요약
이 글은 Python을 이용해 HWP 파일의 본문을 파싱하는 과정을 설명합니다. Section 스트림을 zlib으로 해제해 문단 단위 레코드를 읽고, 텍스트·제어 문자·글자 모양(CharShape)·문단 모양(ParaShape)을 파싱하는 절차를 코드와 함께 다룹니다. 또한 샘플 파일을 분석해 글꼴·색상·정렬 같은 서식이 실제 렌더링과 일치함을 확인했습니다. 이번 글은 본문 파싱까지를 정리하며, 다음 글에서는 표와 그림 등 복잡한 컨트롤 객체 파싱 방법을 이어서 다룰 예정입니다.
서론
지난 글에서는 HWP 문서 파일 구조를 분석하고 Python을 이용해 DocInfo 영역에서 폰트 및 이미지 정보를 읽어오는 방법을 다뤘습니다. 이번 시간에는 그 연장선상에서 HWP 파일의 Section 영역을 파싱하여 본문 데이터를 추출하는 방법에 대해 알아보겠습니다.
HWP 파일에서 본문 정보 읽어오기
HWP 본문 정보의 구조
HWP 파일에서 본문 내용은 BodyText 스토리지의 Section 스트림에 저장됩니다. 아래 표에서 볼 수 있듯이, 본문 정보는 DocInfo와 마찬가지로 여러 레코드의 집합으로 구성되며, 파일 크기를 줄이기 위해 압축되어 있거나 보안을 위해 암호화될 수 있습니다.
[표 1] 전체 구조 (공식 문서 [표 2] 참조)
| 설명 | 구별 이름 | 길이(바이트) | 레코드 구조 | 압축/암호화 |
|---|---|---|---|---|
| 파일 인식 정보 | 고정 | |||
| 문서 정보 | 고정 | V | V | |
| 본문 | 가변 | V | V | |
| … |
본문 구성의 핵심: 문단과 제어문자
본문을 파싱하기 전에 공식 문서 3.2.3절을 통해 HWP 포맷에서 본문이 어떻게 구성되어 있는지 알아보겠습니다.
[공식 문서 3.2.3절 본문 요약]
문서의 본문에는 문단, 표, 그리기 개체 등의 내용이 저장됩니다.
BodyText스토리지는 여러 개의 구역 (Section0,Section1…) 스트림으로 나뉘며, 각Section스트림은 문단 정보들의 리스트 형태로 구성됩니다.이때 구역이나 다단 설처럼 문서의 구조를 정의하는 정보는 일반 텍스트가 아닌 특별한 레코드로 각 구역의 첫 문단에는 구역 정의 레코드가, 각 단 설정의 첫 문단에는 단 정의 레코드가 포함됩니다.
이 설명에서 핵심은 Section 스트림이 ‘문단’의 연속이며, 문서 구조를 정의하는 ‘구역 정보’나 ‘단 정보’ 같은 특별한 데이터가 문단 내에 포함된다는 점입니다. 그렇다면 이 ‘구역 정보’와 ‘단 정보’는 어떻게 표현될까요?
[공식 문서 3.2.3절 본문 요약]
HWP에서는 표, 그림 등 일반 문자로 표현할 수 없는 요소를 표현하기 위해 특정 문자 코드(0-31)를 ‘제어 문자(컨트롤)’로 사용합니다. 이 제어 문자들은 세 가지 형식으로 나뉩니다.
- 문자 컨트롤 [char]: 하나의 문자로 취급되는 컨트롤 (크기 = 1)
- 인라인 컨트롤 [inline]: 별도의 오브젝트 포인터를 가리키지 않는 단순 인라인 컨트롤 (크기 = 8)
- 확장 컨트롤 [extended]: 별도의 오브젝트가 데이터를 표현하는 컨트롤 (크기 = 8)
[표 2] 제어문자 (공식 문서 [표 6] 참조)
| 코드 | 설명 | 컨트롤 형식 |
|---|---|---|
| 0 | unusable | char |
| 1 | 예약 | extended |
| 2 | 구역 정의/단 정의 | extended |
| 3 | 필드 시작 (누름틀, 하이퍼링크, 블록 책갈피, 표 계산식, 문서 요약, 사용자 정보, 현재 날짜/시간, 문서 날짜/시간, 파일 경로, 상호 참조, 메일머지, 메모, 교정부호, 개인정보) | extended |
| … | ||
[표 2] 제어문자에 따르면 ‘구역 정의/단 정의’는 코드 값이 2로 표현되는 제어 문자이며, 이 제어 문자는 그 자체로 특정 데이터 영역을 가지므로, 문서를 읽을 때 제어 문자의 종류에 따라 적절한 처리를 수행해야 합니다. 특히 확장 컨트롤은 별도의 오브젝트가 데이터를 표현하므로 추가적인 데이터 처리가 필요합니다.
본문 데이터 구조 파악하기
이제 실제 Section 스트림의 데이터를 살펴보며 본문 구조를 분석해보겠습니다.

Section 스트림은 여러 레코드로 구성된 문단들의 연속입니다. 각 문단은 아래와 같은 레코드들로 이루어져 있습니다.
[표 3] 본문 (공식 문서 [표 5] 참조)
| Tag ID | 의미 |
|---|---|
| HWPTAG_PARA_HEADER | 문단 헤더 (공식 문서 [표 58] 참조) |
| HWPTAG_PARA_TEXT | 문단의 텍스트 (공식 문서 [표 60] 참조) |
| HWPTAG_PARA_CHAR_SHAPE | 문단의 글자 모양 (공식 문서 [표 61] 참조) |
| HWPTAG_PARA_LINE_SEG | 문단의 레이아웃 (공식 문서 [표 62] 참조) |
| HWPTAG_PARA_RANGE_TAG | 문단의 영역 태그 (공식 문서 [표 63] 참조) |
| HWPTAG_CTRL_HEADER | 컨트롤 헤더 (공식 문서 [표 64] 참조) |
| … | |
이 중 HWPTAG_PARA_TEXT 레코드에는 실제 문단의 텍스트가 담겨있습니다. 이 영역을 확인해보면 레코드 헤더와 함께 0x02로 시작하는 데이터 블럭, 그리고 실제 본문 텍스트(abcd)가 보입니다.

