안녕하세요. 현재는 제품화개발팀에서 데이터 통계 사이트를 개발, 운영하는 12년 차 개발자 김수지입니다. 이전에는 Jira, Confluence, Gitlab, Jenkins 등 전반적인 개발 시스템 구축 및 운영을 진행하였습니다.
각각의 시스템이 운영되면서 자동화 프로그램을 개발하게 되었습니다. 시스템 간의 연동을 하게 되면서 시스템 성능, 애플리케이션 배포, 인프라 상태 등을 한눈에 파악할 수 있도록 하는 우리의 개발 시스템에 맞는 사이트가 필요하다고 느껴졌습니다.
DevOps는 개발(Development)과 운영(Operations)의 결합을 의미합니다. 코드의 품질, 제품의 생산성과 완성도를 위해서는 현재 우리의 상태를 파악하는 것이 가장 중요합니다. 데이터 시각화는 이러한 DevOps 프로세스의 효율성을 높이고 문제 해결을 더 신속하게 할 수 있게 합니다.
DevOps 시각화에 필요한 요소는 크게 데이터 식별, 수집, 저장 및 관리, 시각화, 보완으로 나눌 수 있습니다. 각각의 요소는 DevOps 환경에서 데이터를 실시간으로 모니터링하고 분석하기 위해 필수적입니다. 아래에서 각 요소를 구체적으로 설명하겠습니다.
데이터 식별
DevOps 데이터 시각화에서 데이터 수집 단계는 전체 파이프라인의 핵심적인 기반을 형성하며, 개발 규칙, 방법론, 그리고 배포 흐름을 토대로 정량화할 수 있는 데이터를 API를 통해 수집하는 과정입니다. 이 과정에서는 로그 데이터, 메트릭, 배포 빈도와 같은 정량적 데이터를 다양한 시스템에서 가져와 분석과 시각화를 위한 원천 데이터로 사용합니다.
데이터 소스 식별
각 단계에서 수집할 수 있는 다양한 데이터를 운영하는 규칙과 사이클을 토대로 기준을 세워 필요한 데이터를 정의합니다.
1. 이슈 등록 : 기간별 등록된 이슈 수, 개발기간, 완료 여부, 등록부터 배포까지 소요 기간
2. 개발 : 기간별 저장소별 커밋 수, 코드리뷰가 이루어진 merge request 수
3. 빌드/배포 : 빌드 현황, 빌드 리드타임, 빌드실행 성공률, 기간별 빌드 실행 수
데이터 수집
Jira에서 이슈 정보를 가져오거나, GitLab에서 프로젝트 정보를 가져오거나, Jenkins에서 빌드 상태에 대한 정보를 가져오려면 각 시스템에서 제공하는 REST API 호출을 통해 Raw 데이터를 가져옵니다. 이를 토대로 분석하려는 용도에 맞게 데이터를 가공합니다.
REST API 란?

© Copyright AltexSoft 2024. All Rights Reserved.
REST API(Representational State Transfer Application Programming Interface)는 웹 기반의 서비스와 클라이언트 간의 통신을 위한 아키텍처 스타일입니다. REST는 리소스를 URI(Uniform Resource Identifier)를 통해 정의하고, 서버의 자원을 다양한 클라이언트에 구애받지 않고 사용할 수 있게 하는 설계 방식으로, HTTP 요청에 대한 응답으로 서버의 자원을 반환합니다.
이때, 서버에서 보내는 응답이 특정 기기에 종속되지 않도록 모든 기기에 통용될 수 있는 데이터(JSON)를 반환하는데, 다양한 클라이언트의 요청에 일일이 View 페이지를 응답하는 것이 아니라, JSON 데이터를 응답하는 것입니다.
우선, 데이터를 분석하고자 하는 개발, 빌드 시스템인 GitLab과 Jenkins REST API 기본적인 사용법에 설명하겠습니다.
GitLab REST API
1. GitLab 호스트에 있는 모든 프로젝트 목록을 검색합니다.
curl "https://gitlab.example.com/api/v4/projects"2. Merge Request의 정보를 얻고 싶다면 아래와 같이 호출합니다.
curl "https://gitlab.example.com/api/v4/merge_requests"3. 파라미터를 특정하여 원하는 JSON 데이터만 얻을 수 있습니다.
GET /merge_requests?state=opened
GET /merge_requests?state=all
GET /merge_requests?milestone=release
GET /merge_requests?labels=bug,reproduced
GET /merge_requests?author_id=5
GET /merge_requests?author_username=gitlab-bot
GET /merge_requests?my_reaction_emoji=star
GET /merge_requests?scope=assigned_to_me
GET /merge_requests?search=foo&in=title4. 결괏값은 JSON 형태로 반환됩니다.
