요약
인공지능 산업은 단일 LLM 중심에서 벗어나 다양한 특화 모델들의 조합과 오케스트레이션을 통해 차세대 프로덕션급 AI로 진화하고 있습니다.
시작하며
본 글은 인공지능 산업의 패러다임이 단일 거대 언어 모델(LLM) 중심에서 다각화된 조합형(Composable) AI 모델 생태계로 전환되는 중대한 변화를 심층적으로 분석합니다. GPT-4, Llama 3.1과 같은 LLM은 복잡한 추론의 핵심으로 자리 잡았으나, 비용, 지연 시간, 도메인 특화성의 한계로 인해 새로운 아키텍처의 필요성이 대두되었습니다.
이에 본 글은 8가지 핵심 모델 유형(LLM, LAM, MoE, SLM, MLM, VLM, LCM, SAM)에 대한 기술적 심층 분석을 제공하며, 각 모델의 기반 아키텍처와 작동 원리를 해부합니다. 본 글의 핵심 논지는 차세대 프로덕션급 AI의 미래가 단일 ‘마스터 모델’이 아닌, 특화된 구성 요소들의 지능적인 오케스트레이션에 있다는 것입니다.
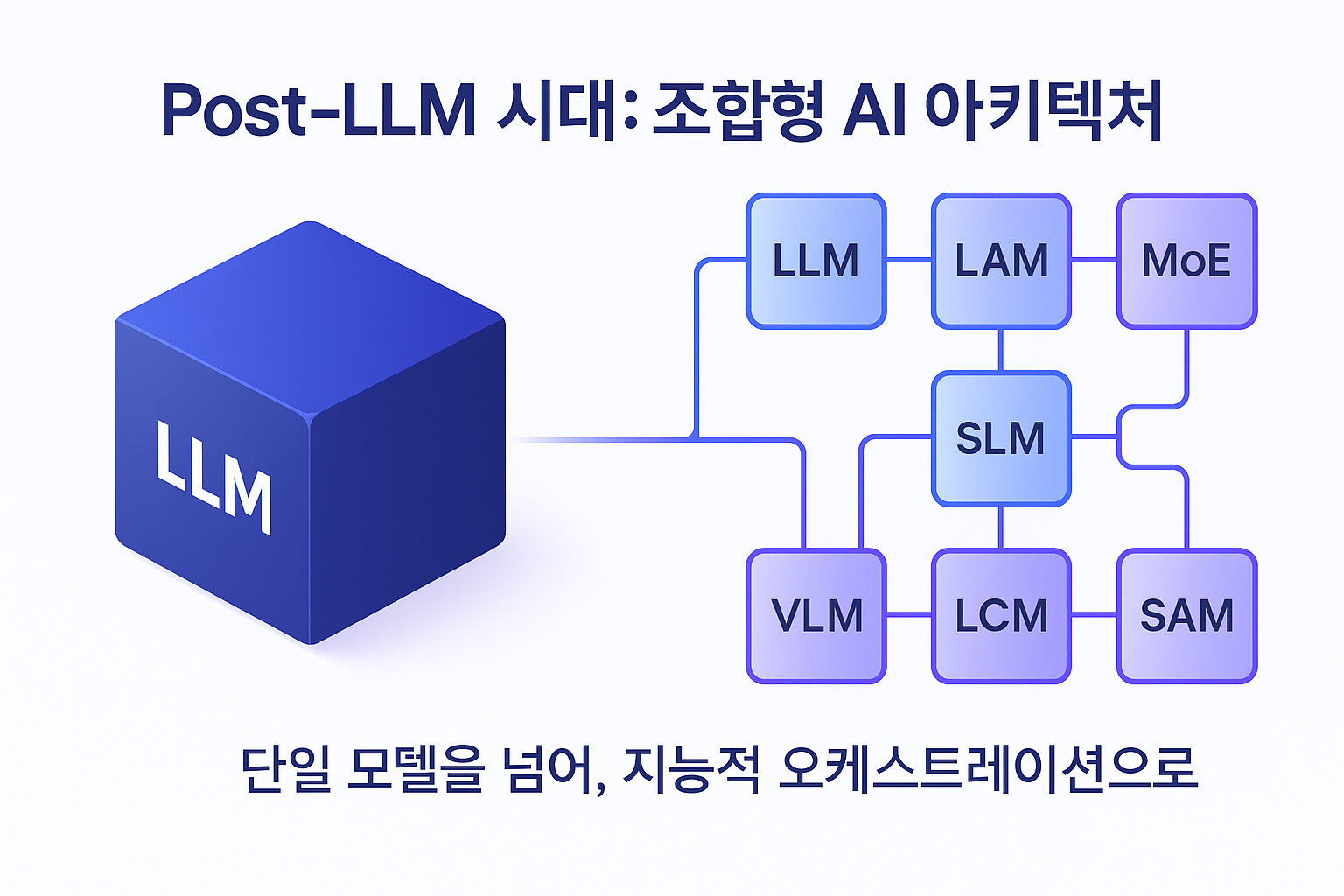
필연적 다각화: LLM 모놀리스를 넘어서
1. 기반: 범용 LLM의 혁신적 영향력
2023년부터 2024년까지의 AI 혁신은 거대 언어 모델(LLM)이 명백히 주도했습니다. ChatGPT, Claude, Gemini와 같은 모델들은 대화, 콘텐츠 생성, 코드 작성 등에서 전례 없는 유창함을 보여주며 범용 지능의 가능성을 제시했고, 이는 AI 상호작용의 새로운 기준을 정립했습니다. 이러한 성공은 시장에서 “충분히 큰 단일 모델이 광범위한 문제를 해결할 수 있다”라는 기대를 낳았으며, 이는 파라미터 수와 학습 데이터 규모를 확장하는 경쟁으로 이어졌습니다.
2. 운영상의 한계: LLM 스케일링의 기술적 분석