| 코드 | 설명 | 컨트롤 형식 |
|---|---|---|
| 2 | 구역 정의/단 정의 | extended |
여기서 0x02로 시작하는 블록이 앞서 언급된 제어 문자 영역입니다. [표 2] 제어문자에 따라 이는 코드 2인 구역 정의/단 정의에 해당하는 확장 컨트롤임을 알 수 있습니다.
| 의미 | 컨트롤 ID |
|---|---|
| 구역 정의 | MAKE_4CHID(‘s’, ‘e’, ‘c’, ‘d’) |
| 단 정의 | MAKE_4CHID(‘c’, ‘o’, ‘l’, ‘d’) |
또한 제어 문자 코드 0x02외에 “d c e s“와 “d l o c“와 같은 문자열이 보이는데, 이는 [공식 문서 4.3.10절의 개체 이외의 컨트롤 항목]에 정의된 컨트롤 이름입니다. 이를 통해 해당 제어문자가 ‘구역 정의’와 ‘단 정의’ 레코드임을 파악할 수 있으며, ‘구역 정의’와 ‘단 정의’ 뒤에 텍스트가 배열되어 있음을 알 수 있습니다.
하지만, ‘구역 정의’와 ‘단 정의’ 제어문자는 확인했지만 실제 데이터는 HWPTAG_PARA_TEXT 레코드 안에 보이지 않습니다. 이 데이터들은 어디에 있을까요?
컨트롤 데이터의 위치
이 데이터들은 바로 HWPTAG_PARA_TEXT 레코드 다음에 위치합니다.
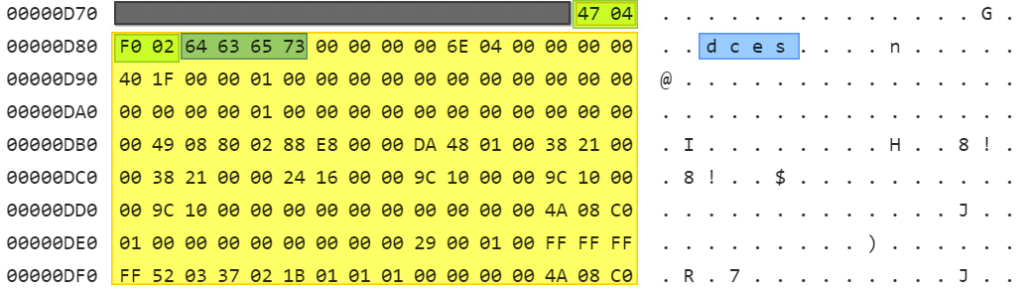
HWPTAG_PARA_TEXT 레코드 다음 영역에 0x47로 시작하는 HWPTAG_CTRL_HEADER 레코드를 확인할 수 있습니다. 이 HWPTAG_CTRL_HEADER 영역을 읽어보면 다음과 같습니다.
[표 4] 컨트롤 헤더 (공식 문서 [표 64] 참조)
Tag ID : HWPTAG_CTRL_HEADER
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 컨트롤 ID |
| 컨트롤 ID 이하 속성들은 CtrlID에 따라 다르다. • 각 컨트롤 및 개체 참고 | ||
| 전체 길이 | 4 |
이 레코드 영역이 이전 HWPTAG_PARA_TEXT 영역에서 확인했던 ‘구역 정의 제어문자의 실제 데이터 영역임을 알 수 있습니다.
본문 데이터 파싱 과정 도식화
이로써 HWP 포맷에서 본문 데이터가 어떻게 구성되어 있는지 파악할 수 있었습니다. 이 과정을 간단히 도식화 하면 다음과 같습니다.
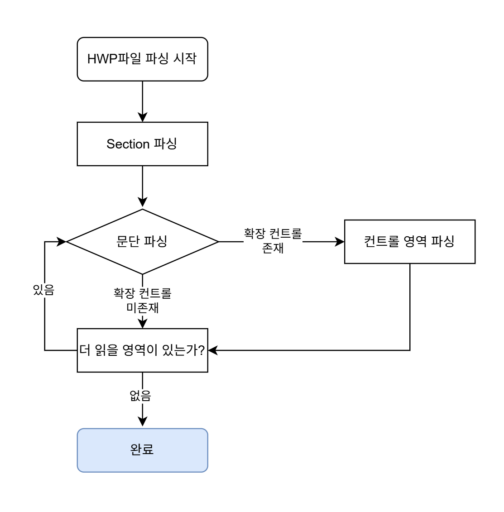
이제 이 원리를 바탕으로 실제 Python 코드를 작성하여 본문 텍스트를 추출하는 방법을 구현해보겠습니다.
Python으로 HWP 파일에서 본문 정보 읽어오기
HWP 파일에서 구역 (Section) 스트림 읽기
HWP 파일의 본문 데이터는 BodyText 스토리지의 Section 스트림에 저장되어 있습니다. 이 데이터는 압축되어 있으므로 zlib을 이용하여 압축을 해제해야 합니다.
class HWPReader:
def __init__(self, hwp_file_path: str):
self.ole = olefile.OleFileIO(hwp_file_path)
self.doc = Document()
def _read_doc_info_stream(self) -> BitStream:
doc_info_stream = self.ole.openstream('DocInfo')
doc_info_data = doc_info_stream.read()
return BitStream(zlib.decompress(doc_info_data, -15))
def _read_section_stream(self, section_name: str) -> BitStream:
section_stream = self.ole.openstream(section_name)
section_data = section_stream.read()
return BitStream(zlib.decompress(section_data, -15))이제 DocInfo에 정의된 구역(Section)의 개수만큼 반복하여 각 Section 스트림을 읽고 파싱합니다.
@dataclass
class Para:
...
@dataclass
class Section:
paraList: list[Para] = field(default_factory=list)
def _read_sections(self) -> bool:
for i in range(self.doc.documentInfo.sectionCount):
section_bits = self._read_section_stream(f"BodyText/Section{i}")
section = Section()
section.paraList = self._read_para_list(section_bits)
self.doc.sectionList.append(section)
return TrueHWP 파일에서 문단 읽기
HWP의 본문은 문단의 연속으로 구성됩니다. 각 문단은 하나의 레코드가 아니라 여러 하위 레코드들로 구성되어 있습니다. 문단을 구성하는 핵심 레코드들은 다음과 같습니다.
