 됩니다.
| CSR | SSR |
|---|---|
| 클라이언트는 일단 빈 HTML을 전달받고, 동적으로 스크립트를 실행해 부분별로 렌더링한다. → 동적 콘텐츠가 클라이언트 상에서 채워진다. | 클라이언트는 완성된 HTML을 전달받고, 전체를 한 번에 렌더링한다. → 동적 콘텐츠가 서버상에서 채워진다. |
이게 어떤 결과로 나타나는지 자세히 살펴보면요,




CSR에서는 데이터 요청을 처리하는 주체가 클라이언트이기 때문에 초기 HTML에 콘텐츠가 삽입되어 있지 않습니다. 즉, CSR에서 초기 HTML은 그저 껍데기입니다.



반면 SSR에서는 서버에서 필요한 데이터를 가져와 HTML에 포함해 클라이언트로 전송하기 때문에 초기 HTML에 이미 콘텐츠가 포함되어 있습니다. 초기 HTML이 이미 완성된 HTML인 셈이죠.
CSR이 SEO에 불리하다고 말하는 지점이 바로 여기입니다. CSR 페이지에 크롤러가 방문했을 때 준비된 것은 그저 빈 껍데기이기 때문입니다.



자바스크립트를 지원하는 크롤러
현재 웹 생태계를 꽉 잡은 React, Vue, Angular는 SPA(Single page application) 프레임워크/라이브러리입니다. SPA와 CSR이 동의어는 아니지만 SPA를 위해서는 CSR이 필수인 만큼 CSR 방식으로 동작하는 웹 사이트들이 지난 몇 년간 쏟아져 나왔습니다.
비록 SEO 관점에서는 CSR이 불리한 면이 있었지만 사용자 경험 등 CSR의 장점도 분명했기 때문에, 검색 엔진들은 CSR 방식으로 동작하는 페이지에 대해서도 크롤링을 지원해야 하는가를 두고 고심했을 겁니다.
CSR 방식의 페이지를 크롤링하는 방법은 의외로 쉽습니다. 최초에 빈 HTML을 전달받았더라도 실제 클라이언트처럼 동적으로 스크립트들을 호출하고 그 결과를 받아 HTML을 재구성한 뒤 그 재구성된 결과를 수집하면 됩니다.
실제로 이를 위해 자바스크립트 엔진이 내장된 크롤러가 등장했습니다. 동적으로 렌더링 되는 콘텐츠를 처리하기 위해 브라우저를 모방하여 자바스크립트를 실행하는 차원까지 진화한 겁니다.
“사실 말만 쉬웠습니다.”
문제는 이 과정에 요구되는 컴퓨팅 파워였습니다. CSR 페이지를 하나 크롤링할 때마다 소모되는 자원이 너무 많았습니다. 대규모 크롤링을 해야 하는 검색 엔진 입장에선 그 부담이 더욱 컸으리라 예상이 가능한 부분입니다. 그 정도 컴퓨팅 파워를 가진 기업이 흔치는 않다 보니 어쨌거나 현재 자바스크립트를 지원하는 크롤러를 운용하는 검색 엔진은 구글과 빙, 그리고 네이버 정도입니다.
그래도 주요 검색 엔진에선 전부 지원하는 셈이니 CSR이라고 해서 크롤링이 안 되는 건 아니라고 볼 수 있습니다.
한계
하지만 자바스크립트를 지원하는 크롤러가 만능 해결책은 아닙니다. 이 크롤러들은 스크립트가 모두 실행되기를 마냥 기다려 주진 않습니다. 예를 들어 스피너(spinner)나 프로그래스바(progressbar)가 출력되더라도 일단 준비가 된 것으로 인식해 버립니다.