아래와 같은 field 값을 확인하여 필터링한 데이터를 가져옵니다.
[
{
"id": 1,
"iid": 1,
"project_id": 3,
"title": "test1",
"description": "fixed login page css paddings",
"state": "merged",
"imported": false,
"imported_from": "none",
"merged_by": { // Deprecated and will be removed in API v5, use `merge_user` instead
"id": 87854,
"name": "Douwe Maan",
"username": "DouweM",
"state": "active",
"avatar_url": "https://gitlab.example.com/uploads/-/system/user/avatar/87854/avatar.png",
"web_url": "https://gitlab.com/DouweM"
},
...이하생략5. 반환된 결괏값을 토대로 여러 필터링된 값을 얻을 수 있습니다.
기간별 머지된 커밋 수, 생성된 커밋수, 작업자별 월별 작업 현황 등 여러 가지 데이터를 분석하여 정형화된 데이터로 만들 수 있습니다.
"merged_at": "2018-09-07T11:16:17.520Z",
"merge_after": "2018-09-07T11:16:00.000Z",
"prepared_at": "2018-09-04T11:16:17.520Z",
"closed_by": null,
"closed_at": null,
"created_at": "2017-04-29T08:46:00Z",
"updated_at": "2017-04-29T08:46:00Z",Jenkins REST API
1. 빌드 상태를 확인하여 JSON 형태로 받아옵니다. 이 요청을 통해 빌드의 결과나 실행 시간 등의 세부 정보를 가져올 수 있습니다.
curl -X GET http://<jenkins-url>/job/job-name/job-number/api/json \ --user <username>:<api_token>2. 마지막 성공한 빌드의 정보를 얻고 싶다면 아래와 같이 호출합니다.
http://[jenkins url]/job/[job name]/lastStableBuild/api/json3. 반환된 결괏값 중 필요한 JSON 파일 부분만 확인하면 “lastSuccessfulBuild” 객체에서 해당 정보를 가져올 수 있습니다.
여기서 “number” 값으로 빌드 번호를 확인할 수 있습니다.
...
"lastBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://[jenkins url]/job/test/1/"
},
"lastCompletedBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://[jenkins url]/job/test/1/"
},
"lastFailedBuild": null,
"lastStableBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://[jenkins url]/job/test/1/"
},
"lastSuccessfulBuild": {
"_class": "hudson.model.FreeStyleBuild",
"number": 1,
"url": "http://[jenkins url]/job/test/1/"
},
"lastUnstableBuild": null,
"lastUnsuccessfulBuild": null,
...이하생략4. 반환된 결괏값을 토대로 여러 필터링된 값(일일 빌드 실행 횟수, 빌드 소요 시간, 빌드 결과 등)을 얻을 수 있습니다.
"displayName": "#1",
"duration": 1065,
"estimatedDuration": 1065,
"executor": null,
"fullDisplayName": "test #1",
"id": "1",
"keepLog": false,
"number": 1,
"queueId": 2564,
"result": "SUCCESS",
"timestamp": 1693521935531,
"url": "http://[jenkins url]/job/test/1/",REST API 활용
REST API는 데이터를 받아오기도 하지만 새로운 작업을 생성하거나, 데이터를 전송할 때도 통신하는 중요한 역할을 합니다. 아래는 요청 유형에 따른 작업입니다. 요청 URL을 변경하여 해당 작업을 수행하게 됩니다.
| 요청 유형 | 설명 |
|---|---|
| GET | 하나 이상의 리소스에 액세스하고 결과를 JSON으로 반환합니다. |
| POST | 리소스가 성공적으로 생성되었으면 201 Created를 반환하고 새로 생성된 리소스를 JSON으로 반환합니다. |
| GET / PUT | 리소스가 성공적으로 액세스 되거나 수정되면 200 OK를 반환합니다. (수정된) 결과가 JSON으로 반환됩니다. |
| DELETE | 리소스가 성공적으로 삭제되었으면 204 No Content를 반환하거나 리소스가 삭제 예정이면 202 Accepted를 반환합니다. |
데이터 저장 및 관리
데이터 필터링 및 전처리
- 수집된 데이터에서 운영되는 DevOps 사이클에 맞는 이슈 등록 방식, 개발 흐름, 개발 규칙, 빌드 패턴을 고려하여 저장하고자 하는 데이터 필드를 정하게 됩니다.
- backend에서 받아오는 데이터의 속도를 위해 Postgresql DB에 필터링된 데이터만 저장합니다.
아래 Postgresql DB 테이블 생성, 검색에 대해 살펴보겠습니다.