[표 5] 본문의 데이터 레코드 (공식 문서 [표 57] 참조)
| Tag ID | Value | 설명 |
|---|---|---|
| HWPTAG_PARA_HEADER | 0x42 | 문단 헤더 ([표 6] 문단 헤더 (공식 문서 [표 58] 참조)) |
| HWPTAG_PARA_TEXT | 0x43 | 문단의 텍스트 ([표 7] 문단 텍스트 (공식 문서 [표 60] 참조)) |
| HWPTAG_PARA_CHAR_SHAPE | 0x44 | 문단의 글자 모양 ([표 8] 문단의 글자 모양 (공식 문서 [표 61] 참조)) |
| HWPTAG_PARA_LINE_SEG | 0x45 | 문단의 레이아웃 ([표 9] 문단의 레이아웃 (공식 문서 [표 62] 참조)) |
| HWPTAG_PARA_RANGE_TAG | 0x46 | 문단의 영역 태그 ([표 10] 문단의 영역 태그 (공식 문서 [표 63] 참조)) |
[표 6] 문단 헤더 (공식 문서 [표 58] 참조)
Tag ID : HWPTAG_PARA_HEADER
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 글자수 |
| UINT32 | 4 | control mask (UINT32)(1 << ctrlch) 조합 ctrlch는 HwpCtrlAPI.hwp 2.1 CtrlCh 참고 |
| UINT16 | 2 | 문단 모양 아이디 참조값 |
| UINT8 | 1 | 문단 스타일 아이디 참조값 |
| UINT8 | 1 | 단 나누기 종류(공식 문서 [표 59] 참조) |
| UINT16 | 2 | 글자 모양 정보 수 |
| UINT16 | 2 | range tag 정보 수 |
| UINT16 | 2 | 각 줄에 대한 align에 대한 정보 수 |
| UINT32 | 4 | 문단 Instance ID (unique ID) |
| UINT16 | 2 | 변경추적 병합 문단여부. (5.0.3.2 버전 이상) |
| 전체 길이 | 24 |
[표 7] 문단 텍스트 (공식 문서 [표 60] 참조)
Tag ID : HWPTAG_PARA_TEXT
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| WCHAR array[sizeof(nchars)] | 2 x nchars | 문자 수 만큼의 텍스트 |
| 전체 길이 | 가변 | (2 x nchars) 바이트 |
[표 8] 문단의 글자 모양 (공식 문서 [표 61] 참조)
Tag ID : HWPTAG_PARA_CHAR_SHAPE
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 글자 모양이 바뀌는 시작 위치 |
| UINT32 | 4 | 글자 모양 ID |
| 전체 길이 | 가변 | 8 x 글자 모양 정보 수 |
[표 9] 문단의 레이아웃 (공식 문서 [표 62] 참조)
Tag ID : HWPTAG_PARA_LINE_SEG
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 텍스트 시작 위치 |
| UINT32 | 4 | 줄의 세로 위치 |
| UINT32 | 4 | 줄의 높이 |
| UINT32 | 4 | 텍스트 부분의 높이 |
| UINT32 | 4 | 줄의 세로 위치에서 베이스라인까지 거리 |
| UINT32 | 4 | 줄간격 |
| UINT32 | 4 | 컬럼에서의 시작 위치 |
| UINT32 | 4 | 세그먼트의 폭 |
| UINT32 | 4 | 태그 • bit 0 : 페이지의 첫 줄인지 여부 • bit 1 : 컬럼의 첫 줄인지 여부 • bit 16 : 텍스트가 배열되지 않은 빈 세그먼트인지 여부 • bit 17 : 줄의 첫 세그먼트인지 여부 • bit 18 : 줄의 마지막 세그먼트인지 여부 • bit 19 : 줄의 마지막에 auto-hyphenation이 수행되었는지 여부 • bit 20 : indentation 적용 • bit 21 : 문단 머리 모양 적용 • bit 31 : 구현상의 편의를 위한 property |
| 전체 길이 | 36 |
[표 10] 문단의 영역 태그 (공식 문서 [표 63] 참조)
Tag ID : HWPTAG_PARA_RANGE_TAG
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 영역 시작 |
| UINT32 | 4 | 영역 끝 |
| UINT32 | 4 | 태그(종류 + 데이터) : 상위 8비트가 종류를 하위 24비트가 종류별로 다른 설명을 부여할 수 있는 임의의 데이터를 나타낸다 |
| 전체 길이 | 가변 | 12 x range tag 정보 수 |
이 구조에 맞춰 데이터를 담을 dataclass를 정의하고, 이를 채워나가는 파싱 함수를 작성해 보겠습니다.
@dataclass
class ParaCharShape:
pos: int = 0 # 글자 모양이 바뀌는 시작위치
id: int = 0 # 글자 모양 ID
@dataclass
class ParaLineSeg:
textPos: int = 0 # 텍스트 시작 위치
vertPos: int = 0 # 줄의 세로 위치
vertHeight: int = 0 # 줄의 높이
textHeight: int = 0 # 텍스트 부분의 높이
baseLine: int = 0 # 줄의 세로 위치에서 베이스라인까지 거리
spacing: int = 0 # 줄 간격
horzPos: int = 0 # 컬럼에서의 시작 위치
horzSize: int = 0 # 세그먼트의 폭
flags: int = 0 # 태그 속성
@dataclass
class ParaRangeTag:
startPos: int = 0 # 영역 시작
endPos: int = 0 # 영역 끝
tag: int = 0 # 태그(종류 + 데이터)
@dataclass
class Para:
charCount: int = 0 # 글자수
controlMask: int = 0 # 컨트롤 마스크
paraShapeID: int = 0 # 문단 모양 아이디 참조값
paraStypeID: int = 0 # 문단 스타일 아이디 참조값
breakType: int = 0 # 단 나누기 종류
paraCharShapeCount: int = 0 # 글자 모양 정보 수
paraRangeTagCount: int = 0 # range tag 정보 수
paraLineSegCount: int = 0 # 각 줄에 대한 align에 대한 정보 수
paraInstanceID: int = 0 # 문단 Instance ID
isTrackChangeMerge: int = 0 # 변경추적 병합 문단여부
text: str = "" # 문단의 텍스트
paraCharShapeList: list[ParaCharShape] = field(default_factory=list) # 문단의 글자모양
paraLineSegList: list[ParaLineSeg] = field(default_factory=list) # 문단의 레이아웃
paraRangeTagList: list[ParaRangeTag] = field(default_factory=list) # 문단의 영역 태그
ctrlList: list[Ctrl] = field(default_factory=list) # 문단 내 컨트롤
isLast: bool = False # 마지막 para여부class HWPReader
...
