요약
이 글은 중국 AI 스타트업 딥시크(DeepSeek)의 최신 언어 모델 DeepSeek-R1의 기술적 특징과 성능을 분석합니다. R1 모델은 기존 대형 AI 모델 대비 낮은 비용과 효율적인 학습 방식으로 주목받고 있으며, OpenAI의 o1과 비교할 만한 성능을 보이면서도 API 비용을 95% 절감할 수 있습니다. 또한, GRPO라는 새로운 강화학습 방식을 도입해 GPU 자원을 절감하고 학습 효율성을 높였습니다. 본 글에서는 DeepSeek-R1의 학습 과정, Distillation (지식 증류)을 통한 소형 모델 최적화, 그리고 한국어 적용 가능성을 포함한 다양한 요소를 상세히 살펴봅니다.
1. 개요
최근 AI 업계에서 중국 AI 스타트업 딥시크(DeepSeek)가 주목받고 있습니다. 기존 대형 AI 모델 대비 낮은 비용, 빠른 학습 속도, 적은 GPU 자원 활용이라는 차별점을 갖추고 있기 때문입니다.
특히, DeepSeek가 출시한 DeepSeek-R1 모델은 OpenAI o1과 비교할 만한 성능을 보이면서도 API 비용을 95% 절감할 수 있어 AI 비용 절감 가능성을 크게 높이고 있습니다.
이번 시간에는 DeepSeek의 기술적 특징과 이를 활용한 비즈니스 기회를 분석하고, 이를 어떻게 적용할 수 있을지 살펴봅니다.
2. DeepSeek 란?
DeepSeek는 2023년 5월 중국에서 설립된 AI 스타트업으로, 대규모 언어 모델(LLM)과 추론 모델을 개발하고 있습니다. 2025년 1월, DeepSeek는 DeepSeek-R1 모델을 기반으로 한 무료 AI 어시스턴트 앱을 출시했고, 이 앱은 미국 iOS 앱스토어에서 ChatGPT를 제치고 차트 1위를 기록하며 큰 반향을 일으켰습니다.

3. DeepSeek 모델 비교 : V3, R1, Distillation (지식 증류)의 차이점
DeepSeek의 AI 모델인 V3와 R1 그리고 Distillation(지식 증류)모델의 개발 목적과 학습 방식에는 차이가 있습니다.
| 구분 | DeepSeek V3 | DeepSeek R1 | DeepSeek- R1-Distill-Qwen-1.5B ~ 32B (예시) |
|---|---|---|---|
| Base Model | Mixture-of-Experts(MoE) 구조를 기반으로 한 Transformer | DeepSeek V3 | Qwen2.5-Math-1.5B~32B |
| 목적 | 일반적인 자연어 처리와 이해 | 수학적 추론, 코딩, 복잡한 문제 해결 등 고도의 추론 능력 | 소형 모델에 수학, 코딩, 추론 성능 향상 |
| 학습 방식 | 대규모의 일반 텍스트 데이터를 기반으로 지도 학습(Supervised Fine-Tuning, SFT) | V3 모델을 기반으로 추가적인 강화 학습(Reinforcement Learning, RL)을 적용 | R1 대형 모델의 추론 능력을 소형 모델로 효율적 지식 증류(Distillation) 하는 방식으로 지도 학습(Supervised Fine-Tuning, SFT)을 적용 |
요약하면, V3는 일반적인 언어 이해를 위한 모델인 반면, R1은 V3를 기반으로 강화 학습을 통해 고급 추론 능력을 갖춘 모델입니다. 고급 추론 능력을 가진 R1의 지식을 소형 모델로 지식 증류(Distillation) 한 것이 바로 DeepSeek R1-Distill- Qwen입니다.
4. DeepSeek R1의 핵심 포인트
4-1) DeepSeek의 개발 비용·성능 : OpenAI와 DeepSeek의 장단점 분석
DeepSeek는 고성능 ‘R1’ 모델을 600만 달러의 비용으로 개발했다고 밝혔으며, 이는 OpenAI 나 메타 같은 기업들이 수십억 달러를 투자하는 것과 비교하면 현저히 낮은 비용입니다.
단, ‘학습비용의 책정 방식’과 ‘주장한 H800과 다른 고성능 H100 GPU 사용’ 등 여러 의혹이 제기되고 있는 상태입니다.