LLM의 범용성은 강력하지만, 실제 프로덕션 환경에 적용하는 과정에서 네 가지 핵심적인 기술적 한계가 드러났습니다.
- 비용 (Cost): 비용 문제는 밀집(dense) 트랜스포머 아키텍처의 본질적인 특성에서 기인합니다. Llama 3.1 405B와 같은 모델은 단일 토큰을 생성할 때마다 4,050억 개의 파라미터를 모두 활성화해야 합니다. 이는 막대한 학습 비용(3,930만 GPU 시간)과 높은 추론 비용으로 직결되어, 처리량이 많거나 마진이 낮은 애플리케이션에서는 경제적으로 지속 불가능합니다.
- 지연 시간 (Latency): 밀집 모델의 순차적이고 자기회귀적인(auto-regressive) 토큰 생성 방식은 본질적인 지연 시간을 유발합니다. 이는 대화형 UI, 검색 자동 완성, 온디바이스 비서와 같이 실시간 응답성이 중요한 애플리케이션에서는 수용하기 어려운 문제입니다.
- 환각 및 정확성 (Hallucination & Accuracy): 환각은 ‘버그’가 아니라, 확률적 단어 예측기로 훈련된 모델의 근본적인 결과물입니다. 높은 사실성이 요구되는 작업에서 이러한 생성적 특성은 신뢰성을 저해하는 심각한 약점이 됩니다.
- 보안 및 프라이버시 (Security & Privacy): 최첨단 LLM의 거대한 크기는 필연적으로 클라우드 기반 배포를 요구합니다. 이는 민감 데이터를 다루거나 엣지 디바이스에서 오프라인 기능이 필요한 애플리케이션에 보안 및 개인정보 보호 문제를 야기합니다.
3. 새로운 명제: 아키텍처 특화가 프로덕션급 AI로 가는 길
AI 산업은 이제 ‘스케일업'(더 큰 밀집 모델) 전략에서 ‘스케일아웃'(다양하고 특화된 모델) 전략으로 전환하고 있습니다. 이러한 변화는 단순히 새로운 트렌드가 아니라, AI 엔지니어링이 성숙해지는 과정에서 나타나는 필연적인 발전입니다.