def _read_para_charshape(self, bits: BitStream) -> "ParaCharShape":
para_char_shape = ParaCharShape()
para_char_shape.pos = bytes_to_int(Record.read(bits, 32)) # 시작 위치
para_char_shape.id = bytes_to_int(Record.read(bits, 32)) # CharShape ID (DocInfo에서 정의된)
return para_char_shape
def _read_para_lineseg(self, bits: BitStream) -> "ParaLineSeg":
para_line_seg = ParaLineSeg()
para_line_seg.textPos = bytes_to_int(Record.read(bits, 32))
para_line_seg.vertPos = bytes_to_int(Record.read(bits, 32))
para_line_seg.vertHeight = bytes_to_int(Record.read(bits, 32))
para_line_seg.textHeight = bytes_to_int(Record.read(bits, 32))
para_line_seg.baseLine = bytes_to_int(Record.read(bits, 32))
para_line_seg.spacing = bytes_to_int(Record.read(bits, 32))
para_line_seg.horzPos = bytes_to_int(Record.read(bits, 32))
para_line_seg.horzSize = bytes_to_int(Record.read(bits, 32))
para_line_seg.flags = bytes_to_int(Record.read(bits, 32))
return para_line_seg
def _read_para_rangetag(self, bits: BitStream) -> "ParaRangeTag":
para_range_tag = ParaRangeTag()
para_range_tag.startPos = bytes_to_int(Record.read(bits, 32))
para_range_tag.endPos = bytes_to_int(Record.read(bits, 32))
para_range_tag.tag = bytes_to_int(Record.read(bits, 32))
return para_range_tag
def _read_para(self, bits: BitStream) -> "Para" or None:
para = Para()
# 1. 문단 헤더 (HWPTAG_PARA_HEADER) 파싱
# 이 레코드는 문단의 전반적인 정보를 담고 있습니다.
if not Record.read_record(HWPTAG_PARA_HEADER, bits):
return None
para.charCount = bytes_to_int(Record.read(bits, 32)) # 문단 내 글자(또는 컨트롤) 개수
para.controlMask = bytes_to_int(Record.read(bits, 32)) # 컨트롤 존재 여부 등의 플래그
para.paraShapeID = bytes_to_int(Record.read(bits, 16)) # 문단 모양(ParaShape) ID
para.paraStypeID = bytes_to_int(Record.read(bits, 8)) # 문단 스타일 ID
para.breakType = bytes_to_int(Record.read(bits, 8)) # 줄 바꿈 유형
para.paraCharShapeCount = bytes_to_int(Record.read(bits, 16)) # 글자 모양(CharShape) 정보 개수
para.paraRangeTagCount = bytes_to_int(Record.read(bits, 16)) # 범위 태그(RangeTag) 정보 개수
para.paraLineSegCount = bytes_to_int(Record.read(bits, 16)) # 라인 세그먼트(LineSeg) 정보 개수
para.paraInstanceID = bytes_to_int(Record.read(bits, 32)) # 문단 인스턴스 ID
para.isTrackChangeMerge = bytes_to_int(Record.read(bits, 16)) # 변경 내용 추적 병합 여부
Record.end_record(bits)
# charCount의 최상위 비트(0x80000000)는 마지막 문단임을 나타냄
if para.charCount & 0x80000000:
para.charCount &= 0x7fffffff
para.isLast = True
# 2. 문단 텍스트 (HWPTAG_PARA_TEXT) 파싱
if para.charCount > 1:
if not Record.read_record(HWPTAG_PARA_TEXT, bits):
return None
para.text = bytes_to_str(Record.read(bits, 16 * para.charCount))
Record.end_record(bits)
# 3. 글자 모양 (HWPTAG_PARA_CHAR_SHAPE) 파싱
if para.paraCharShapeCount > 0:
if not Record.read_record(HWPTAG_PARA_CHAR_SHAPE, bits): return False
for _ in range(para.paraCharShapeCount):
para.paraCharShapeList.append(self._read_para_charshape(bits))
Record.end_record(bits)
# 4. 문단의 레이아웃 정보 (HWPTAG_PARA_LINE_SEG) 파싱
if para.paraLineSegCount > 0:
if not Record.read_record(HWPTAG_PARA_LINE_SEG, bits): return False
for _ in range(para.paraLineSegCount):
para.paraLineSegList.append(self._read_para_lineseg(bits))
Record.end_record(bits)
# 5. 문단의 특정 범위에 대한 태그 정보 HWPTAG_PARA_RANGE_TAG 파싱
if para.paraRangeTagCount > 0:
if not Record.read_record(HWPTAG_PARA_RANGE_TAG, bits): return False
for _ in range(para.paraRangeTagCount):
para.paraRangeTagList.append(self._read_para_rangetag(bits))
Record.end_record(bits)
# 6. 제어 문자 처리
# 텍스트 내에 포함된 제어 문자(컨트롤)를 처리
self._create_ctrl(para, bits)
return para
문단에서 사용되는 글자 모양, 문단 모양 파싱
문단은 단순히 텍스트만 가지고 있지 않습니다. ‘어떤 글꼴을, 어떤 크기로, 어떤 정렬로 보여줄지’에 대한 정보, 즉 ‘글자모양’과 ‘문단모양’, 문단의 레이아웃 정보 등이 필요합니다. 이 정보들은 DocInfo에 미리 정의되어 있고, 각 문단은 ID를 통해 이 속성 정보를 참조합니다.