1. 기본 접속 방법
psql -U your_username -d your_database -h your_host -p your_port2. SQL 명령어를 사용하여 데이터베이스 생성
PostgreSQL 터미널(psql)에 접속한 후, 다음 명령어를 입력합니다.
CREATE DATABASE your_database_name;3. 새로운 테이블을 생성하여 입력하고자 하는 데이터 필드를 정의
아래 코드는 mr 테이블을 새로 생성하여 merge request에 대한 필요한 데이터 필드를 정의합니다.
CREATE TABLE mr (
id SERIAL PRIMARY KEY, \
mriid VARCHAR(255) NOT NULL, \
repoName VARCHAR(255) NOT NULL, \
targetbranch VARCHAR(255) NOT NULL, \
createDate TIMESTAMP, \
mergeDate TIMESTAMP, \
commentcount NUMERIC NOT NULL, \
firstcommenttime TIMESTAMP, \
uploadtimestamp Date NOT NULL)4. 데이터 저장
기존 데이터가 있는지 확인한 뒤 해당 필드에 맞는 데이터를 저장합니다.
SELECT id, mriid, createDate FROM mr WHERE mriid=%s AND repoName=%s INSERT INTO mr(repoName,mriid,targetbranch,createDate,mergeDate,commentcount,uploadtimestamp) values (%s,%s,%s,%s,%s,%s,%s)5. 데이터 검색
데이터를 검색하는 과정을 쿼리라고 합니다. 입력된 데이터를 여러 형태로 계산하고 필터링하여 결괏값을 도출할 수 있습니다.
데이터 시각화
데이터 시각화는 데이터 분석 결과를 시각적으로 명확하게 표현하고 의사소통하는 것입니다. 방대한 양의 데이터들을 살펴보는 것은 현실적으로 어렵기 때문에 데이터를 한눈에 이해할 수 있도록 표나 차트로 정리하여 보여줍니다. 이를 통해 데이터 시각화는 ‘도구’가 아닌 ‘전략’으로 접근하는 것이 중요합니다.
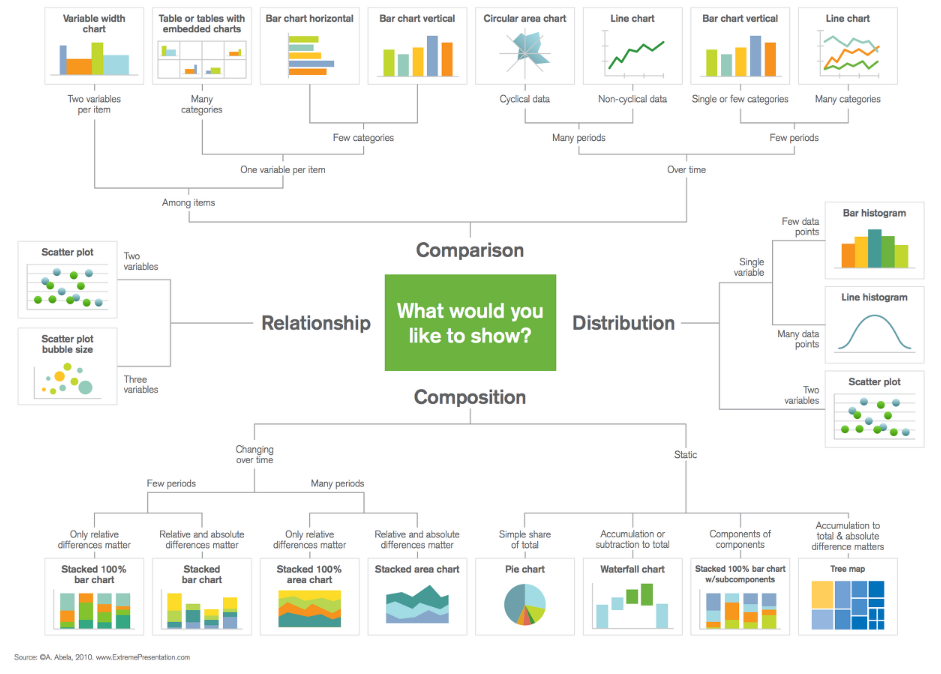
©A. Abela, 2010. www.ExtremePresentation.com
“데이터 시각화에서 표현하는 차트, 테이블 종류는 어떤 기준으로 선택할까요?“
1. 데이터 특성 : 데이터 사이즈, 연산작업이 필요한 데이터, 사용자 데이터처럼 특정 조건에 해당하는 사람의 숫자를 세거나 교집합을 계산하는 등 집합 연산이 필요한 데이터, 동적인 업데이트가 많은 데이터 등의 특성을 파악합니다.
