요약
이 글은 HWP 포맷의 실제 예제 분석을 통해 문서 구조와 데이터 파싱 방식을 설명합니다. HWP 파일의 주요 구조 요소인 DocInfo와 BinData를 중심으로, 레코드 기반 저장 방식과 데이터 추출 절차를 Python 코드와 함께 상세히 다룹니다. 각 레코드의 헤더 해석, 문서 속성 파싱, ID 매핑 및 바이너리 데이터 처리 방식 등을 예제를 통해 구체적으로 설명하며, HWP 문서 내부 데이터를 효과적으로 읽는 방법을 소개합니다.
서론
지난 시간에는 HWP 문서 파일 구조에 대한 공식 문서를 바탕으로, HWP 포맷을 분석하여 문서 내부 정보의 구성과 읽는 방법을 살펴보았습니다. 이번 글에서는 Python 코드 예제를 통해 HWP 파일을 파싱하는 방법을 알아보겠습니다.
“한/글 문서 파일 형식 : HWP 포맷 구조 살펴보기“에 대한 자세한 내용은 아래 블로그를 참고 부탁드리겠습니다.
🔗 한/글 문서 파일 형식 : HWP 포맷 구조 살펴보기
✍ 작성자 : 한글개발팀 정우진 님
HWP 파일은 복잡한 구조를 가지고 있어, 특히 본문(BodyText) 같은 정보는 다양한 요소들이 결합되어 있어 파싱이 어려울 수 있습니다. 그래서 이번 글에서는 비교적 간단한 DocInfo 영역을 읽어보는 것으로 HWP 파일 파싱을 시작해 보겠습니다.
사용할 라이브러리
HWP 파일은 Compound File Structure라는 이진(Binary) 형식으로 이루어져 있습니다. 이 구조는 저장소 (Storage)와 스트림(Stream)으로 이루어져 있어, 파일 내부에 포함된 다양한 데이터들을 효율적으로 관리할 수 있도록 합니다.
HWP 파일의 데이터를 파싱하고 접근하기 위해서는 이러한 바이너리 구조, 특히 Storage와 Stream을 읽을 수 있는 라이브러리가 필요합니다. 또한 HWP 파일은 용량을 최소화하기 위해 압축 기능을 사용하고 있는데, 이때 zlib 압축 알고리즘이 사용됩니다.
이번 글에서는 Python을 이용해 HWP 포맷을 파싱하기 위해 두 가지 라이브러리를 사용합니다.
import olefile
import zlib이 두 라이브러리를 사용하면 HWP 파일의 이진(Binary) 구조를 해석하고, 압축된 데이터를 복호화하여 원본 데이터를 편리하게 확인할 수 있습니다.
HWP 파일에서 DocInfo읽기
HWP 파일의 전체적인 구조는 파일 인식 정보, 문서 정보, 본문 등 여러 부분으로 나뉩니다. 이 중 HWP 파일을 파싱하는 데 있어 주목해야 할 부분은 레코드 구조와 압축/암호화입니다.
[표 1] 전체 구조 (공식 문서 [표 2] 참조)
| 설명 | 구별 이름 | 길이(바이트) | 레코드 구조 | 압축/암호화 |
|---|---|---|---|---|
| 파일 인식 정보 | 고정 | |||
| 문서 정보 | 고정 | V | V | |
| 본문 | 가변 | V | V | |
| … | ||||
| 바이너리 데이터 | 가변 | V | ||
| … |
FileHeader는 파일이 HWP 문서임을 알리는 단순한 인식 정보가 고정된 길이로 나열되어 있습니다. 반면, 실제 문서의 내용을 담고 있는 DocInfo(문서정보)와 BodyText/Section0(본문)은 다릅니다. 이들은 레코드 구조로 데이터가 저장되며, 필요에 따라 압축 또는 암호화가 적용될 수 있습니다. 즉, DocInfo와 BodyText 같은 핵심 데이터는 단순한 정보 나열을 넘어 체계적인 구조와 보안 기능을 갖추고 있습니다.

특히 아래 그림에서 보시는 것과 같은 DocInfo 데이터를 온전히 얻으려면, 압축된 DocInfo 데이터를 복호화 하는 과정이 필수적입니다.