| 구분 | OpenAI o1 (미국) | DeepSeek R1 (중국) |
|---|---|---|
| 설립 | 2015년 | 2023년 |
| AI 개발 비용 | 1억 달러 (추정) | 557만 6,000달러(이전 모델 V3 기준) |
| 연구 개발 인력 (추정) | 1,200명 | 139명 |
| 모델 공개 | 폐쇄형 | 오픈소스(MIT) |
| API 비용 ※ 1M 토큰 출력 기준 | $60 | $2.19 |
| 투입된 반도체 | • 엔비디아 고성능 칩 • H100 1만 개 이상 (추정) | • 엔비디아 저사양 칩 • H800 2,000여개 |
| 모델 아키텍쳐 | MoE 구조 (추정) | MoE 및 MLA와 같은 기법 활용 |
| 보안성 | • 보안 정책 : 미국 및 영국의 AI 안전 가이드라인에 따라 체계적인 보안 기준을 따름 • 데이터 관리 : 다양한 규제 기관과 협력하며, 사용자 데이터 보호와 악의적 사용 방지를 위한 모니터링 체계를 갖춤 | • 검열 및 제한 : 민감한 정치적 주제에 대해 엄격한 검열 및 응답 제한이 적용됨 • 데이터 관리 : 프라이버시 우려 (* 개인정보 이슈 참고) |
| 장점 | • 안정성과 신뢰성 • 풍부한 부가 기능 : 음성 모드, 이미지 생성 등 다양한 기능 • 커뮤니티가 활성화되어 있음 • 정기적인 업데이트로 최신 정보 반영 | • 합리적인 가격과 접근성 : 초당 60개 이상의 토큰 생성 • 모델을 공개하여 커스터마이징 가능 • 투명한 추론 과정 : CoT 과정을 노출하여 모델의 문제 해결 과정을 이해하고 개선할 수 있는 기회 제공 |
| 약점 | • 비용이 상대적으로 비쌈 • 모델이 폐쇄되어 있음 | • 커뮤니티가 작음 • 다국어를 잘 수행하지 못함 • (강력한 추론이라고 하지만) 추론의 경우 o1-preview보단 잘하지만, o1보단 성능이 떨어짐 • 추가 검증이 필요 |
4-2) DeepSeek R1 모델 학습 방법
DeepSeek-R1의 훈련 과정은 여러 단계를 거쳐 모델을 점진적으로 개선하는 구조로 설계되었습니다. 도식에서 보이듯이 이 파이프라인은 SFT(Supervised Fine-Tuning)와 GRPO(Group Relative Policy Optimization)를 핵심으로 하여, 효율성과 성능을 극대화합니다. 아래 표를 통해 각 단계를 단계별로 살펴보겠습니다.
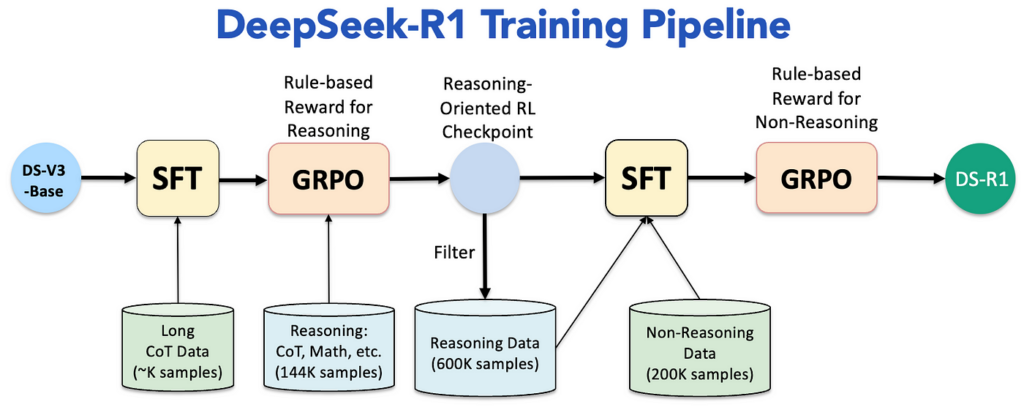
아래 표를 통해 각 단계를 단계별로 살펴보겠습니다.