성숙한 소프트웨어 엔지니어링은 모듈성, 관심사 분리, 적재적소의 도구 사용이라는 원칙 위에 구축됩니다. 예를 들어, 트랜잭션 무결성을 위해 관계형 데이터베이스를 사용하고 비정형 데이터를 위해 문서 저장소를 사용하는 것처럼 말입니다. 모든 문제에 단일하고 거대한 범용 LLM을 적용하는 것은 이러한 원칙에 위배되며, 비효율성, 높은 운영 비용, 그리고 많은 사용 사례에서 최적화되지 않은 성능을 초래합니다.
따라서 AI 모델의 다각화는 AI 엔지니어링의 성숙을 반영합니다. 이는 단일 ‘만능 칼'(LLM)에 의존하는 대신, 행동을 위한 LAM, 엣지를 위한 SLM 등 특정 목적에 최적화된 다양한 모델들이 조합되는 ‘도구 상자’와 같은 생태계로 발전하고 있음을 의미합니다.
특화 AI 모델의 기술적 분류
개발자와 설계자가 이 복잡한 모델 생태계를 효과적으로 탐색할 수 있도록, 각 모델 유형의 역할과 특성을 요약한 비교 분석 표를 제시합니다. 이 표는 이어지는 심층 분석의 ‘범례’ 역할을 하여, 각 기술의 전략적 맥락을 신속하게 파악하는 데 도움을 줄 것입니다.
[표 1] 특화 AI 모델 아키텍처 비교 분석
| 유형 | 핵심 원리 | 주요 아키텍처 특징 | 주요 사용 사례 | 비용/성능 프로파일 |
|---|---|---|---|---|
| LLM | 대규모 자기회귀 시퀀스 예측을 통한 범용 지능 | ㆍDecoder-only Transformer ㆍGQA ㆍTool-Use API | 복잡한 추론, 계획, 콘텐츠 합성 | 고비용, 고성능, 고지연 |
| LAM | 언어 이해와 실제 행동 실행을 상태 기반 루프로 연결 | ㆍReAct 프레임워크 ㆍ외부 메모리 ㆍ플래너 ㆍ도구 실행기 | 자율 에이전트, 워크플로 자동화 | LLM 기반, 상태 관리에 추가 비용 발생 |
| MoE | 조건부 연산을 통한 대규모 파라미터 및 비용 효율성 확보 | ㆍ희소 활성화(Sparse Activation) ㆍ라우팅 네트워크 ㆍ전문가(Expert) FFN | 대규모 서비스 백엔드, 비용 효율적 추론 | 저비용, 고성능, 저지연 (활성 파라미터 기준) |
| SLM | 모델 압축을 통한 엣지/온디바이스 환경 최적화 | ㆍPruning ㆍQuantization ㆍKnowledge Distillation | 온디바이스 비서, 실시간 UI, 프라이버시 중심 앱 | 초저비용, 중성능, 초저지연 |
| MLM | 양방향 문맥 이해를 통한 고품질 의미 표현 학습 | ㆍBidirectional Encoder ㆍContrastive Learning | RAG 임베딩, 검색, 분류, 정보 추출 | 생성 불가, 임베딩 생성에 저비용/고효율 |
| VLM | 시각과 언어를 단일 End-to-End 모델로 통합 | ㆍ멀티모달 퓨전 ㆍVision Transformer + LLM | 멀티모달 문서 이해, 이미지 Q&A, OCR-free 처리 | 고비용, 복합적 성능, 파이프라인 대비 저지연 |
| LCM | 확산 모델 증류를 통한 실시간 고품질 이미지 생성 | ㆍLatent Space Consistency ㆍPF-ODE 해결 | 실시간 생성형 미리 보기, 인터랙티브 디자인 도구 | 생성 속도 수십 배 향상, 품질은 원본 대비 미세 저하 가능 |
| SAM | 프롬프트 기반 범용 제로샷 객체 분할 | ㆍViT 인코더 ㆍ경량 디코더 ㆍ스트리밍 메모리 (SAM 2.0) | 문서 레이아웃 분석, 비디오 객체 추적, 이미지 편집 | 분할 작업에 특화, 실시간에 가까운 속도 |
1. 추론 코어 (LLM – Large Language Model)
- 핵심 원리: 대규모 자기회귀 시퀀스 예측을 통해 범용 지능을 구현합니다.