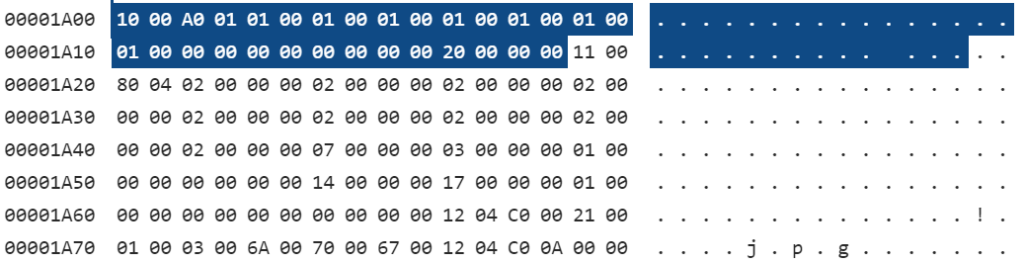
위에서 언급한 라이브러리를 활용해 HWP파일에서 DocInfo 스트림을 읽어오는 예제를 함께 살펴보겠습니다.
@dataclass
class Document:
sectionCount: int = 0
pageStartNum: int = 0
footnoteStartNum: int = 0
endnoteStartNum: int = 0
pictureStartNum: int = 0
tableStartNum: int = 0
equationStartNum: int = 0
caretPos: CaretPosition = field(default_factory=lambda: CaretPosition(0, 0, 0))
binaryDataCount: int = 0
hangulFontDataCount: int = 0
...
@classmethod
def read_hwp_document(cls, file_path: str) -> bool:
# 1.
"""HWP 파일 읽기"""
if not olefile.isOleFile(file_path):
return False
ole = olefile.OleFileIO(file_path)
# 2.
doc_info_stream = ole.openstream('DocInfo')
doc_info_data = doc_info_stream.read()
# 3.
decompressed_data = zlib.decompress(doc_info_data, -15)
decompressed_data.decode('utf-8', errors="replace")
doc_info_bitstream = BitStream(decompressed_data)
return cls.read_doc_info(doc_info_bitstream)HWP 파일에서 DocInfo를 읽기 위해선 크게 3가지 단계를 거쳐야 합니다. 위 코드 예제를 통해 각 단계를 자세히 살펴보겠습니다.
- olefile 라이브러리를 이용해 HWP 파일의 내부 구조에 접근할 준비를 합니다.
- olefile 라이브러리를 이용해 DocInfo 스트림을 열어서 읽어들입니다.
- 마지막으로 읽어 들인 DocInfo 데이터를 zlib 라이브러리를 이용해서 압축을 해제하고 문자열로 변환한다.
이런 과정을 통해 DocInfo의 데이터를 최종적으로 확인할 수 있게 됩니다.
데이터 레코드 읽기
이제 읽어들인 HWP 파일의 DocInfo 데이터 영역을 아래의 레코드 구조 스펙에 따라 파싱하는 방법을 예제를 통해 살펴보겠습니다.
[그림 1] 레코드 구조 (공식 문서 [그림 45] 참조)
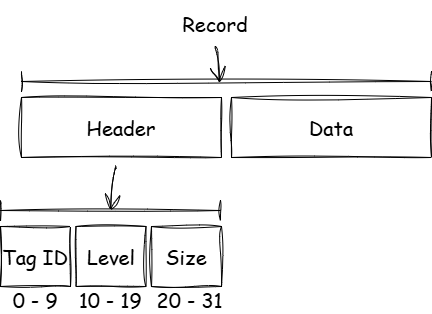
- Tag ID : 레코드가 나타내는 데이터의 종류로 10비트가 사용된다.
- Level : 연관된 레코드의 논리적인 묶음을 표현하기 위한 정보로 10비트가 사용된다.
- Size : 데이터 영역의 길이를 바이트 단위로 나타낸다. 4095 바이트 이상의 데이터 일 때 레코드 헤더에 DWORD가 추가된다.