2. 고도화된 분석 및 시각화 기능: 필드에 따른 시각화 효과의 변화, 타임라인 필요 여부, 여러 분석 차이를 시각화 할 수 있는지 등을 파악해야 합니다.
3. 분석한 데이터 공유 : 모든 데이터 관련 작업은 공유 및 협업 과정이 매우 중요합니다. 이에 분석한 데이터를 함께 봐야 하는 사람이나 협업 대상, 공유 주기 등을 파악해야 합니다.
이러한 데이터 특성을 먼저 파악하고 시각화를 진행하는 것이 중요합니다.
“한컴에서는 개발데이터 시각화를 어떻게 적용하였을까요?”
우선, 대시보드 형태로 차트를 구성하였습니다. 연간 통계, 월간 추이, 제품별 월별 흐름을 볼 수 있는 라인 차트로 구현하여 한눈에 보일 수 있도록 첫 화면을 구성하였습니다.

아래에서는 데이터별 시각화를 극대화할 수 있는 차트 구성을 어떻게 했는지 유형별로 설명하겠습니다.
차트
표현하고자 하는 목적에 맞게 시각화 유형을 선택해야 합니다. 비교(Comparion), 분포(Distribution), 구성(Comparison), 관계(Relationship)의 카테고리로 나눌 수 있습니다.
- 비교(Comparion)
- 라인 차트, 타임라인 차트를 사용하여 일정 기간의 월별 증감률과 일별 활동 흐름을 파악하기 위해 비교 카테고리의 타임라인 차트를 사용하였습니다.

일일 빌드 실행률 확인을 위해 각 빌드를 라인 차트로 표현하여 각 빌드간 실행 수에 대한 차이를 확인할 수 있습니다.
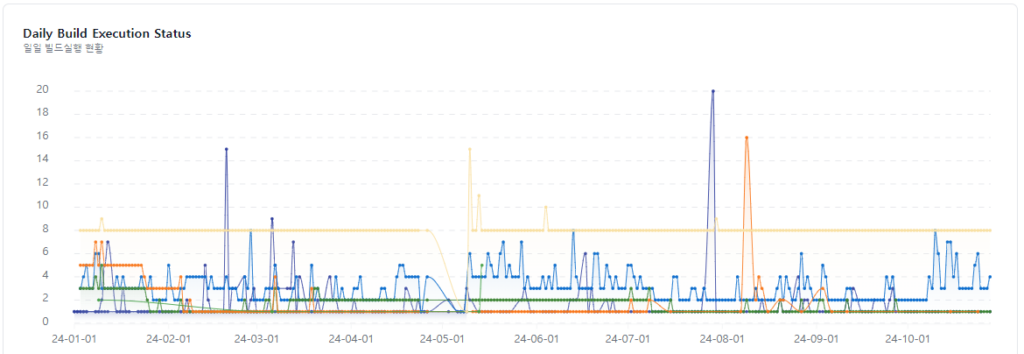
- 분포(Distribution)
- 산점도(Scatter Plot) 차트를 사용하여 데이터 포인트의 분포를 시각적으로 밀집도와 이상치를 확인할 수 있습니다. 빌드 실행 시간을 표현함으로써 평균적인 시간과 이상 시간의 차이를 확인하기 쉽습니다.
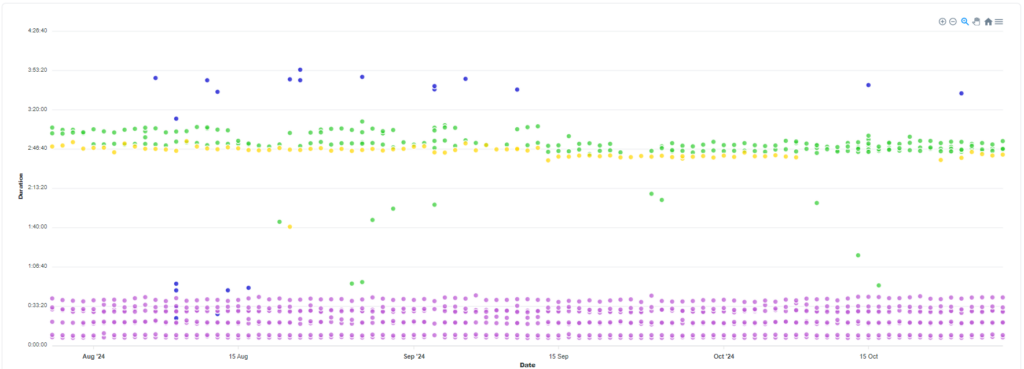
- 구성(Comparison)
- 누적 막대 차트(Stacked Bar Chart)로 각 막대를 통해 전체와 각 구성 요소의 비율을 비교할 수 있습니다.