- 아키텍처 심층 분석 (Llama 3.1): Llama 3.1은 표준적인 Decoder-only 트랜스포머 아키텍처를 기반으로 하지만, 대규모 확장을 위한 핵심적인 최적화가 적용되었습니다.
- SwiGLU 활성화 함수: ReLU/GeLU 대신 사용하여 성능을 개선합니다.
- 회전 위치 임베딩 (RoPE): 절대적 위치 임베딩 대신 상대적 위치 정보를 인코딩하여 긴 시퀀스 처리에 더 효과적입니다.
- RMSNorm: Layer Normalization을 단순화하여 학습 안정성과 속도를 향상시킵니다.
- Grouped-Query Attention (GQA): 여러 쿼리 헤드가 단일 키/값 헤드를 공유하는 핵심 최적화 기술입니다. 이는 긴 컨텍스트를 처리할 때 추론의 주된 병목 지점인 KV 캐시의 크기를 극적으로 줄여줍니다. 이 기술은 Llama 3.1이 128k라는 긴 컨텍스트 창을 효율적으로 지원할 수 있게 하는 핵심 요소입니다.
- 실행 가능성의 진화 (Tool Use): LLM은 단순한 텍스트 생성기를 넘어 외부 시스템과 상호작용하는 추론 엔진으로 발전하고 있습니다.
- OpenAI의 Function Calling: 개발자가 도구에 대한 엄격한 JSON 스키마를 정의하면, 모델이 호출할 함수명과 인자를 담은 JSON 객체를 반환하는 구조적 접근 방식입니다. 이는 높은 신뢰성과 예측 가능성을 제공합니다.
- Anthropic의 Tool Use: 도구가 대화의 맥락 안에서 특수 블록을 통해 정의되는 더 유연하고 대화적인 접근 방식입니다. 이는 더 자연스러운 인라인 도구 연계와 추론을 가능하게 합니다.
2. 행동 엔진 (LAM – Language Action Model)
- 핵심 원리: 언어 이해와 구체적인 행동 실행을 상태 기반의 목표 지향적 루프로 연결합니다.
- 아키텍처 심층 분석:
- ReAct 프레임워크: 많은 에이전트의 기본 제어 루프는 사고(Thought) → 행동(Action) → 관찰(Observation)입니다. 모델은 먼저 언어적 추론 과정(“사고”)을 생성하고, 그다음 API 호출과 같은 행동을 수행하며, 그 결과를 관찰한 후 다시 추론합니다. 이 구조는 에이전트의 행동을 해석 가능하게 만들고, 피드백에 따라 동적으로 계획을 수정할 수 있게 합니다.
- Toolformer의 자기 지도 학습 (Self-Supervised Learning): LLM이 사전 학습 단계에서 스스로 API 호출 시점과 방법을 학습하는 혁신적인 개념입니다. 이는 학습 데이터에 API 호출을 증강함으로써 이루어지며, Llama 3.1이나 GPT-4와 같은 최신 모델에 내장된 도구 사용 기능의 이론적 기반이 되었습니다.
- 장기 기억 (Long-Term Memory): 상태를 유지하는 에이전트의 핵심 구성 요소로, LLM의 컨텍스트 창을 넘어섭니다. 이는 주로 벡터 데이터베이스와 같은 외부 시스템으로 구현되며, 다음과 같이 분류됩니다.