1. 레코드 헤더 읽기
@dataclass
class Record:
tagID: int = 0
level: int = 0
size: int = 0
# 1.
@classmethod
def read_record(cls, tagID: int, bits: BitStream) -> bool:
"""32비트 읽어 레코드 헤더 파싱"""
record_bits = bits.read(32)
cls.tagID, cls.level, cls.size = cls.split_header_bits(record_bits.bytes)
if cls.tagID != tagID: # 읽어온 레코드가 예상과 다른 레코드일 경우
return False
# 3.
if cls.size == 0xFFF: # 4095, 확장 크기
size_bytes = bits.read(32).bytes
cls.size = bytes_to_int(size_bytes)
return True
...
# 2.
@staticmethod
def split_header_bits(bits: bytes) -> tuple[int, int, int]:
"""리틀엔디안으로 읽어 32비트 헤더 분할 (10bit, 10bit, 12bit)"""
num = struct.unpack('<I', bits)[0]
return (
(num >> 0) & 0x3FF,
(num >> 10) & 0x3FF,
(num >> 20) & 0xFFF
)레코드 헤더를 읽는 단계는 크게 3단계로 나뉩니다.
- 레코드 헤더에 해당하는 32비트를 읽는다. ([그림 1] 참고)
- 읽어온 헤더는 리틀 엔디안(Little-Endian) 방식으로 해석해야 하며 다음과 같이 3가지 필드로 분리한다.
- TagID (10비트) : 레코드의 종류를 나타내는 식별자
- Level (10비트) : 레코드의 논리적인 묶음을 표현하기 위한 정보
- Size (12비트) : 레코드 데이터의 길이
- 만약 위에서 읽어온 Size의 값이 4095(이진수로 1111 1111 1111) 라면 추가로 4바이트(DWORD)를 더 읽어와 실제 레코드의 크기로 사용한다.
이제 레코드를 읽는 방법을 알았으니 DocInfo에 저장된 레코드들을 실제로 읽어보겠습니다.
[표 2] 문서 정보의 데이터 레코드 (공식 문서 [표 13] 참조)
| Tag ID | Value | 의미 |
|---|---|---|
| HWPTAG_DOCUMENT_PROPERTIES | HWPTAG_BEGIN (0x010) | 문서 속성 |
| HWPTAG_ID_MAPPINGS | HWPTAG_BEGIN + 1 (0x011) | 아이디 매핑 헤더 |
| HWPTAG_BIN_DATA | HWPTAG_BEGIN + 2 (0x012) | BinData |
| HWPTAG_FACE_NAME | HWPTAG_BEGIN + 3 (0x013) | Typeface Name |
| … |
DocInfo 스트림을 읽기 시작하면, 가장 먼저 마주하게 되는 레코드 헤더는 다음과 같습니다.
- Tag ID = 16
- Level = 0
- Size = 26
이 정보를 바탕으로 [표 2] 문서 정보의 데이터 레코드를 확인해 보면 Tag ID는 HWPTAG_DOCUMENT_PROPERTIES에 해당함을 알 수 있습니다. 이는 현재 읽고 있는 레코드가 문서 속성에 대한 정보를 담고 있다는 의미입니다.

2. 레코드 헤더 정보를 이용하여 데이터 레코드 읽기
이전에 DocInfo 스트림에서 Tag ID가 16인 HWPTAG_DOCUMENT_PROPERTIES를 읽어왔으므로 [표 2] 문서 정보의 데이터 레코드를 참고해서 이 레코드에 저장된 데이터를 읽어보겠습니다.
[표 3] 문서 속성 (공식 문서 [표 14] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT16 | 2 | 구역 개수 |
| 문서 내 각종 시작번호에 대한 정보 | ||
| UINT16 | 2 | 페이지 시작 번호 |
| UINT16 | 2 | 각주 시작 번호 |
| UINT16 | 2 | 미주 시작 번호 |
| UINT16 | 2 | 그림 시작 번호 |
| UINT16 | 2 | 표 시작 번호 |
| UINT16 | 2 | 수식 시작 번호 |
| 문서 내 캐럿의 위치 정보 | ||
| UINT32 | 4 | 리스트 아이디 |
| UINT32 | 4 | 문단 아이디 |
| UINT32 | 4 | 문단 내에서의 글자 단위 위치 |
| 전체 길이 | 26 | |
문서 속성에 해당하는 HWPTAG_DOCUMENT_PROPERTIES에 어떤 데이터들이 저장되는지 확인할 수 있습니다. 이 정보를 기반으로 샘플 예제를 통해 데이터를 추출해 보겠습니다.