지난 시간에 DocInfo 파싱 코드를 작성 했으니, 이제 글자 모양과 문단 모양을 읽는 부분을 추가해보겠습니다.
1) 글자모양 파싱
[표 11] 글자모양 (공식 문서 [표 33] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| WORD array[7] | 14 | 언어별 글꼴 ID(FaceID) 참조 값(공식 문서 [표 34] 참조) |
| UINT8 array[7] | 7 | 언어별 장평, 50%~200%(공식 문서 [표 34] 참조) |
| INT8 array[7] | 7 | 언어별 자간, -50%~50%(공식 문서 [표 34] 참조) |
| UINT8 array[7] | 7 | 언어별 상대 크기, 10%~250%(공식 문서 [표 34] 참조) |
| INT8 array[7] | 7 | 언어별 글자 위치, -100%~100%(공식 문서 [표 34] 참조) |
| INT32 | 4 | 기준 크기, 0pt~4096pt |
| UINT32 | 4 | 속성(표 30 참조) |
| INT8 | 1 | 그림자 간격, -100%~100% |
| INT8 | 1 | 그림자 간격, -100%~100% |
| COLORREF | 4 | 글자 색 |
| COLORREF | 4 | 밑줄 색 |
| COLORREF | 4 | 음영 색 |
| COLORREF | 4 | 그림자 색 |
| UINT16 | 2 | 글자 테두리/배경 ID(CharShapeBorderFill ID) 참조 값 (5.0.2.1 이상) |
| COLORREF | 4 | 취소선 색 (5.0.3.0 이상) |
| 전체 길이 | 72 |
[표 12] 글꼴에 대한 언어 (공식 문서 [표 34] 참조)
| 값 | 설명 |
|---|---|
| 0 | 한글 |
| 1 | 영어 |
| 2 | 한자 |
| 3 | 일어 |
| 4 | 기타 |
| 5 | 기호 |
| 6 | 사용자 |
[표 13] 글자 모양 속성 (공식 문서 [표 35] 참조)
| 범위 | 구분 | 값 | 설명 |
|---|---|---|---|
| bit 0 | 기울임 여부 | ||
| bit 1 | 진하게 여부 | ||
| bit 2 – 3 | 밑줄 종류 | 0 | 없음 |
| 1 | 글자 아래 | ||
| 3 | 글자 위 | ||
| … | |||
글자 모양(CharShape)은 글꼴, 크기, 색상, 속성(진하게 기울임 등)을 정의합니다.
@dataclass
class CharShape:
faceID: tuple = field(default_factory=lambda: (0,)*7) # 언어별 글꼴
ratio: tuple = field(default_factory=lambda: (0,)*7) # 언어별 장평 50% ~ 200%
spacing: tuple = field(default_factory=lambda: (0,)*7) # 언어별 자간 -50% ~ 50%
size: tuple = field(default_factory=lambda: (0,)*7) # 언어별 상대 크기 10% ~ 250%
offset: tuple = field(default_factory=lambda: (0,)*7) # 언어별 글자 위치 -100% ~ 100%
height: int = 0 # 기준 크기 0pt ~ 4096pt
attributes: int = 0 # 속성
shadowOffsetX: int = 0 # 그림자 간격 -100% ~ 100%
shadowOffsetY: int = 0 # 그림자 간격 -100% ~ 100%
textColor: Dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 }) # 글자색
underlineColor: Dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 }) # 밑줄 색
shadeColor: Dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 }) # 음영 색
shadowColor: Dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 }) # 그림자 색
borderFillID: int = 0 # 글자 테두리/배경 ID
strikeoutColor: Dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 }) # 취소선 색
class HWPReader
...
def _read_charshape(self, bits: BitStream) -> "CharShape" or None:
char_shape = CharShape()
if not Record.read_record(HWPTAG_CHAR_SHAPE, bits):
return None
char_shape.faceID = tuple(bytes_to_int(Record.read(bits, 16)) for _ in range(7))
char_shape.ratio = tuple(bytes_to_int(Record.read(bits, 8)) for _ in range(7))
char_shape.spacing = tuple(bytes_to_int(Record.read(bits, 8)) for _ in range(7))
char_shape.size = tuple(bytes_to_int(Record.read(bits, 8)) for _ in range(7))
char_shape.offset = tuple(bytes_to_int(Record.read(bits, 8)) for _ in range(7))
char_shape.height = bytes_to_int(Record.read(bits, 32))
char_shape.attributes = bytes_to_int(Record.read(bits, 32))
char_shape.shadowOffsetX = bytes_to_int(Record.read(bits, 8))
char_shape.shadowOffsetY = bytes_to_int(Record.read(bits, 8))
char_shape.textColor = self._colorref_to_dict(bytes_to_int(Record.read(bits, 32)))
char_shape.underlineColor = self._colorref_to_dict(bytes_to_int(Record.read(bits, 32)))
char_shape.shadeColor = self._colorref_to_dict(bytes_to_int(Record.read(bits, 32)))
char_shape.shadowColor = self._colorref_to_dict(bytes_to_int(Record.read(bits, 32)))
char_shape.borderFillID = bytes_to_int(Record.read(bits, 16))
char_shape.strikeoutColor = self._colorref_to_dict(bytes_to_int(Record.read(bits, 32)))
Record.end_record(bits)
return char_shape
def _read_doc_info_charshape(self, bits: BitStream) -> bool:
for _ in range(self.doc.documentInfo.shape_counts["charshapeCount"]):
char_shape = self._read_charshape(bits)
if not char_shape:
return False
self.doc.shapeManager.charshapeList.append(char_shape)
return True2) 문단 모양 파싱
[표 14] 문단 모양 (공식 문서 [표 43] 참조)
| 자료형 | 길이(바이트) | 설명 |
|---|---|---|
| UINT32 | 4 | 속성 1(공식 문서 [표 44] 참조) |
| INT32 | 4 | 왼쪽 여백 |
| INT32 | 4 | 오른쪽 여백 |
| INT32 | 4 | 들여 쓰기/내어 쓰기 |
| INT32 | 4 | 문단 간격 위 |
| INT32 | 4 | 문단 간격 아래 |
| INT32 | 2 | 줄 간격. 한/글 2007 이하 버전(5.0.2.5 버전 미만)에서 사용. |
| UINT16 | 2 | 탭 정의 아이디(TabDef ID) 참조 값 |
| UINT16 | 2 | 번호 문단 ID(Numbering ID) 또는 글머리표 문단 모양 ID(Bullet ID) 참조 값 |
| UINT16 | 2 | 테두리/배경 모양 ID(BorderFill ID) 참조 값 |
| INT16 | 2 | 문단 테두리 왼쪽 간격 |
| INT16 | 2 | 문단 테두리 오른쪽 간격 |
| INT16 | 2 | 문단 테두리 위쪽 간격 |
| INT16 | 2 | 문단 테두리 아래쪽 간격 |
| UINT32 | 4 | 속성 2(공식 문서 [표 40] 참조) (5.0.1.7 버전 이상) |
| UINT32 | 4 | 속성 3(공식 문서 [표 41] 참조) (5.0.2.5 버전 이상) |
| UINT32 | 4 | 줄 간격(5.0.2.5 버전 이상) |
| 전체 길이 | 54 |
문단 모양(ParaShape)은 정렬 방식, 여백, 줄 간격 등 문단 전체의 레이아웃을 정의합니다.