- 일화 기억 (Episodic Memory): 특정 과거 상호작용이나 사건을 회상합니다.
- 의미 기억 (Semantic Memory): RAG 등을 통해 구조화된 사실적 지식을 저장하고 검색합니다.
- 절차 기억 (Procedural Memory): 학습된 기술이나 워크플로를 저장하고 회상합니다. LongMem과 같은 프레임워크는 지속적인 재처리 없이 장기 컨텍스트를 효율적으로 캐시하고 검색하기 위한 분리된 아키텍처를 제안합니다.
3. 효율성 엔진 (MoE – Mixture of Experts)
- 핵심 원리: 희소(sparse) 조건부 연산을 통해 일정한 계산 비용으로 막대한 파라미터 수를 달성합니다.
- 아키텍처 심층 분석:
- MoE 레이어는 단일의 밀집 순방향 신경망(FFN)을 다수의 희소 ‘전문가’ FFN과 ‘라우터’ 또는 ‘게이팅 네트워크’로 대체합니다.
- 각 입력 토큰에 대해 라우터는 가장 관련성 높은 전문가들을 계산하고, 그중 소수(일반적으로 상위 2개)만 활성화합니다. 이 전문가들의 출력이 결합되어 최종 결과가 됩니다.
- Mixtral 8x7B: 간단하지만 효과적인 Top-k 라우팅 메커니즘을 사용합니다. 레이어 당 8개의 전문가를 가지지만, 주어진 토큰에 대해 2개만 활성화하여 더 작은 모델의 추론 속도로 훨씬 큰 밀집 모델의 성능을 달성합니다.
- DeepSeek-V2: 더 진보된 DeepSeekMoE 아키텍처를 채택합니다. 이는 공통 지식을 처리하고 중복을 완화하기 위해 일부 ‘공유 전문가’를 분리하고, 이와 함께 특화된 ‘라우팅 된 전문가’를 둡니다. 또한, Multi-head Latent Attention (MLA)를 도입하여 KV 캐시를 잠재 벡터로 압축함으로써 긴 컨텍스트에 대한 추론 효율을 극적으로 향상시킵니다.
- MoE는 ‘모델’이라는 개념 자체의 근본적인 전환을 의미합니다. 이는 단일한 두뇌가 아니라, 동적이고 주문형으로 소집되는 전문가 위원회와 같습니다. 밀집 모델은 아무리 간단한 생각이라도 전체 뇌를 사용해야 하는 박식한 천재와 같습니다. 이는 강력하지만 비효율적입니다. 반면 MoE 모델은 언어학자, 수학자, 코더와 같은 전문가들로 구성된 위원회에 비유할 수 있으며, 라우터가 의장 역할을 하여 문제의 각 부분을 가장 관련성 있는 전문가에게 전달합니다. 이는 모델의 ‘지식’이 단순히 저장되는 것을 넘어, 조직화되고 주소 지정 가능하게 됨을 의미합니다. 이는 모듈식 업데이트(전체 모델 재학습 없이 단일 전문가 추가/미세 조정), 향상된 해석 가능성(어떤 ‘전문가’가 결정에 사용되었는지 설명), 심지어 단일 작업을 위해 다른 모델의 전문가를 동적으로 구성하는 것과 같은 미래의 엄청난 가능성을 열어줍니다.
4. 엣지 엔진 (SLM – Small Language Model)
- 핵심 원리: 리소스가 제한된 디바이스에서 유능한 언어 처리를 제공하여 낮은 지연 시간, 개인정보 보호, 오프라인 기능을 실현합니다.
- 아키텍처 심층 분석 (모델 압축 기술): SLM은 단순히 작은 LLM이 아니라, 기본 아키텍처에 의도적인 모델 압축 기술을 적용한 결과물입니다.
- 가지치기 (Pruning): 학습된 네트워크에서 중복되거나 중요하지 않은 파라미터(가중치, 뉴런, 전체 레이어)를 제거합니다. 이는 개별 가중치를 제거하는 비구조적 방식과 전체 행/필터를 제거하는 구조적 방식으로 나뉩니다.