자바스크립트를 지원하는 크롤러를 운용하는 검색 엔진이 몇 되지 않는다는 점도 문제입니다. 구글과 빙, 네이버만 신경 써도 된다면 CSR이라도 큰 문제가 없을 수 있지만 예를 들어 만약 중국향 웹 사이트를 개발하는 입장이라면 어떨까요? 😱 (중국의 경우 바이두의 점유율이 70%에 육박하며, 바이두의 크롤러는 자바스크립트를 지원하지 않습니다.)
말, 말, 말
구글의 입장 변화
구글의 경우, 2018년에 자바스크립트를 지원하는 크롤러를 야심 차게 발표한 이후 입장이 한 번 바뀌었습니다.
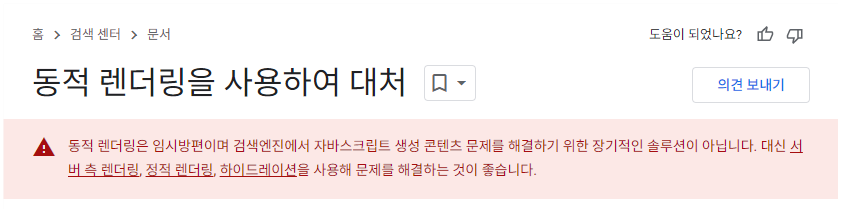
구글 SEO 가이드 문서의 위 경고 문구는 2022년에 추가가 되었는데요, 구글은 SEO 측면에서 CSR을 권장하지 않으며 다른 선택의 여지가 없는 경우에만 아래 가이드를 따르라는 내용입니다. 경고 문구가 없던 시절에는 CSR로도 아무 문제가 없어 보였던 것과 대조적으로 느껴지는 부분입니다.
네이버 SEO 가이드

네이버의 SEO 가이드 문서에는 좀 더 구체적인 이유가 명시되어 있습니다. 요약하면 CSR이라고 해서 크롤링이 안 되는 건 아니지만 크롤링 효율 면에서는 SSR이 낫기 때문에 주요 콘텐츠는 SSR로 렌더링할 것을 권장한다는 겁니다.
구글 SEO 전문가 존 뮬러(John Mueller)의 조언
- English Google SEO office-hours from December 17, 2021
- (구글은) 크롤링하는 모든 페이지를 기본적으로 렌더링하여 수집합니다.
- 저라면 Google만을 위해 많은 인프라를 설정하는 상황을 피하려고 노력할 겁니다.
- SSR로 전환을 고려하고 있다면 사용자에게도 유리한 방식으로 해야 합니다. SSR로 전환하면서 속도가 크게 향상되는 때도 있기 때문입니다.
- Case studies? Dynamic Rendering versus Server Side Rendering
- (구글에) 웹 사이트가 어느 방식으로 구현되어 있느냐에 따른 SEO 우선순위 보너스는 없습니다.
- CSR에서 다른 방식으로 서둘러 전환할 필요는 없습니다. CSR이 당장 구글에 문제를 일으키거나 조만간 지원되지 않게 되는 것은 아닙니다.
- 그러나 사이트를 재구축할 생각이라면 다른 방식(CSR 외에)을 사용하는 게 좋습니다.
결론
원론적으론 콘텐츠를 비동기적으로 가져와야 하는 상황에서 콘텐츠의 내용도 크롤러가 수집해 가길 원한다면, 답은 SSR이 맞는 것으로 보입니다.
물론 검색 엔진을 구글, 빙, 네이버 정도로 한정한다면 CSR이어도 큰 문제는 없습니다.
“하지만 위의 ‘말, 말, 말’이 신경 쓰인다면… 결국 SSR입니다.”
어디까지나 SEO에 있어서의 유불리를 따진 것이기 때문에 특정 방식이 나머지 방식에 비해 나쁜 기술인 것은 절대 아닙니다. CSR에는 CSR만의 장점이, SSR에는 SSR만의 장점이 있습니다. 게다가 이 글에서는 CSR과 SSR을 SPA(Single Page Application)와 MPA(Multiple Page Application) 수준으로 구분해서 다루고 있지만 실제로 SSR과 CSR은 함께 사용되는 경우가 많습니다.