- 관계(Relationship)
- 두 개 이상의 변수 간의 상관관계나 연관성을 확인하는 용도입니다.
- 산점도(Scatter Plot): 두 변수 간의 상관관계를 시각적으로 표현할 때 가장 많이 사용됩니다.
네 가지 카테고리 차트는 데이터의 특성에 따라 적합한 유형을 선택하는 데 도움이 되며, 시각화 효과를 통해 데이터의 본질을 잘 전달할 수 있는 차트를 선택하는 것이 중요합니다.
테이블
데이터 시각화에서 테이블은 주로 데이터의 구체적인 세부 사항을 명확하게 보여줄 때 사용됩니다. 테이블은 단순한 숫자 데이터를 전달할 때 유용하며, 시각화보다는 정량적인 세부 정보를 제공하는 데 초점을 맞춥니다.
- 테이블 사용이 적합한 상황
- 정확한 데이터 확인 : 정확한 숫자나 값을 사용자가 확인할 경우
- 명확한 비교 : 다양한 항목이나 속성을 나란히 놓고 직접 비교할 경우
- 데이터 수가 적을 때 : 소량의 데이터를 요약하거나 특정 지표를 보여줄 경우
- 다중 범주 사용 : 여러 범주를 갖는 데이터에서 각 범주의 모든 값을 한눈에 보고 싶을 경우
- 테이블과 그래프의 결합 사용
- 테이블과 그래프는 상호 보완적으로 사용
- 그래프는 데이터를 시각적으로 표현하여 주요 추세나 패턴을 쉽게 파악
- 테이블은 구체적이고 정확한 수치를 제공해 상세한 검토에 용이
아래에서는 금일 진행된 merge request의 목록과 각 브랜치의 현황을 표로 나타내어 현황을 파악할 수 있도록 하였습니다. 데이터의 명확한 비교와 다중 범주 사용의 상황에서의 실제 적용 사례입니다.


이렇게 한컴에서는 개발 전반에 사용되는 시스템을 한눈에 볼 수 있도록 데이터 형식에 따라 차트를 다양하게 사용하여 시각화를 구현하였습니다.
데이터 시각화 보완
데이터 시각화는 흐름대로 데이터 식별 > 분석 > 시각화 > 강조 > 메시지 과정으로 생각하기도 합니다. 하지만 데이터 시각화 작업은 분석 이후가 아니라 분석과 함께하는 작업입니다. 시각화 단계에서 끝난 것이 아니라 계속해서 필요한 정보에 대해 추가하고 분석 결과를 수정하며 가설을 세우는 것이 중요합니다.
즉, 가설 > 데이터 > 분석 및 시각화 > 가설 검증 > 시각화 보완 > 강조 > 메시지 흐름으로 순환되며 데이터 시각화 작업을 보완해 나가는 과정이 필요합니다.
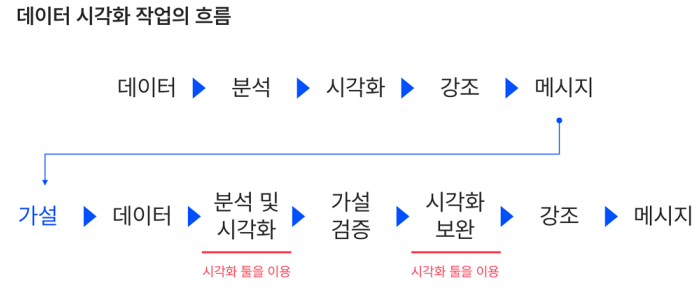
© Opensurvey Inc.
마치며
운영하는 개발 시스템에 알맞은 DevOps 시각화는 단순히 성능 측정 및 현황 파악에 그치지 않고, 제품개선의 방향을 설정하고 생산성을 고취하며 제품의 완성도를 위한 코드의 품질을 높이는 데 기여합니다. 결국, 단순한 모니터링 도구가 아니라, 제품의 성공을 위한 전략으로 사용되는 파트너입니다.
관련 참조
- https://www.tableau.com/ko-kr/learn/articles/data-visualization
- https://www.jenkins.io/doc/book/using/remote-access-api/
- https://docs.gitlab.com/ee/api/rest/
- https://velog.io/@ainokks071/REST-API-%EC%84%9C%EB%B2%84%EC%99%80-JSON-%EC%9D%B4%ED%95%B4
- https://blog.opensurvey.co.kr/research-tips/data-visualization/