- 양자화 (Quantization): 모델의 가중치와 활성화 값의 수치 정밀도를 낮춥니다(예: 32비트 부동소수점에서 8비트 또는 4비트 정수로). 이는 모델 크기를 줄이고, 특히 특화된 하드웨어에서 계산을 가속화합니다.
- 지식 증류 (Knowledge Distillation): 더 작고 ‘학생’ 모델(SLM)이 더 크고 유능한 ‘교사’ 모델(LLM)의 출력 분포(logits)를 모방하도록 학습시킵니다. 학생 모델은 교사로부터 ‘소프트 레이블’을 학습하여, 하드 레이블만으로 학습할 때보다 더 미묘한 정보를 포착합니다. Microsoft의 Phi-3 시리즈는 고품질의 선별된 합성 ‘교과서’ 데이터를 사용하는 지식 증류의 한 형태를 통해 작은 규모에서도 놀라운 성능을 달성합니다.
5. 이해 코어 (MLM – Masked Language Model)
- 핵심 원리: 텍스트 생성이 아닌, 의미론적 이해와 표현을 위해 깊은 양방향 문맥을 학습합니다.
- 아키텍처 심층 분석:
- 다음 단어를 예측하는 자기회귀 LLM과 달리, BERT와 같은 MLM은 문장 중간의 “ 토큰을 예측하도록 학습됩니다. 이는 모델이 왼쪽과 오른쪽 문맥을 동시에 학습하게 하여, 깊은 이해가 필요한 작업에서 탁월한 성능을 발휘하게 합니다.
- 현대적 적용 (RAG 임베딩): MLM은 생성에 사용되지 않지만, 그 인코더 아키텍처는 RAG 시스템에 사용되는 최첨단 텍스트 임베딩 모델의 기반이 됩니다.
- E5와 대조 학습 (Contrastive Learning): E5(EmbEddings from bidirEctional Encoder rEpresentations)와 같은 모델은 약지도 대조 사전학습(weakly-supervised contrastive pre-training)을 사용하여 학습됩니다. 이 과정은 다음을 포함합니다.
- 약한 긍정적 관계를 가진 방대한 텍스트 쌍 데이터 셋(CCPairs, 예: Reddit 게시물 제목과 인기 댓글)을 수집합니다.
- 모델이 이러한 ‘긍정적 쌍’의 벡터 표현을 임베딩 공간에서 서로 가깝게 만들고, ‘부정적'(무작위로 샘플링된) 쌍과는 멀어지도록 학습시킵니다. 이것이 대조 학습의 핵심입니다.
- 명령어 튜닝 (Instruction Tuning): E5는 비대칭 검색 작업의 성능을 크게 향상시키기 위해 입력에 “query: ” 또는 “passage: “와 같은 접두사를 붙여 쿼리와 문서에 대한 별개의 표현을 생성합니다.
6. 인식 엔진 (VLM – Vision Language Model)
- 핵심 원리: 시각적 인식과 언어적 추론을 단일 End-to-End 모델로 통합합니다.
- 아키텍처 심층 분석 (GPT-4o의 전환):
- 과거의 접근 방식: 이미지 인코더(CLIP 등), LLM, OCR 등 별도의 모델을 파이프라인으로 연결했습니다. 이는 비효율적이며 모델 간의 경계에서 정보 손실이 발생합니다.
- End-to-End 융합 (GPT-4o): GPT-4o는 텍스트, 오디오, 이미지 입력을 단일 신경망 내에서 처리합니다. 이미지는 ViT처럼 패치로 나뉘어 텍스트 토큰과 함께 시퀀스로 처리됩니다. 이를 통해 모델의 셀프 어텐션 메커니즘이 단어와 이미지의 특정 부분 사이의 관계를 직접 이해하는 깊은 교차 모달 연결을 생성할 수 있습니다.