(1) 모델 학습 프로세스
| 구분 | 1. Pretraining | 2. Cold Start | 3. Pure RL Training | 4. Synthetic Data Synthesis | 5. SFT on Synthetic Data | 6. Final RL Fine‑Tuning | 7. 그 외 Distillation (지식 증류) |
|---|---|---|---|---|---|---|---|
| 학습 기법 | 표준 Transformer 사전 학습 (Mixed Precision, MLA, MOE 등) | Supervised Fine-Tuning (SFT) | GRPO 기반 강화 학습 (Pure RL) | Synthetic Data Generation | Supervised Fine-Tuning (SFT) (2Epoch) | GRPO 강화학습 (Rule‑based + Model‑based Reward) | Supervised Fine-Tuning (SFT) |
| 설명 | 대규모 다국어, 수학, 코딩 데이터로 Transformer 모델을 사전 학습 | • RL 학습 전 안정적인 시작을 위한 준비 단계 • 표준 포맷 (ex. <special_token> <reasoning_process> <special_token> <summary>)으로 SFT 진행 | • 지도 데이터 없이 순수 강화 학습 진행 • 규칙 기반 보상(정확도, 포맷)으로 모델이 스스로 추론하도록 학습 (R1‑Zero 단계) | • R1‑Zero를 통해 생성된 고품질 추론 데이터를 추가로 합성 • 추론 데이터와 비추론 데이터를 각각 생성하여 데이터셋 구성 | • 합성 데이터셋을 활용하여 추가 SFT 진행 • 모델의 응답 가독성 및 일반 응답 능력 향상 | • 규칙 기반 및 모델 기반 보상을 결합해, 비추론 Task(글쓰기, 번역 등)에도 도움이 되는 방향으로 최종 미세 조정 – helpfulness와 harmlessness 강 | • 최종 모델의 추론 능력을 소형 모델로 지식 증류 • 지식 증류 된 소형 모델로도 동일 수준의 추론 성능 발휘 |
| 사용 데이터 | 14.8T tokens (영어, 중국어, 수학/코딩 등) | • 수천 개의 CoT 데이터셋 • Reasoninn 데이터 : 약 144K CoT (GSM8K, MATH 문제셋) | 지도 데이터 없이, 규칙 기반 보상 시스템 (정확도 및 포맷 검증) | 600K 추론 데이터 (Rejection Sampling 적용) + 200K 비추론 데이터 (DeepSeek‑V3 출력 활용) | 800K 합성 데이터 | 동일한 800K 합성 데이터 (보상 함수 개선 포함 : 언어 일관성 보상 추가) | DeepSeek‑R1로 부터 출력된 합성 데이터 |
| 결과 | DeepSeek‑V3‑Base 모델 | Intermediate SFT 모델 | DeepSeek‑R1‑Zero 모델 | 800K 합성 데이터 | Fine-tuned Checkpoint | DeepSeek‑R1 (최종 모델) | 지식 증류 모델 (ex. R1‑Distill‑Qwen‑7B, R1‑Distill‑Llama‑8B) |
4-3) 상세 기법
(1) GRPO (Group Relative Policy Optimization) 란?
GRPO는 PPO의 확장판으로 , 여러 그룹별 정책을 동시에 학습할 수 있는 구조를 제안합니다. 도식에서 GRPO의 구조를 보면, PPO와 비교해 다음과 같은 차이점을 발견할 수 있습니다:
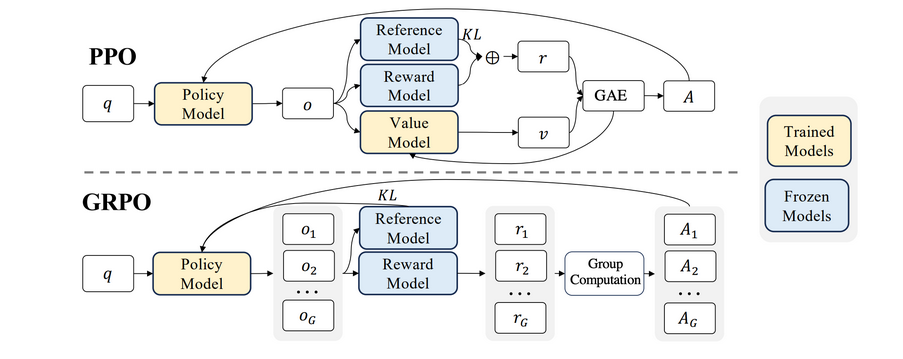
기존 PPO(Proximal Policy Optimization) 방식에서는 훈련 과정에 Value 모델이 필수였지만, DeepSeek의 GRPO (Group Relative Policy Optimization) 방식에서는 리워드 모델만을 활용하여 모델의 응답에 대한 보상을 계산합니다. 결과적으로, Value 모델을 제거하면서 연산량과 GPU 사용량을 줄이고 AI 학습 비용을 절감하며 운영 효율성을 높일 수 있었습니다.
GRPO는 PPO와 달리 Value 모델을 없애서 메모리를 절약하고 구조를 단순화했습니다.
- PPO는 Value 모델과 GAE(Generalized Advantage Estimator)를 통해 “정책이 얼마나 잘했는지”를 계산하는데, GRPO는 Value 모델을 쓰지 않으므로 GAE도 사용할 수 없습니다.
- 대신, 한 질문에 대해 여러 답변을 생성(예: 1개가 아니라 G개)하고, 각각의 답변을 리워드 모델로 평가한 뒤 평균·정규화하여 정책을 업데이트합니다.
- 이렇게 하면 Value 모델을 없앤 대신 여러 답변에서 얻은 점수를 합쳐 학습 안정성을 높이고, GAE가 없이도 bias·variance 문제를 어느 정도 완화할 수 있습니다.
- 또한 KL Divergence 계산도 기존 PPO와 조금 달라, Unbiased Estimator를 적용해 정책이 기준 모델에서 과도하게 벗어나지 않도록 제어합니다.
요약하면, value 없이도 여러 답변을 묶어 학습 안정성을 확보하고, 리워드를 정규화해 GAE 없이도 충분히 좋은 강화학습을 수행하는 방법입니다.