@dataclass
class Record:
...
@classmethod
def read(cls, bits: BitStream, size: int) -> bytes:
"""지정 크기만큼 데이터 읽기 (8의 배수만 허용)"""
if size % 8 == 0:
cls.size -= size // 8
return bits.read(size).bytes
raise ValueError("size must be multiple of 8")
...
@classmethod
def read_doc_info(cls, bits: BitStream) -> bool:
"""문서 정보 읽기"""
if not Record.read_record(HWPTAG_DOCUMENT_PROPERTIES, bits):
return False
# 구역 개수
cls.sectionCount = bytes_to_int(Record.read(bits, 16))
# 페이지 시작 번호
cls.pageStartNum = bytes_to_int(Record.read(bits, 16))
# 각주 시작 번호
cls.footnoteStartNum = bytes_to_int(Record.read(bits, 16))
# 미주 시작 번호
cls.endnoteStartNum = bytes_to_int(Record.read(bits, 16))
# 그림 시작 번호
cls.pictureStartNum = bytes_to_int(Record.read(bits, 16))
# 표 시작 번호
cls.tableStartNum = bytes_to_int(Record.read(bits, 16))
# 수식 시작 번호
cls.equationStartNum = bytes_to_int(Record.read(bits, 16))
# 문서 내 캐럿의 위치 정보
# 리스트 아이디
list_id = bytes_to_int(Record.read(bits, 32))
# 문단 아이디
para_id = bytes_to_int(Record.read(bits, 32))
# 문단 내에서의 글자 단위 위치
char_pos = bytes_to_int(Record.read(bits, 32))
cls.caretPos = CaretPosition(list_id, para_id, char_pos)
Record.end_record()
...
return True
제공된 샘플 코드를 통해 HWPTAG_DOCUMENT_PROPERTIES 레코드를 파싱 한 결과, 다음과 같은 문서 속성들을 확인할 수 있습니다.
- 구역 개수 = 1
- 각종 시작 번호 = 1
- 문서 내 캐럿 위치 정보
- 리스트 아이디 = 0
- 문단 아이디 = 0
- 문단 내에서 글자 단위 위치 = 32
이 결과를 통해 HWP 파일이 논리적으로 연관된 데이터를 레코드 형태로 저장하며, 각 레코드에는 헤더 정보가 포함되어 데이터의 종류와 길이를 명확하게 식별할 수 있도록 설계되었음을 보여줍니다.
BinData 정보 읽기
DocInfo 스트림에서 HWPTAG_DOCUMENT_PROPERTIES 레코드를 파싱 했으니, 이제 다음 레코드로 저장되는 HWPTAG_ID_MAPPINGS를 읽어볼 차례입니다. [표 2] 문서 정보의 데이터 레코드에 명시된 대로 이 레코드는 BinData나 FaceName과 같이 ID로 매핑되는 다양한 데이터들의 개수 정보를 담고 있습니다.
[표 4] 아이디 매핑 헤더 (공식 문서 [표 15] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| INT32 array[18] | 72 | 아이디 매핑 개수 (공식 문서 [표 16] 참조) |
| 전체 길이 | 72 | doc version에 따라 가변적 |
| 전체 길이 | 72 | doc version에 따라 가변적 |
[표 5] 아이디 매핑 개수 인덱스 (공식 문서 [표 16] 참조)
| 값 | 설명 |
|---|---|
| 0 | 바이너리 데이터 |
| 1 | 한글 글꼴 |
| 2 | 영어 글꼴 |
| … | |
| 17 | 변경추적 사용자 (5.0.3.2 이상) |
여기서 주목해야 할 부분은 HWPTAG_ID_MAPPINGS의 전체 길이가 72바이트이며 “doc version에 따라 가변적”이라는 설명입니다. 이는 HWP 포맷이 확장됨에 따라 파일 버전에 따라 이 레코드의 실제 길이가 달라질 수 있음을 시사합니다.