@dataclass
class ParaShape:
attributes: int = 0 # 속성 1(표 44참조)
leftMargin: int = 0 # 왼쪽 여백
rightMargin: int = 0 # 오른쪽 여백
indentation: int = 0 # 들여 쓰기/내어 쓰기
beforeSpacing: int = 0 # 문단 간격 위
afterSpacing: int = 0 # 문단 간격 아래
lineSpacing: int = 0 # 줄 간격
tabID: int = 0 # 탭 정의 아이디
numberingID: int = 0 # 번호 문단 ID 또는 글머리표 문단모양 ID 참조 값
borderFillID: int = 0 # 테두리/배경 모양 ID 참조 값
leftBorderSpacing: int = 0 # 문단 테두리 간격[왼쪽]
rightBorderSpacing: int = 0 # 문단 테두리 간격[오른쪽]
topBorderSpacing: int = 0 # 문단 테두리 간격[위]
downBorderSpacing: int = 0 # 문단 테두리 간격[아래]
numberingAttributes: int = 0 # 문단 머리 정보 속성[표40]
numberingFormatAttrubutes: int = 0 # 문단 번호 형식[표41]
lineSpacing: int = 0 # 줄 간격
class HWPReader
...
def _read_parashape(self, bits: BitStream) -> "ParaShape" or None:
para_shape = ParaShape()
if not Record.read_record(HWPTAG_PARA_SHAPE, bits):
return None
para_shape.attributes = bytes_to_int(Record.read(bits, 32))
para_shape.leftMargin = bytes_to_int(Record.read(bits, 32))
para_shape.rightMargin = bytes_to_int(Record.read(bits, 32))
para_shape.indentation = bytes_to_int(Record.read(bits, 32))
para_shape.beforeSpacing = bytes_to_int(Record.read(bits, 32))
para_shape.afterSpacing = bytes_to_int(Record.read(bits, 32))
para_shape.lineSpacing = bytes_to_int(Record.read(bits, 32))
para_shape.tabID = bytes_to_int(Record.read(bits, 16))
para_shape.numberingID = bytes_to_int(Record.read(bits, 16))
para_shape.borderFillID = bytes_to_int(Record.read(bits, 16))
para_shape.leftBorderSpacing = bytes_to_int(Record.read(bits, 16))
para_shape.rightBorderSpacing = bytes_to_int(Record.read(bits, 16))
para_shape.topBorderSpacing = bytes_to_int(Record.read(bits, 16))
para_shape.downBorderSpacing = bytes_to_int(Record.read(bits, 16))
para_shape.numberingAttributes = bytes_to_int(Record.read(bits, 32))
para_shape.numberingFormatAttrubutes = bytes_to_int(Record.read(bits, 32))
para_shape.lineSpacing = bytes_to_int(Record.read(bits, 32))
Record.end_record(bits)
return para_shape
def _read_doc_info_para_shape(self, bits: BitStream) -> bool:
for _ in range(self.doc.documentInfo.shape_counts["parashapeCount"]):
para_shape = self._read_parashape(bits)
if not para_shape:
return False
self.doc.shapeManager.parashapeList.append(para_shape)
return True3) 제어문자 처리
HWP 문서의 텍스트 영역(HWPTAG_PARA_TEXT)에는 단순히 글자만 있는 것이 아닙니다. 표, 그림과 같은 복잡한 개체들은 ‘제어문자’ 형태로 텍스트 사이에 숨어있습니다.
특히 ‘확장 컨트롤’의 실제 데이터는 다른 곳에 저장되어 있습니다.
구현할 _create_ctrl함수는 이런 숨겨진 제어문자를 찾아내고 처리하는 역할을 합니다.
[표 15] 제어문자(공식 문서 [표 6] 참조)
| 코드 | 설명 | 컨트롤 형식 |
|---|---|---|
| 0 | unusable | char |
| 1 | 예약 | extended |
| 2 | 구역 정의/단 정의 | extended |
| 3 | 필드 시작 (누름틀, 하이퍼링크, 블록 책갈피, 표 계산식, 문서 요약, 사용자 정보, 현재 날짜/시간, 문서 날짜/시간, 파일 경로, 상호 참조, 메일머지, 메모, 교정부호, 개인정보) | extended |
| … | ||
# 컨트롤 캐릭터
HWP_CTRLCH_RESERVE = 1
HWP_CTRLCH_SECTION_OR_COLUMN = 2
...
# 문자 컨트롤
CTRLCH_CHARS = {
HWP_CTRLCH_LINE_BREAK,
...
}
# 인라인 컨트롤
INLINE_CHARS = {
HWP_CTRLCH_FIELD_END,
...
}
# 확장 컨트롤
EXTENSION_CHARS = {
HWP_CTRLCH_SECTION_OR_COLUMN,
...