- 장점: 이 통합 아키텍처는 지연 시간을 극적으로 줄이고 훨씬 더 풍부한 이해를 가능하게 합니다. 모델은 오디오의 톤을 인식하고, 시각적 뉘앙스를 이해하며, 여러 양식을 매끄럽게 혼합한 출력을 생성할 수 있습니다.
7. 실시간 생성 (LCM – Latent Consistency Model)
- 핵심 원리: 수백 단계 대신 몇 단계만으로 최종 출력을 예측하도록 학습하여 생성형 확산 모델을 극적으로 가속화합니다.
- 아키텍처 심층 분석:
- 확산 모델의 문제: 표준 확산 모델(Stable Diffusion 등)은 이미지를 생성하기 위해 수많은 단계(보통 50-1000회)에 걸친 반복적인 노이즈 제거 과정이 필요하기 때문에 속도가 느립니다.
- LCM의 해결책 (일관성 증류): LCM은 사전 학습된 잠재 확산 모델(LDM)을 증류하여 생성됩니다. 핵심 아이디어는 생성 과정을 확률 흐름 상미분 방정식(PF-ODE)을 푸는 것으로 재구성하는 것입니다.
- LCM은 이 ODE 궤적 상의 어떤 지점이든 그 종점(최종 깨끗한 이미지)으로 직접 매핑하도록 학습됩니다. 이 속성을 ‘일관성(consistency)’이라고 합니다. 이 매핑을 학습함으로써 모델은 느린 반복적 노이즈 제거 과정을 건너뛰고, 단 1 – 4 단계만으로 노이즈에서 고품질 이미지로 직접 도약할 수 있습니다.
8. 분할 엔진 (SAM – Segment Anything Model)
- 핵심 원리: 모든 이미지나 비디오의 모든 객체에 대해 일반화된, 프롬프트 가능한, 제로 샷 객체 분할을 수행합니다.
- 아키텍처 심층 분석 (SAM -> SAM 2.0):
- SAM 1.0: 무거운 ViT 이미지 인코더와 가볍고 실시간으로 작동하는 프롬프트 인코더 및 마스크 디코더로 구성된 분리된 아키텍처입니다. 1,100만 개의 이미지와 10억 개의 마스크로 구성된 방대한 데이터셋으로 학습되어 본 적 없는 객체에도 일반화할 수 있었습니다.
- SAM 2.0의 진화: 핵심 혁신은 비디오 도메인으로의 확장입니다. 이는 세션별 스트리밍 메모리 모듈을 추가함으로써 달성됩니다.
- 메모리 인코더와 메모리 뱅크를 포함하는 이 모듈은 이전 프레임의 정보(객체 마스크 및 특징)를 기반으로 현재 프레임의 처리를 조건화합니다. 이를 통해 SAM 2.0은 원본 SAM이 할 수 없었던 시간적 일관성을 유지하고 가려짐(occlusion) 상황에서도 객체를 추적할 수 있습니다. 이는 SAM 아키텍처를 비디오 도메인으로 자연스럽게 일반화한 것입니다.
Conclusion
AI 산업은 단일 거대 언어 모델(LLM)이 모든 문제를 해결할 것이라는 초기 기대를 넘어, 특정 작업에 고도로 최적화된 모델들을 조합하는 성숙한 단계로 진입하고 있습니다. LLM이 여전히 복잡한 추론의 중심축 역할을 하지만, 비용, 속도, 정확성, 보안 등 현실적인 제약으로 인해 LAM, SLM, MoE, VLM과 같은 특화 모델의 중요성이 커지고 있습니다.
미래의 AI 기술 패러다임은 이러한 다양한 모델들을 지능적으로 오케스트레이션 하여, 각 구성 요소의 강점을 극대화하는 조합형(Composable) 아키텍처가 주도할 것입니다. 이는 더 효율적이고, 강력하며, 다양한 실제 환경에 적용 가능한 AI 솔루션의 등장을 예고합니다.
References
- Adept. (n.d.). ACT-1 Technical Overview.