가변 데이터 처리 로직
HWP 포맷은 데이터가 순차적으로 정해진 스펙에 따라 저장되는 구조이므로 읽어 들인 데이터 길이가 레코드 헤더에 기록된 길이보다 작다면 그 차이만큼 스트림 포인터를 스킵 해야 합니다. 이렇게 해야 다음에 읽을 레코드의 순서가 꼬이지 않고 정확하게 파싱 할 수 있습니다.
이제 이 정보를 바탕으로 샘플 코드를 작성해서 HWPTAG_ID_MAPPINGS 레코드를 읽어 각 ID 매핑 개수 정보를 추출해 봅시다.
@dataclass
class Record:
...
@classmethod
def read_record(cls, tagID: int, bits: BitStream) -> bool:
"""32비트 읽어 레코드 헤더 파싱"""
record_bits = bits.read(32)
cls.tagID, cls.level, cls.size = cls.split_header_bits(record_bits.bytes)
if cls.tagID != tagID: # 읽어온 레코드가 예상과 다른 레코드일 경우
return False
if cls.size == 0xFFF: # 4095, 확장 크기
size_bytes = bits.read(32).bytes
cls.size = bytes_to_int(size_bytes)
return True
@classmethod
def end_record(cls) -> None:
if cls.size != 0:
print('레코드의 size만큼 데이터를 모두 읽어오지 않았습니다.')
cls.skip(cls.size)
cls.tagID = 0
cls.level = 0
cls.size = 0
@classmethod
def read(cls, bits: BitStream, size: int) -> bytes:
"""지정 크기만큼 데이터 읽기 (8의 배수만 허용)"""
if size % 8 == 0:
cls.size -= size // 8
return bits.read(size).bytes
raise ValueError("size must be multiple of 8")
@classmethod
def skip(cls, bits: BitStream, size: int) -> None:
"""데이터 건너뛰기"""
cls.read(bits, size)
...
@classmethod
def read_id_mapping(cls, bits: BitStream) -> bool:
"""ID 매핑 정보 읽기"""
if not Record.read_record(HWPTAG_ID_MAPPINGS, bits):
return False
cls.binaryDataCount = bytes_to_int(Record.read(bits, 32))
cls.hangulFontDataCount = bytes_to_int(Record.read(bits, 32))
cls.englishFontDataCount = bytes_to_int(Record.read(bits, 32))
# 한자, 일어, 기타, 기호, 사용자 글꼴 (5개) 건너뛰기
Record.skip(bits, 32 * 5)
# 테두리/배경 등 10개 건너뛰기
Record.skip(bits, 32 * 10)
Record.end_record()
return True제공된 샘플 예제를 통해 DocInfo 스트림 내의 HWPTAG_ID_MAPPINGS 레코드를 읽어보면 [표 4] 아이디 매핑 헤더와 [표 5] 아이디 매핑 개수 인덱스에 명시된 대로 다양한 데이터들의 개수 정보를 가져올 수 있습니다.

코드의 실행 결과, 샘플 파일에서 다음과 같은 값들이 추출됨을 확인할 수 있습니다.
- 바이너리 데이터 개수 = 2
- 한글 글꼴 데이터 개수 = 2
- 등등
HWPTAG_ID_MAPPINGS 레코드를 성공적으로 파싱하여 바이너리 데이터, 한글 글꼴 등의 개수를 확인했습니다. 이제 이 정보를 활용하여 각 유형에 해당하는 실제 데이터를 파싱 할 차례입니다.