✅ 체크포인트 : SEO가 늘 그렇게 중요할까?
상업적인 목적을 가진 웹 사이트라면 SEO를 완전히 무시할 수는 없습니다. 그렇다고 해서 모든 상업 사이트가 SSR로만 구현되어야 할 정도로 SEO가 중요하냐면 그건 아닙니다.
여태까지의 내용 중에서 한 가지 간과된 부분이 있다면, 바로 웹 사이트의 성격을 꼽을 수 있습니다. 웹 사이트에 따라 검색 엔진에 노출되고자 하는 방식이 크게 다르며, 이 점은 SEO를 어디까지 다뤄야 하느냐를 결정하는 일에 있어 중요한 차이를 만들어 냅니다.
예를 들어 [한컴독스]의 경우 콘텐츠 영역에 포함된 단어들이 검색 엔진에 노출될 필요성이 크지 않은 데다가 대부분 페이지가 회원 전용 콘텐츠로 이뤄져 있습니다. 이 경우 콘텐츠에 대한 SEO 보다는 [한글과컴퓨터]와 [한컴독스]라는 브랜드, ‘AI’라는 키워드를 통한 검색 유입과 직접 트래픽에 집중하는 것이 나을 수 있습니다.
그래서, SEO를 “잘” 하려면?
우선 짚고 넘어가야 할 게, 각 검색 엔진들이 ‘상위 노출’을 선정하는 기준은 명확하지 않습니다. 검색 엔진들이 기준이나 알고리즘을 공개하지도 않을뿐더러, 검색 엔진마다 각자 다른 비중으로 기준을 세우고 우선순위를 매기기 때문입니다. 따라서 SEO에 정답은 알 수 없으며, 하나의 검색 엔진에서 효과적이었던 전략이 다른 검색 엔진에서도 효과적일 것이라는 보장도 없습니다.
그래도 늘 ‘일반적’이라는 게 있듯이 대체로 많이들 취하는 조치들이 있어서, 그에 대해서 적어보겠습니다.
검색 엔진 제어 최적화 전략
- 크롤링 검색 엔진에 사이트를 등록합니다.
- 각 검색 엔진들은 사이트 등록 페이지를 운영합니다. 여기에 URL을 입력함으로써 새로운 사이트가 생성되었음을 검색 엔진에 알려줄 수 있습니다. 등록된 사이트는 1~2일 이내에 검색 결과로 노출됩니다.
- 사이트 등록을 하지 않는다고 해서 크롤러가 방문하지 않는 것은 아닙니다. 다만 이 경우 언제 수집을 해갈지 확실하지 않습니다.
- 사이트가 더 이상 검색 결과에 노출되지 않도록 삭제 요청할 수도 있습니다.
- 크롤링 robots.txt 및 사이트맵을 설정합니다.
- robots.txt와 사이트맵은 크롤러에 사이트 내에서 어디로 가야 하는지, 어떤 것들을 수집해야 하는지, 어느 주기로 들러주면 좋은지를 알려주는 가이드입니다.
- 기본 중의 기본이다 보니 자동화 도구들도 많이 존재합니다.
- 아직 작업 중이거나 오픈 대기 상태인 사이트의 경우 robots.txt를 이용해 크롤러의 접근을 차단해 줘야 합니다.
- 크롤링 캐노니컬(canonical) 태그를 정의합니다.
- 어떤 페이지에 접근할 수 있는 URL이 여러 개인 경우, 크롤러가 이 모든 URL을 각각의 페이지로 인식하지 않고 같은 페이지로 인식할 수 있게끔 이 페이지의 대표 URL을 알려주어야 합니다.