(1-2) OpenAI (RLHF) vs. DeepSeek R1 (GRPO) 비교
| 비교 항목 | OpenAI (RLHF) | DeepSeek R1 (GRPO) |
|---|---|---|
| 학습 방식 | 지도학습 + 강화학습 (PPO) | 강화학습 (GRPO) |
| 필요한 모델 수 | 4개 (AI, 평가, 리워드, 레퍼런스) | 3개 (AI, 리워드, 레퍼런스) |
| GPU 사용량 | 매우 높음 (4개 모델 운영) | 상대적으로 낮음 (평가 모델 제거) |
| 학습 비용 | 높음 | 낮음 |
| 학습 안정성 | 하이퍼파라미터 조정이 어려워 Mode Collapse 가능성이 있음 | 상대적으로 안정적 |
| 데이터 의존도 | 보상 모델을 훈련하기 위해 직접적인 인간 피드백이 필요 | 그룹별 응답을 상대적으로 평가하여 정책을 최적화 |
(2) 리워드 모델링 (Reward Modeling)이란?
DeepSeek-R1-Zero는 두 가지 주요 보상 체계로 구성되어 있습니다.
- 정확도 보상(Accuracy Rewards) : 응답의 정확도를 평가합니다.
- 수학 문제: 정답을 규칙 기반 검증 시스템(예: 컴파일러, 테스트 케이스)으로 평가
- LeetCode 문제: 컴파일 결과로 정답 여부 확인
- 형식 보상(Format Rewards) : 모델이 추론 과정을 <think> 태그로 구분하고, 최종 응답을 <answer>로 명확히 표시하도록 학습

(3) Distillation (지식 증류) 방법론
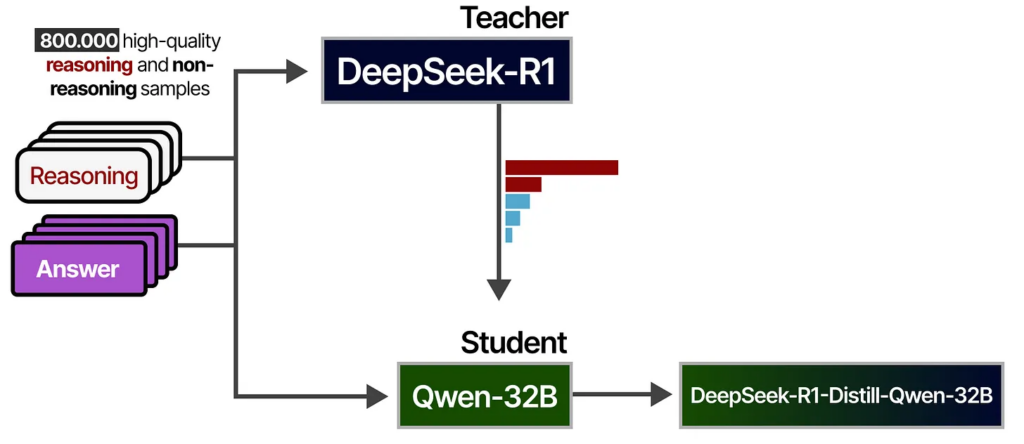
- DeepSeek-R1 고급 추론 패턴을 소형 모델에 전이하여, 효율성과 성능을 동시에 향상시키는 지식 증류(Distillation) 기법을 적용하였습니다. 이를 통해 대형 모델에서 학습된 고급 추론 능력을 소형 모델에서도 효과적으로 활용할 수 있도록 최적화하였습니다.
- 학습 데이터 : 600k reasoning(DeepSeek R1의 고급 추론 패턴 적용) + 200k non-reasoing
- 실험
- “Distillation 없이 대규모 강화 학습(RL)만으로도 유사한 성능을 달성할 수 있을까?“
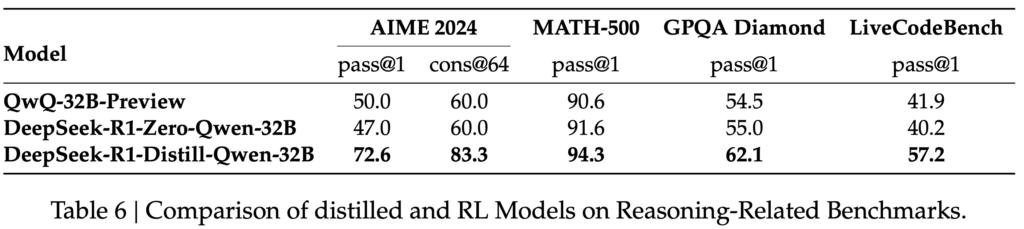
이를 검증하기 위해 Qwen-32B-Base 모델에 수학, 코드, STEM 데이터를 활용한 대규모 RL 학습(10K 스텝 이상)을 수행하여 DeepSeek-R1-Zero-Qwen-32B 모델을 생성하였습니다.