[표 6] 바이너리 데이터 (공식 문서 [표 17] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT16 | 2 | 속성 (공식 문서 [표 18] 참조) |
| WORD | 2 | Type이 “LINK”일 때, 연결 파일의 절대 경로 길이 (len1) |
| WCHAR array[len1] | 2 x len1 | Type이 “LINK”일 때, 연결 파일의 절대 경로 |
| WORD | 2 | Type이 “LINK”일 때, 연결 파일의 상대 경로 길이 (len2) |
| WCHAR array[len2] | 2 x len2 | Type이 “LINK”일 때, 연결 파일의 상대 경로 |
| UINT16 | 2 | Type이 “EMBEDDING”이거나 “STORAGE”일 때 BINDATASTORAGE에 저장된 바이너리 데이터의 아이디 |
| WORD | 2 | Type이 “EMBEDDING”일 때 바이너리 데이터의 형식 이름의 길이 (len3) |
| WCHAR array[len3] | 2 x len3 | Type이 “EMBEDDING”일 때 extension(“.” 제외) |
| 그림의 경우 jpg, bmp, gif | ||
| OLE의 경우 ole | ||
| 전체 길이 | 가변 |
[표 7] 바이너리 데이터 속성 (공식 문서 [표 18] 참조)
| 범위 | 구분 | 값 | 설명 |
|---|---|---|---|
| bit 0 ~ 3 | Type | 0x0000 0x0001 0x0002 | LINK 그림 외부 파일 참조 EMBEDDING 그림 파일 포함 STORAGE, OLE 포함 |
| bit 4 ~ 5 | 압축 | 0x0000 0x0010 0x0020 | 스토리지의 디폴트 모드 따라감 무조건 압축 무조건 압축하지 않음 |
| bit 8 ~ 9 | 상태 | 0x0000 0x0100 0x0200 0x0400 | 아직 access 된 적이 없는 상태 access에 성공하여 파일을 찾은 상태 access가 실패한 에러 상태 링크 access가 실패했으나 무시된 상태 |
HWPTAG_BIN_DATA는 [표 6] 바이너리 데이터에 상세히 정의되어 있으며, 여기서 가장 중요한 부분은 첫 2바이트의 UINT16 속성 값에 따라 레코드의 나머지 구조가 가변적이라는 점입니다. 이 속성 값은 [표 7] 바이너리 데이터 속성에 자세히 설명되어 있습니다.
이러한 스펙을 바탕으로 HWPTAG_BIN_DATA를 파싱하는 샘플 코드를 작성해 보겠습니다.
@classmethod
def read_bin_data_item(cls, bits: BitStream) -> bool:
"""바이너리 데이터 항목 읽기"""
binary_data = 0
while binary_data < cls.binaryDataCount:
binary_data += 1
if not Record.read_record(HWPTAG_BIN_DATA, bits):
return False
binary_data_flags = bytes_to_int(Record.read(bits, 16))
if (binary_data_flags & 0x0000000F) == 0:
# 파일 경로 처리
abs_path_len = bytes_to_int(Record.read(bits, 16))
abs_path = Record.read(bits, 16 * abs_path_len).decode('utf-16')
rel_path_len = bytes_to_int(Record.read(bits, 16))
rel_path = Record.read(bits, 16 * rel_path_len).decode('utf-16')
else:
# 바이너리 데이터 ID 및 확장자 처리
id = bytes_to_int(Record.read(bits, 16))
ext_len = bytes_to_int(Record.read(bits, 16))
ext = Record.read(bits, 16 * ext_len).decode('utf-16')
Record.end_record()
return True이 샘플 코드를 보시면 HWPTAG_DOCUMENT_PROPERTIES나 HWPTAG_ID_MAPPINGS 같은 단순한 속성값의 나열과 달리, HWPTAG_BIN_DATA에는 경로와 같은 가변 길이 문자열이 포함되어 있습니다. 이러한 바이너리 포맷에서 문자열의 길이를 알 수 없는 문제를 해결하기 위해, HWP 포맷은 문자열이 나타나는 부분마다 문자열의 길이 정보를 먼저 기록하고, 그 길이만큼 실제 문자열 데이터를 읽어오는 방식을 사용하고 있습니다.
글꼴 정보 읽기
DocInfo 스트림에서 HWPTAG_DOCUMENT_PROPERTIES 레코드와 HWPTAG_BIN_DATA 다음으로 저장되는 정보는 HWPTAG_FACE_NAME입니다.