- Anthropic. (n.d.).(https://docs.anthropic.com/en/docs/agents-and-tools/tool-use/overview ). Anthropic Developer Docs.
- Dao, Q., Doan, K., Liu, D., Le, T., & Metaxas, D. (2025).(https://arxiv.org/abs/2502.01441 ). arXiv.
- DeepSeek AI. (2024).(https://arxiv.org/pdf/2405.04434). arXiv.
- Hugging Face. (n.d.). Embedding Leaderboards.
- Hugging Face. (n.d.).(https://huggingface.co/meta-llama/Llama-3.1-405B ).
- Luo, S., Tan, Y., Huang, L., Li, J., & Zhao, H. (2023).(https://arxiv.org/html/2310.04378 ). arXiv.
- Luo, S., et al. (2023). VideoLCM: Video Latent Consistency Model. arXiv.
- Masood, A. (2025).(https://medium.com/@adnanmasood/the-state-of-embedding-technologies-for-large-language-models-trends-taxonomies-benchmarks-and-95e5ec303f67 ). Medium.
- Masood, A. (n.d.).(https://medium.com/@adnanmasood/small-language-models-the-rise-of-compact-ai-and-microsofts-phi-models-cdc7cf20ea2d ). Medium.
- Meta AI. (n.d.). Llama 3.1 & SAM Release Notes.
- Meta AI. (2024).(https://ai.meta.com/sam2/ ).
- Microsoft. (n.d.). Phi-3 Technical Report.
- Microsoft Azure. (n.d.).(https://learn.microsoft.com/en-us/azure/ai-foundry/openai/how-to/gpt-with-vision ).
- Mistral AI. (n.d.). Mixtral of Experts.
- OpenAI. (n.d.). Function calling. OpenAI Platform.
- OpenAI. (2024).(https://openai.com/index/hello-gpt-4o/ ).
- Oracle. (n.d.).(https://docs.oracle.com/en-us/iaas/Content/generative-ai/meta-llama-3-1-405b.htm ). Oracle Cloud Infrastructure Documentation.
- Pinecone. (n.d.).(https://www.pinecone.io/learn/series/rag/embedding-models-rundown/ ).
- Raina, A. S. (2025).(https://www.ajeetraina.com/why-slms-will-replace-llms-in-agent-architectures/ ).
- Rangana, P. (2025).(https://medium.com/mr-plan-publication/not-everything-is-an-llm-8-ai-model-types-you-need-to-know-in-2025-6fb026bcdc82 ). Medium.
- Red Hat. (2025).(https://www.redhat.com/en/topics/ai/llm-vs-slm ).
- Salesforce. (2024). Large Action Models.
- Saurov, E. (n.d.).(https://evgeniisaurov.medium.com/demystifying-openai-function-calling-vs-anthropics-model-context-protocol-mcp-b5e4c7b59ac2 ). Medium.
- Schick, T., et al. (2023).(https://arxiv.org/abs/2302.04761 ). arXiv.
- Shazeer, N. (2022).(https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models/ ). Google Research.
- Sinha, A. (n.d.).(https://medium.com/@akankshasinha247/react-toolformer-autogpt-family-autonomous-agent-frameworks-2c4f780654b8 ). Medium.
- Srivastava, S. (n.d.).(https://medium.com/@srivastavasushant96/mixture-of-experts-moe-the-buzz-behind-deepseek-mistral-and-qwen3-dc6308b23fa1 ). Medium.
- Ultralytics. (2024).(https://www.ultralytics.com/blog/applications-of-meta-ai-segment-anything-model-2-sam-2 ).
- Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., & Wei, F. (2024).(https://arxiv.org/pdf/2212.03533). arXiv.
- Wikipedia. (n.d.). Llama (language model).
- Wikipedia. (n.d.).(https://en.wikipedia.org/wiki/Small_language_model ).
- Yang, H., et al. (2025).(https://arxiv.org/pdf/2506.05176). arXiv.