아래 그림의 Table 6에서 확인할 수 있듯이, RL 학습을 거친 32B 모델은 QwQ-32B-Preview와 유사한 성능을 보였으나, DeepSeek-R1에서 지식 증류된 DeepSeek-R1-Distill-Qwen-32B는 모든 벤치마크에서 훨씬 뛰어난 성능을 기록하였습니다.
4-4) DeepSeek R1의 성능
벤치마크 결과는 DeepSeek‑R1이 특히 수학, 코딩 등 추론 Task에서 경쟁 모델에 필적하거나 일부분은 우세하지만, 일반 지식 및 다중 분야에서는 소폭 차이가 나타납니다.
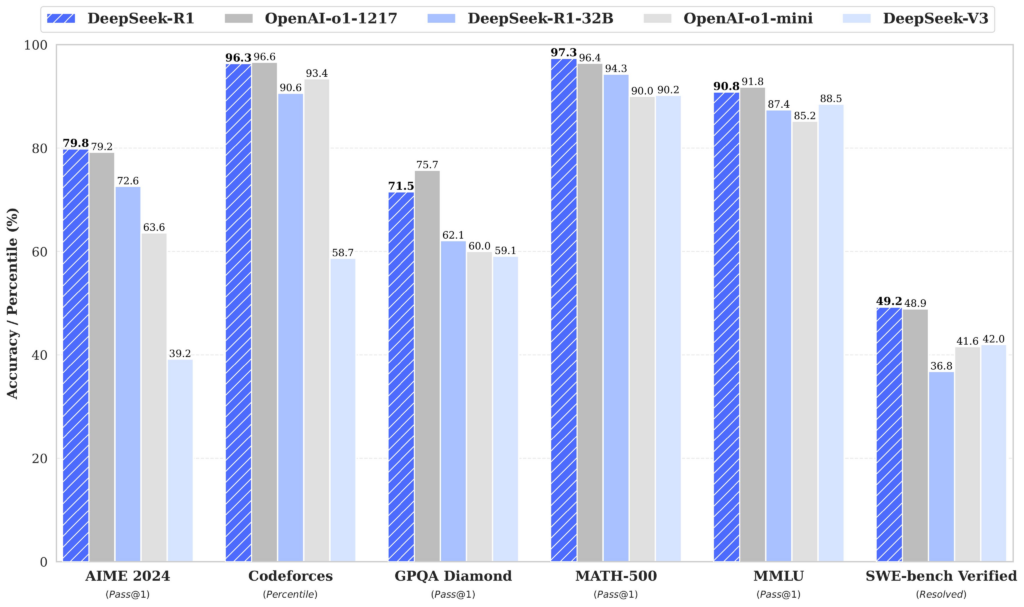
| 평가 분야 | 벤치마크 지표 | DeepSeek R1 | OpenAI o1 | 비고 |
|---|---|---|---|---|
| 수학 능력 | AIME 2024 (%) | 79.8 | 79.2 | 복잡한 수학 문제 해결 능력 우세 |
| 고급 수학 | MATH-500 (%) | 97.3 | 96.4 | 정밀한 수학 추론 성능 |
| 코딩 능력 | Codeforces (%) | 96.3 | 96.6 | 코딩 문제 해결에서는 근소한 차이 |
| 일반 지식 | GPQA Diamond (%) | 71.5 | 75.7 | 상식 및 일반 지식 응답은 o1이 약간 우세 |
| 다중 분야 지식 | MMLU (%) | 90.8 | 91.8 | 전반적인 언어 및 지식 이해도 비교 |
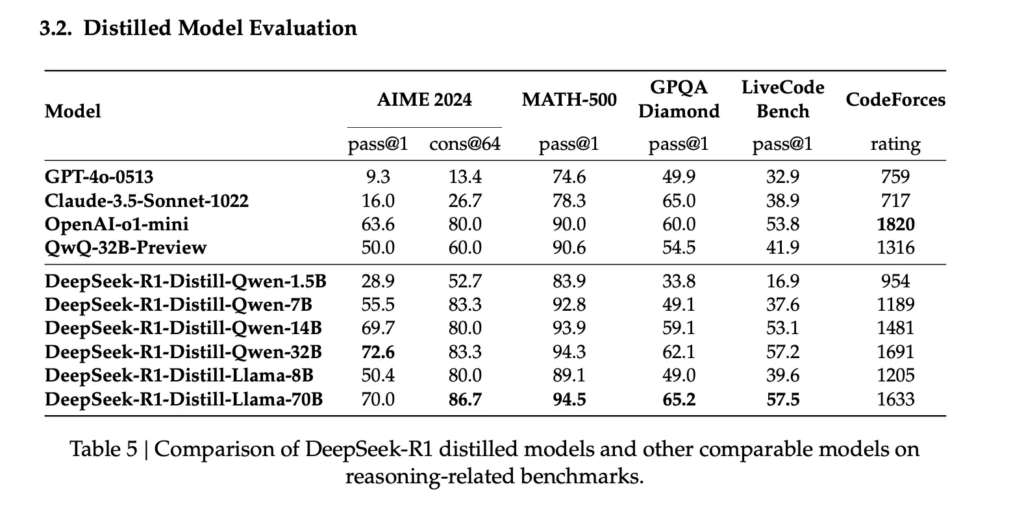
(1) DeekSeek R1 Distilled Model 평가
Distilled Model에선 1B 모델 성능과 7B 이상 모델에 비해 벤치마크 성능이 낮게 나타나지만, Distilled Qwen-1.5B의 GPT-4o, Claude 모델에 비해 수학 추론 능력에서 높은 성능을 보입니다. 즉, 지식 증류만으로도 소형 모델의 수학 추론 성능을 크게 높일 수 있습니다.