}
class HWPReader
...
# 'secd' -> 구역 정의, 'cold' -> 단 정의 등 컨트롤 ID와 파서 함수를 매핑
ctrl_factory = {
'secd': _read_secdef_ctrl,
'cold': _read_coldef_ctrl,
}
def _create_ctrl(self, para: Para, bits: BitStream) -> bool:
text_bytes = para.text.encode('utf-16-le')
text_stream = BytesIO(text_bytes)
processed_text = ""
temp_char_buffer = []
while True:
# 1. 2바이트(한 문자)씩 읽기
char_bytes = text_stream.read(2)
if not char_bytes:
break
char_val = int.from_bytes(char_bytes, 'little')
# 2. 확장 컨트롤인지 확인
if is_extension_char(char_val):
payload_bytes = text_stream.read(14)
ctrl_id = payload_bytes[0:4].decode('ascii').strip()
# 컨트롤 ID는 역순으로 저장되어 있으므로 뒤집어줍니다. (예: 'dces' -> 'secd')
ctrl_id = ctrl_id[::-1]
# 팩토리에서 적절한 파서 함수를 찾아 실행
ctrl_type_parser = self.ctrl_factory.get(ctrl_id)
if ctrl_type_parser:
# 확장 컨트롤의 실제 데이터 영역을 파싱
ctrl_object = ctrl_type_parser(self, bits)
para.ctrlList.append(ctrl_object)
else:
print(f"미구현 확장 컨트롤 ID: {ctrl_id}")
# 인라인 컨트롤(Inline Control)
elif is_inline_char(char_val):
text_stream.read(12)
# 일반 문자 컨트롤(Char Control)
elif is_ctrl_char(char_val):
continue
# 3.
# 제어 문자가 아닌 일반 텍스트는 따로 저장
else:
processed_text += char_bytes.decode('utf-16-le', errors='replace')
# 순수 텍스트가 있다면 Text 객체로 만들어 컨트롤 리스트에 추가
if not para.ctrlList and processed_text:
para.ctrlList.append(Text(0, processed_text)) # Text(offset, content)
return True이 로직을 통해 텍스트를 순회하며 일반 문자와 제어문자를 분리하고, 확장 컨트롤을 만나면 ctrl_factory에 등록된 함수를 호출하여 해당 데이터 영역을 추가로 파싱합니다.
샘플 파일 분석
분석에 앞서 파서의 데이터 구조 이해하기
이제 우리가 만든 파서로 실제 HWP 파일을 분석해 볼 차례입니다. 하지만 데이터를 들여다보기 전에, 파서가 HWP 파일을 어떤 논리적 구조로 해석하고 저장하는지 먼저 확인해보겠습니다.
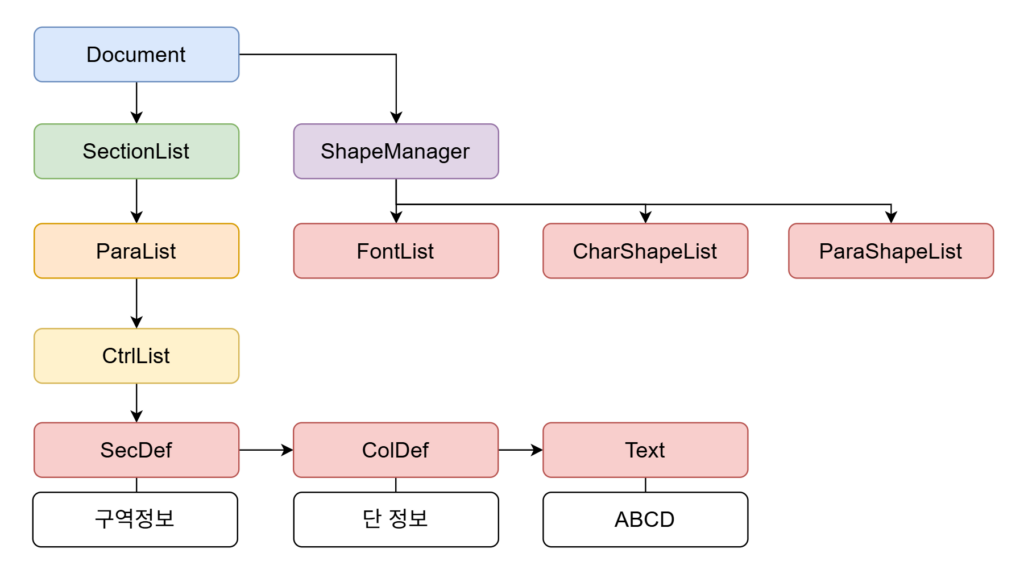
큰 틀에서 구현한 파서는 HWP 문서를 다음과 같은 계층 구조로 표현합니다.
Document(문서)
가장 상위에 있는 최상위 객체로 파싱된 HWP 파일의 모든 정보를 가지고 있습니다.SectionList(구역 리스트)Document바로 아래에 위치하며 문서의 구역(Section)들의 리스트입니다.ParaList(문단 리스트)
각Section은 여러 개의 문단으로 구성됩니다.ParaList는 한 구역 안에 포함된 모든 문단의 리스트를 가지고 있습니다.CtrlList(컨트롤 리스트)
문단의 실제 내용을 담고 있는 데이터 리스트입니다. 여기서 컨트롤은 눈에 보이는 텍스트뿐만 아니라 표, 그림 등 문단을 구성하는 모든 요소들을 포괄하는 개념입니다.ShapeManager(모양 정보 관리자)
문서 전체의 스타일 정보를 총괄하는 객체입니다.ShapeManager는 문서에 사용된 모든 글꼴, 글자 모양, 문단 모양 등을 리스트로 관리합니다. 각 문단이나 텍스트는 고유한 스타일을 직접 들고 있는 것이 아니라,ShapeManager에 등록된 스타일의 ID를 참조하는 방식으로 동작합니다.
샘플 HWP 포맷 파일 분석하기
이제 우리가 만든 파서로 간단한 샘플파일을 불러와서 데이터를 분석해보겠습니다. 아래와 같이 가운데 정렬된 “한글과컴퓨터”라는 텍스트가 담긴 파일입니다.