[표 8] 글꼴 (공식 문서 [표 19] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| BYTE | 1 | 글꼴 속성 |
| WORD | 2 | 글꼴 이름 길이 (len1) |
| WCHAR array[len1] | 2 x len1 | 글꼴 이름 |
| BYTE | 1 | 대체 글꼴 유형 |
| WORD | 2 | 대체 글꼴 이름 길이 (len2) |
| WCHAR array[len2] | 2 x len2 | 대체 글꼴 이름 |
| BYTE array[10] | 10 | 글꼴 유형 정보 |
| WORD | 2 | 기본 글꼴 이름 길이 (len3) |
| WCHAR array[len3] | 2 x len3 | 기본 글꼴 이름 |
| 전체 길이 | 가변 |
[표 9] 글꼴 속성 (공식 문서 [표 20] 참조)
| 값 | 설명 |
|---|---|
| 0x80 | 대체 글꼴 존재 여부 |
| 0x40 | 글꼴 유형 정보 존재 여부 |
| 0x20 | 기본 글꼴 존재 여부 |
[표 10] 대체 글꼴 유형 (공식 문서 [표 21] 참조)
| 값 | 설명 |
|---|---|
| 0 | 원래 종류를 알 수 없을 때 |
| 1 | 트루타입 글꼴(TTF) |
| 2 | HWP 전용 글꼴(HFT) |
글꼴 정보도 BinData와 마찬가지로 단순히 속성값만 나열된 게 아닙니다. 글꼴의 속성값에 따라 대체 글꼴 정보, 글꼴 유형 정보, 기본 글꼴 정보와 같은 추가 데이터를 읽어와야 합니다.
래는 위에서 언급된 정보를 토대로 글꼴 정보를 읽어오는 샘플 코드를 작성해 보겠습니다.
@classmethod
def read_font_item(cls, bits: BitStream) -> bool:
"""폰트 데이터 항목 읽기"""
font_data = 0
while font_data < cls.hangulFontDataCount:
font_data += 1
if not Record.read_record(HWPTAG_FACE_NAME, bits):
return False
font_flags = bytes_to_int(Record.read(bits, 8))
font_len = bytes_to_int(Record.read(bits, 16))
font_name = Record.read(bits, 16 * font_len).decode('utf-16')
if font_flags & 0x80:
# 대체 글꼴
font_alt_flags = bytes_to_int(Record.read(bits, 8))
font_alt_len = bytes_to_int(Record.read(bits, 16))
font_alt_name = Record.read(bits, 16 * font_alt_len).decode('utf-16')
if font_flags & 0x40:
# 글꼴 유형 정보
Record.skip(bits, 10 * 8)
if font_flags & 0x20:
# 기본 글꼴 이름
base_len = bytes_to_int(Record.read(bits, 16))
base_name = Record.read(bits, 16 * base_len).decode('utf-16')
Record.end_record()
return TrueHWP 포맷은 사용된 모든 폰트 정보를 파일에 기록하고 단순히 폰트 이름만 저장하는 것이 아니라, 해당 폰트가 시스템에 없을 경우를 대비하여 대체 글꼴 정보와 글꼴 유형 정보까지 추가적으로 저장하는 구조입니다.
이러한 설계 덕분에 특정 폰트가 사용자 시스템에 설치되어 있지 않더라도 호환성을 유지하며 내용을 올바르게 표시할 수 있습니다.
마치며
지금까지 공식 문서를 기반으로 Python을 활용하여 실제 HWP 파일을 파싱하는 방법을 알아보았습니다. 이 과정을 통해 HWP 문서가 단순히 텍스트와 이미지를 나열하는 것이 아니라, 체계적인 레코드 구조로 구성되어 있음을 확인할 수 있었습니다.
다음 시간에는 이번에 작성한 샘플 코드를 활용해서 이보다 복잡한 본문 정보를 직접 읽어보며, HWP 문서의 핵심 내용이 어떤 방식으로 저장되고 구성되는지 확인해 보는 시간을 갖도록 하겠습니다.
📌 한/글 문서 파일 형식 시리즈
1편: 한/글 문서 파일 형식 : HWP 포맷 구조 살펴보기↗
2편: 한/글 문서 파일 형식 : HWPX 포맷 구조 살펴보기↗
👉 3편: 한/글 문서 파일 형식: Python을 통한 HWP 포맷 파싱하기 (1)↗
4편: 한/글 문서 파일 형식: Python을 통한 HWPX 포맷 파싱하기 (1)↗