5. DeepSeek 모델의 한국어 적용 가능성 평가
※ 해당 내용은 DeepSeek V3, R1을 기준으로 작성되었습니다.
5-1) DeekSeek R1 한국 수능(국어, 수학) 성능 비교
ChatGPT(o1) vs DeepSeek(R1) 한국 수능 문제 풀이해 본 결과 ChatGPT가 전반적으로 높은 성적을 기록했지만, 시조 문제에서는 DeepSeek가 더 나은 성능을 보여줍니다.
🔗출처 : “한국 수능 문제 풀어봐” 챗GPT vs 딥시크 승자는 | JTBC 뉴스
5-2) LLM 모델의 영어 수능 성적 비교
최근 3개 학년도(2023, 2024, 2025) 수능 영어 점수를 기준으로 LLM 모델의 성능을 비교한 결과입니다.
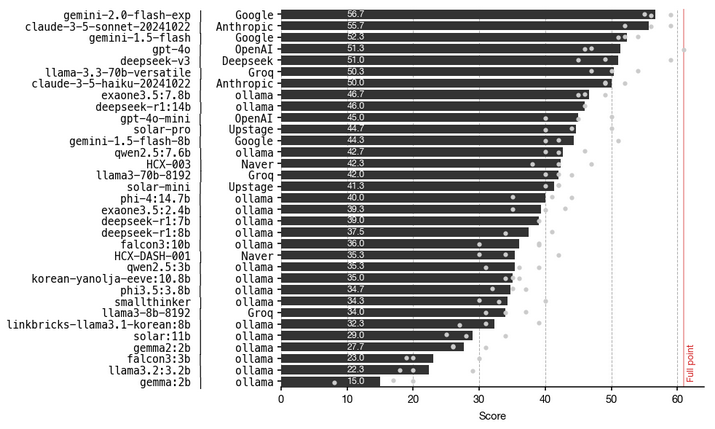
- LG AI 연구원의 EXAONE 3.5 : 현재 가장 높은 성능을 기록했습니다.
- DeepSeek-R1 (14B) : EXAONE 3.5 다음으로 높은 성능을 보입니다.
- 주로 영어와 중국어 데이터를 학습한 모델이지만, 한국어에서도 일정 수준 이상의 성능을 발휘합니다.
- 한국어 적용 가능성 : 대부분의 지문이 영어인 task에 관해 실험을 진행했기 때문에 추가적인 검증이 필요합니다.
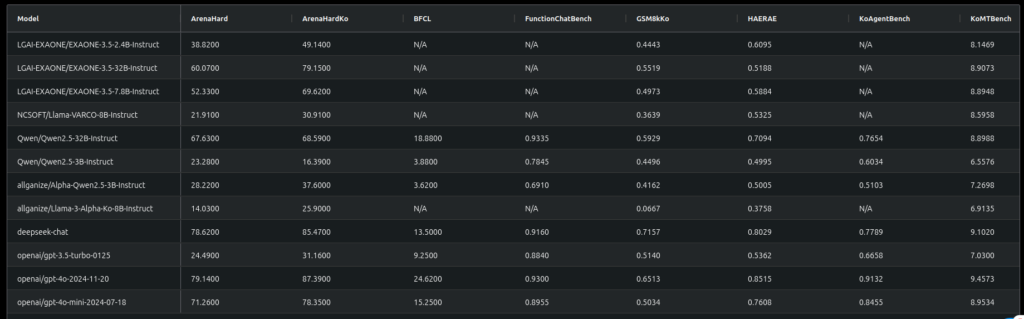
5-3) DeepSeek-V3 한국어 Agent 성능 및 적용 가능성
- GPT-4o mini와 유사한 성능
- DeepSeek-R1의 base 모델인 DeepSeek-V3의 한국어 Agent 성능은 GPT-4o mini와 비슷하거나 약간 낮은 수준으로 평가됩니다.
- 한국어 파인튜닝 미진행
- DeepSeek 모델은 한국어 데이터셋에 대해 별도의 파인튜닝을 거치지 않았음에도 불구하고, 한국어 Agent 성능이 준수한 수준을 유지합니다.
- 한국어 적용 가능성
- 현재 상태에서도 한국어 성능이 준수하므로, 추가적인 파인튜닝을 통해 한국어 관련 Task에 맞게 성능을 극대화할 수 있을 것입니다.