- 한 페이지를 모바일 버전과 PC 버전으로 나누어 구현했다면, 예를 들어
m.로 시작하는 페이지가 별개의 페이지로 인식되지 않도록 캐노니컬 태그를 정의해 주어야 합니다. - 이 작업은 마지막에 고려될 만한 작업입니다. 캐노니컬 태그를 너무 많이 정의하거나 잘못 정의하면 스팸성으로 간주할 수 있습니다.
- 크롤링 브로큰 링크(broken link)에 대비합니다.
- 사이트를 운영하다 보면 페이지가 사라졌거나 오류가 발생하여 제공할 수 있는 게 없을 때가 있습니다. 사이트 신뢰도를 유지하려면 이런 때에 곧장 다른 페이지로 리디렉션 시켜주거나 홈 버튼, 사이트맵 등 이 상황에서 벗어나는 방법을 제공하는 자체 오류 페이지를 제공해 주어야 합니다.
- 크롤링 사이트 오류나 리디렉션이 자주 발생하지 않도록 합니다.
- 크롤러가 특정 페이지에 방문했을 때 간헐적으로 반환된 오류 페이지는 크게 문제가 되지 않습니다. 하지만 지속해서 오류 페이지가 반환되었을 때는 검색 엔진은 해당 페이지를 인덱스에서 삭제합니다.
- 크롤러는 콘텐츠가 있는지 없는지가 아니라 어떤 상태 코드를 전달받았는지로 사이트의 상태를 판단합니다. 사이트 접속에 문제가 되지 않는 일부 오류를 페이지 전체의 상태 코드에 반영하는 실수를 범하지 않도록 주의해야 합니다.
- 적절한 리디렉션은 크롤러를 올바른 페이지로 이끌지만, 잦은 리디렉션은 스팸성으로 간주할 수도 있습니다.
- 크롤링 표준적인 구조와 시맨틱 태그를 사용합니다.
- <header>, <main>, <footer>와 같은 시맨틱 태그들은 검색 엔진이 좀 더 정확하게 페이지의 구조를 파악하여 중요도에 따라 데이터를 분류할 수 있도록 해줍니다.
- 이미지 요소는 <img> 태그를 사용하여 표현되어야 합니다. 예를 들어 <div style=”background-image:url(puppy.jpg)”> 형태로 표현된 이미지 파일은 인덱싱되지 않습니다.
- A와 B 두 사이트가 같은 키워드를 가지고 있을 때, A 사이트에서는 <h1> 태그 내에 키워드를 가지고 있고, B 사이트는 <p style=”font-weight: bold; font-size:larger;”> 태그 내에 키워드를 가지고 있다면 검색 엔진은 A 사이트에 더 높은 우선순위를 매깁니다.
- 구글은 <h1> 등의 title 태그들을 페이지의 내용을 요약할 때도 사용합니다. 이렇게 요약된 내용은 메타데이터에 정의된 description과는 별개로 검색 결과에 노출됩니다.

“title 태그를 잘 쓰면 목차 형태로 요약됩니다.”

키워드 관련성 최적화 전략
- 크롤링 타이틀 태그와 메타데이터를 설정합니다.
- 이 페이지가 어떤 내용을 담고 있는지를 알려주기 위한 또 다른 기본 중의 기본 작업입니다. 검색 엔진이 타겟 키워드(검색어)를 탐색하는 일차적인 위치가 바로 이 영역입니다.
메타데이터 중 keywords를 정의해야 하는지 아닌지에 대해 늘 의견이 분분한 것 같습니다. 명백한 사실은 현시대의 keywords는 검색 엔진들에 있어서 전혀 중요한 정보가 아니라는 겁니다. 잘못 정의된 keywords에 의해 스팸성 페이지로 취급될 수도 있고, 경쟁사에 우리의 키워드 전략을 노출하는 결과를 낳을 수도 있다는 걸 생각해 보면 정의하지 않는 편이 정말 더 나은 선택일 수 있습니다.
- 크롤링 이미지 파일의 이름과 대체 텍스트(alt)로 이미지를 설명합니다.
- 파일 이름의 띄어쓰기는 하이픈(-)으로 대체하는 게 좋습니다.
- 대체 텍스트는 구체적으로 작성되어야 하지만 불필요한 키워드가 존재하거나 키워드가 반복되는 경우 스팸성으로 간주할 수 있습니다.
Bad
<img src="img.jpg" />
<img src=”ai.jpg" alt=”AI” />
<img src="crawler.jpg" alt=”한컴독스 AI 대단해 인스타그램 페이스북” />Good
<img src=”hanocomdocs-ai-logo.jpg" alt=”한컴독스 AI 로고” />
<img src="crawler.jpg" alt="페이지를 수집하는 크롤러" />
URL 최적화 전략
- 랭킹 대표 주소를 설정합니다.
- 인증서 발급 여부(http/https),
www.유무, 도메인 이전 등을 이유로 사이트 URL이 여러 개가 될 수 있지만 어느 쪽으로 접속하더라도 한쪽으로 리디렉션될 수 있도록 해야 도메인 점수가 분산되지 않습니다. - 대표 주소는 https 프로토콜을 사용하고,
.com도메인을 사용하여 신뢰도를 갖춘 쪽으로 설정하는 것이 좋습니다.
- 인증서 발급 여부(http/https),
Good
http://hancomdocs.com (접속 O)
http://www.hancomdocs.com (접속 O)
https://hancomdocs.com (접속 O)
https://www.hancomdocs.com (접속 O)
- 랭킹 도메인은 메인 키워드를, 서브 도메인과 서브 패스(서브 폴더)는 콘텐츠 내용을 포함합니다.
- 서브 패스의 띄어쓰기는 하이픈(-)으로 대체하는 게 좋습니다.
- 타겟 키워드(검색어)가 도메인에 포함되어 있으면 우선순위 산정에 유리합니다.
- 사용자 관점에서는 URL을 통해 어디로 이동되는지를 쉽게 알 수 있어 클릭 거부감이 줄어듭니다.
메인 도메인과 서브 도메인은 별개의 도메인으로 인식되어 도메인 점수가 분산되므로 서브 도메인을 설정하기 이전에 서브 패스(서브 폴더)를 먼저 고려해 보는 게 좋습니다.
(ex. https://www.ko.hancomdocs.com/ → https://www.hancomdocs.com/ko/ )
- 랭킹 전체 URL이 너무 길어지지 않도록 합니다.
- 너무 긴 URL은 인덱싱 대상에서 제외되기도 합니다.
- 특히 서브 패스에 콘텐츠 내용을 포함하려는 경우 패스가 너무 길어져 오히려 단점이 되지 않도록 주의해야 합니다.
- URL 단축 서비스를 사용해서 짧은 URL을 생성할 수도 있지만 브랜딩 효과가 저해될 수 있으며, 외부 서비스를 사용하는 경우 서비스가 종료되면서 생성한 단축 URL이 만료되어 버릴 수도 있습니다.
- 신뢰도 있는 사이트에 백링크되는 것도 우리 사이트의 신뢰도를 높이는 방법입니다. 하지만 너무 긴 URL은 심미적으로 좋지 않아 백링크 기피 대상이 될 수 있습니다.
- 랭킹 URL에 해시(#) 기호가 포함되지 않도록 주의합니다.
- URL에 포함된 해시 기호는 페이지 내 특정 위치를 가리키는 예약어입니다. 때문에
/#tagname혹은/how-to-use-#hashtag-on-Instagram이런 형태의 URL은 의도치 않게 인식될 수 있습니다. - 기본적으로 URL에 특수문자는 포함되지 않도록 하는 편이 낫습니다.
- URL에 포함된 해시 기호는 페이지 내 특정 위치를 가리키는 예약어입니다. 때문에
- 랭킹 도메인 히스토리를 1년 이상으로 유지하는 게 좋습니다.