6. DeepSeek관련 이슈
6-1) 개인정보 이슈
- 딥시크는 AI 모델이 수집하는 데이터 범위가 광범위해 개인정보 보호 측면에서 우려가 커지고 있습니다. 특히 유럽의 프랑스와 아일랜드 등 일부 국가에서는 딥시크의 개인정보 처리 방식에 대한 조사를 진행하고 있으며, 이탈리아에서는 신규 앱 다운로드가 차단된 상황입니다.
- 국내도 국방부, 산업통상자원부, 외교부는 보안 우려를 이유로 딥시크 사용을 전면 금지하였으며, 한국수력원자력과 한전KPS 그리고 카카오와 LG유플러스도 딥시크 사용을 금지하고 있습니다.
- 앱 다운로드 차단국가 : 이탈리아
- 공공기관 앱 사용 제한 국가 : 대만, 호주, 미국(텍사스), 한국
- 딥시크 개인정보 처리 조사 국가 : 프랑스, 아일랜드, 미국
🔗출처 : 딥시크 (Deepseek) 요약, 이거 하나만 읽으세요! – LETSUR Blog
6-2) AI 투자 급변 이슈
중국의 저렴한 AI 모델 등장으로 엔비디아 주가가 급락하며 시가총액이 하루 만에 5,930억 달러 증발했습니다. 데이터 센터 및 전력 수요 기대감이 낮아지면서 관련 기업 주가도 하락했습니다. 따라서 중국 AI 기술의 급부상이 글로벌 AI 경쟁 구도를 변화시키고, 오픈소스 vs 독점 모델 간 경쟁이 재편되고 있습니다.
🔗출처 : 세계 AI업계에 “스푸트니크 순간” 가져온 딥시크 이야기 – 테크42
6-3) 국내/외 주요 AI 기업 반응
해외의 경우 OpenAI는 경량화된 AI모델 o3-mini를 무료로 배포하여 추론 능력을 강화했으며, 실시간 웹 탐색 및 다단계 추론이 가능한 딥 리서치를 출시해 경쟁력을 강화했습니다. 또한 OpenAI의 CEO 샘 알트만은 R1 모델에 대해 “제작 비용 대비 인상적이지만, 새로운 것은 없다”라는 반응이었습니다. HuggingFace는 R1 모델의 역설계 프로젝트를 진행하며, 동일한 성능의 오픈소스 버전을 제작할 계획이며 비공개된 데이터와 알고리즘을 분석해 공개 예정입니다. 또한 Meta는 DeepSeek AI 기술 분석팀을 구성해 AI 훈련 및 운영 비용 절감 방안을 연구하고 있고 학습데이터와 모델의 특성을 연구 중 입니다. 연구 결과를 기반으로 라마4 모델에 적용하여 올해 초 공개 예정이라고 합니다.
국내의 경우 뤼튼테크놀로지스는 자체 클라우드에 R1 모델을 탑재해 카카오톡을 통한 무료 질의응답 서비스를 제공하고 있으며, 마음AI는 기업(B2B) 전용 솔루션을 출시해 내부망에 R1 모델을 설치할 수 있도록 지원하고 있습니다. 포티투마루는 멀티 LLM 기반 생성형 AI 솔루션에서 R1 모델을 공식 지원하며, 국내 기업들도 R1 모델을 활용한 AI 서비스 확장에 나서고 있습니다.
🔗출처 : “中 딥시크, 안전하게 쓰세요” 뤼튼 ‘안전 서비스’ 시작 美, 딥시크-R1 해부 나섰다
🔗출처 : 딥시크에 한방 먹은 오픈AI, ‘딥 리서치’로 맞불… “실시간 웹 탐색 강화”
🔗출처 : OpenAI chief Altman signs deal with South Korea’s Kakao after DeepSeek upset
6-4) 업계 주요 인사 및 커뮤니티 반응
AI 분야의 주요 인사들은 DeepSeek-R1을 혁신적인 돌파구로 평가하며 오픈소스 모델의 강점을 강조하고 있습니다. 반면, 일부에서는 성능에 대한 독립적 검증 필요성과 검열 우려를 제기하며 신중한 접근이 필요하다는 의견도 있습니다. 전반적으로 DeepSeek-R1은 AI 생태계의 협력과 경쟁 구도를 변화시키는 계기가 될 것으로 보입니다.
🔗출처: 세계 AI업계에 “스푸트니크 순간” 가져온 딥시크 이야기 – 테크42
7. R1 기반 모델의 서비스 운영 비용 분석
- VRAM 사용량
- VRAM 요구 사항은 대략적인 수치이며 특정 구성 및 최적화에 따라 달라질 수 있습니다.
- 분산 GPU 설정
- 전체 DeepSeek-R1 671B 모델을 배포하려면 단일 GPU로는 광범위한 VRAM 요구 사항을 처리할 수 없으므로 멀티 GPU 설정이 필요합니다.
- 낮은 VRAM 사용을 위한 증류 모델
- 낮은 VRAM 사용을 위한 증류 모델은 계산 요구 사항을 줄이면서 최적화된 성능을 제공하므로 단일 GPU 설정에 더 적합합니다.
| 모델 명 | 파라미터 수 (B) | VRAM 요구사항 (GB) | 필요한 GPU 최소 자원 |
|---|---|---|---|
| DeepSeek-R1 | 671 | ~1,342 | Multi-GPU setup (e.g., NVIDIA A100 80GB ×16) |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5 | ~0.7 | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-Distill-Qwen-7B | 7 | ~3.3 | NVIDIA RTX 3070 8GB or higher |
| DeepSeek-R1-Distill-Llama-8B | 8 | ~3.7 | NVIDIA RTX 3070 8GB or higher |
| DeepSeek-R1-Distill-Qwen-14B | 14 | ~6.5 | NVIDIA RTX 3080 10GB or higher |
| DeepSeek-R1-Distill-Qwen-32B | 32 | ~14.9 | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70 | ~32.7 | NVIDIA RTX 4090 24GB ×2 |
8. DeepSeek 전망
※ 해당 내용은 개인적인 생각입니다.
8-1) 지속적인 실험과 모델 파인튜닝 파이프라인 구축의 필요성
DeepSeek 모델이 현재의 성과에 이르기까지 수많은 시도와 오류를 고친 점은 매우 인상적이었습니다. 이에 착안하여, 우리는 새로운 모델이 등장할 때마다 이를 빠르게 파인튜닝하고 성능을 비교 및 모니터링할 수 있는 파이프라인을 구축할 필요가 있습니다. 이를 통해 최소 기능 제품(MVP) 방식으로 모델을 점진적으로 고도화할 수 있을 것입니다.
8-2) 오픈소스 모델 공개에 따른 데이터의 중요성
곧 OpenAI 또한 오픈소스로 모델을 공개할 예정이며, 이에 따라 LLM 성능이 상향 평준화될 가능성이 큽니다. 이러한 상황에서 중요한 것은 독점적인 라이선스를 보유한 모델보다 더 나은 성능을 가진 오픈소스 모델이 등장할 수 있다는 점입니다.
이때 회사에서 취할 수 있는 핵심 경쟁력은 바로 데이터라고 생각합니다. 독자적인 데이터와 이를 기반으로 한 모델 최적화 및 학습을 통해 라이선스 모델보다 더 뛰어난 성능을 확보할 수 있을 것으로 기대가 됩니다.
이를 위해,
- 노하우가 담긴 데이터 확보
- 강화 학습 적용을 위한 로그 데이터 수집 방안 모색
등을 수행하여 경쟁력을 강화할 수 있다고 봅니다.
8-3) 2B 모델 기반의 최적화된 서비스 전략
Distilled Qwen-1.5B 모델이 GPT-4o 및 Claude 모델에 비해 수학 추론 능력에서 우수한 성능을 보인 점은, 한국어 환경에서도 지식 증류 과정을 통해 7B 모델을 2B 규모로 경량화하여 실험할 가치가 있음을 시사합니다. 특히, 수학 문제와 같이 명확한 추론 과정을 요구하는 작업에서 뛰어난 성능을 보였듯이, 다른 분야의 작업에서도 추론 과정을 구조화하여 적용한다면 수학·과학 분야뿐 아니라 창의적인 글쓰기 영역에서도 경쟁력 있는 결과를 도출할 수 있을 것으로 기대됩니다.
이러한 접근이 성공한다면, 작은 모델로도 높은 성능과 빠른 응답 속도를 갖춘 최적화된 서비스 개발이 가능해지며, 특히 모바일 환경에서도 원활한 서비스 제공이 가능해집니다. 이를 통해 경량화된 모델을 기반으로 한 비용 효율적인 서비스 운영과 더불어, 다양한 플랫폼으로의 확장 가능성도 확보할 수 있을 것입니다.
마치며
※ 해당 내용은 개인적인 생각입니다.
최근 DeepSeek-R1과 같은 모델의 발전을 살펴보면서, 과거의 개념들인 강화 학습 프레임워크나 지식 증류(distillation)의 중요성을 다시금 인식하게 되었습니다. 이러한 사내 스터디 과정에서 기존 개념들을 재조명하고 새로운 관점에서 활용하는 방안을 토의해 봄으로써, 모델 개발에 추가적인 아이디어 창출과 성능 향상에 기여할 수 있을 것입니다.
Reference
- DeepSeek-V3 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek-R1 Paper Explained – A New RL LLMs Era in AI? – AI Papers Academy
- DeepSeek
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs viaReinforcement Learning 내용 정리
- A Visual Guide to Reasoning LLMs
- Welcome to my blog | 딥시크(Deepseek)-R1에 대한 고찰. Thinking about Deepseek-R1 with Reinforcement Learning(RL).
- A Visual Guide to Reasoning LLMs