- 정상적인/합법적인 도메인은 보통 몇 년간의 비용을 미리 치르고 사용되는 반면, 임시적인/불법적인 도메인은 1년 이상 사용되는 경우가 드물어서 1년 미만의 도메인은 우선순위 산정에서 불리할 수 있습니다.
- 랭킹 국가 도메인은 별 영향을 끼치지 않습니다. (ex: .kr)
사용자 경험 최적화 전략
이 전략은 SEO에 직접적으로 영향을 끼치지 않으며 장기간 전략으로 가져가야 하는 부분이라 효과가 곧장 눈에 보이지도 않습니다. 어디까지나 많은 사용자가 우리 사이트를 검색하고, 검색 결과에서 우리 사이트를 클릭하며, 재방문 의사를 가지고 이 과정을 반복하기 바라며 취하는 전략입니다.
- 랭킹 로딩이 빠르게 이루어질 수 있도록 합니다.
- (저를 포함해) 요즘 사용자들은 그리 참을성이 좋지 않습니다. 긴 로딩 시간은 사이트에 부정적인 의견을 갖게 합니다.
- 구글은 로딩 속도가 짧은 웹 사이트에 더 높은 우선순위를 매기므로, SEO에 직접적인 영향을 끼치는 요소로도 볼 수 있습니다.
- 랭킹 OG 태그를 설정합니다.
- OG 태그는 사용자들의 공유 경험에 긍정적인 영향을 끼칩니다. 공유 만족도는 공유와 재방문 횟수로 이어질 수 있으며, 이는 사이트 인지도와 신뢰도 상승에 도움이 될 수 있습니다.
- 랭킹 양질의 콘텐츠를 생산합니다.
- 결국 가장 중요한 건 우리가 가진 콘텐츠에 사용자들이 구미가 당겨야 한다는 겁니다. 화제가 되는 키워드에 편승하는 것도 좋은 방법입니다.
- 너무 많은 광고는 아무리 질 좋은 콘텐츠도 스팸으로 보이게 합니다. 광고 때문에 사용자를 떠나보내는 것만큼 아쉬운 일도 없습니다.
- 검색 결과를 눌러 들어온 사용자가 ‘속았다!’는 느낌을 받지 않게 합시다.
현실적인 SEO 장애물
모든 검색 엔진에 대응할 순 없다.
그 많은 검색 엔진들을 모두 만족시키는 건 사실상 불가능한 일입니다. 국내향 웹 사이트들은 구글, 네이버와 같은 주요 검색 엔진에 선택과 집중하는 것이 올바른 길일 수 있습니다.
개발 시작부터 마케터-기획자-개발자의 유기적인 노력이 필요하다.
SEO를 위해선 별거 아닌 키워드와 텍스트, 심지어 이미지 파일마저도 임의 삽입되어선 안 됩니다. 바람직한 절차라면 아무래도 기획 단계에서 우선 검토가 되어야 하고, 마케팅 관점에서 확정되어야 하며, 개발 단계에서 적절하게 삽입되어야 합니다.
하지만 현업에서는 개발자가 개발 단계에서 임의로 삽입한 형태 그대로가 유지되는 경우가 많아 항상 아쉬울 수밖에 없는 부분이기도 합니다.
마치며
웹 사이트를 구축하는 데 있어 때로는 SEO가 덜 중요할 수도 있지만, 대개 일정 수준 이상의 검색 엔진 가시성은 요구되는 법입니다. 그런데 바쁜 일정 속에 있다 보면 SEO의 우선순위는 저 뒤로 밀려나고 개발하기에 급급해지기 십상이죠. 그렇게 미루고 미루다 보면 산더미처럼 쌓이는 게 또 SEO 작업입니다. 그런 의미에서 사소한 요소부터 하나씩, 꼼꼼히 챙기는 습관을 들여보는 건 어떨까요? 이런 작은 노력들이 웹 사이트의 성공이라는 결실로 이어질지도요 😏
긴 글 읽어주셔서 감사합니다!