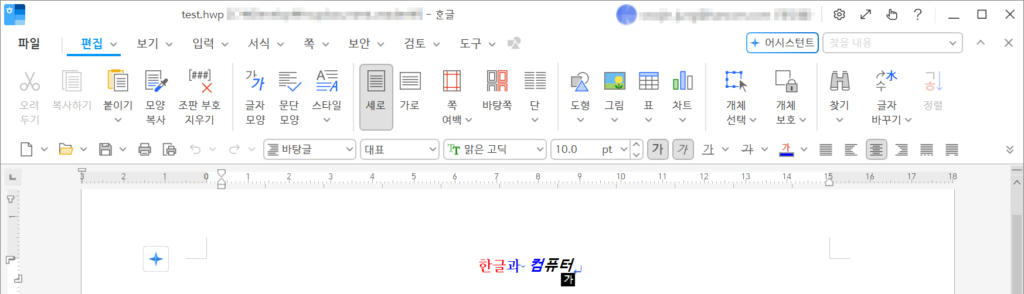
1) Reader로 읽어온 데이터
파싱 결과 다음과 같은 정보들을 얻을 수 있습니다.
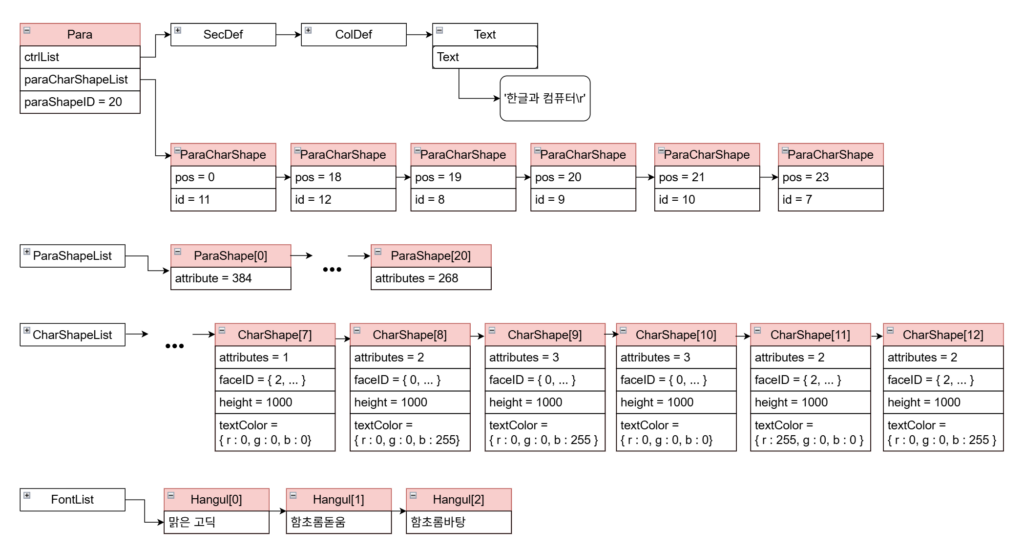
2) 본문 텍스트, 글자모양, 문단모양 분석하기
이제 위 데이터를 Para를 중심으로 분석해보겠습니다.
para.ctrlList: Text 객체에 ‘한글과 컴퓨터’라는 문자열이 저장됩니다.para.paraCharShapeList: 각 글자 위치에 적용된 글자모양 ID 리스트para.paraShapeID: 문단에 적용된 문단 모양 ID
3) 글자 모양 분석
paraCharShapeList에는 각 글자 위치(pos)에 적용된 CharShape의 ID가 들어있습니다. 여기서 한 가지 주의할 점이 있습니다. pos값은 순수한 글자 수 기준이 아니라, 문단 내 모든 제어문자를 포함한 전체 바이트 스트림에서의 상대 위치입니다. 예를 들어 텍스트 앞에 ‘구역 정의’와 ‘단 정의’ 확장 컨트롤이 있다면, 각 컨트롤이 차지하는 8바이트(총 16바이트)를 더한 위치 값이 pos에 기록됩니다.
[표 16] 글자모양 (공식 문서 [표 33] 참조)
| 데이터 | 설명 |
|---|---|
| 속성 (attriute) | ([표 17] 글자 모양 속성 (공식 문서 [표 35] 참조)) 참고 |
| 언어별 글꼴 (faceID) | ShapeManager의 FontList에서 ID 참조 |
| 기준 크기 (height) | 기준 크기, 0pt ~ 4096pt HWPUNIT으로 저장되므로 HWPUIT → pt로 변환 시 100으로 나누어줘야함. |
| 글자 색 (textColor) | RGB |
[표 17] 글자 모양 속성 (공식 문서 [표 35] 참조)
| 범위 | 구분 | 값 | 설명 |
|---|---|---|---|
| bit 0 | 기울임 여부 | ||
| bit 1 | 진하게 여부 | ||
| bit 2 – 3 | 밑줄 종류 | 0 | 없음 |
| 1 | 글자 아래 | ||
| 3 | 글자 위 | ||
| … | |||
이를 감안하여 각 위치의 글자 모양을 분석한 결과는 다음과 같습니다.
| POS | ID | 속성 | 글꼴 | 기준 크기 | 글자 색 |
|---|---|---|---|---|---|
| 0 | 11 | 2 (진하게) | 함초롬바탕 | 1000(10pt) | 빨강 R(255) G(0) B(0) |
| 2 | 12 | 2 (진하게) | 함초롬바탕 | 1000(10pt) | 파랑 R(0) G(0) B(255) |
| 3 | 8 | 2 (진하게) | 맑은 고딕 | 1000(10pt) | 파랑 R(0) G(0) B(255) |
| 4 | 9 | 3 (기울임, 진하게) | 맑은 고딕 | 1000(10pt) | 파랑 R(0) G(0) B(255) |
| 5 | 10 | 3 (기울임, 진하게) | 맑은 고딕 | 1000(10pt) | 검정 R(0) G(0) B(0) |
| 6 | 7 | 1 (기울임) | 함초롬바탕 | 1000(10pt) | 검정 R(0) G(0) B(0) |
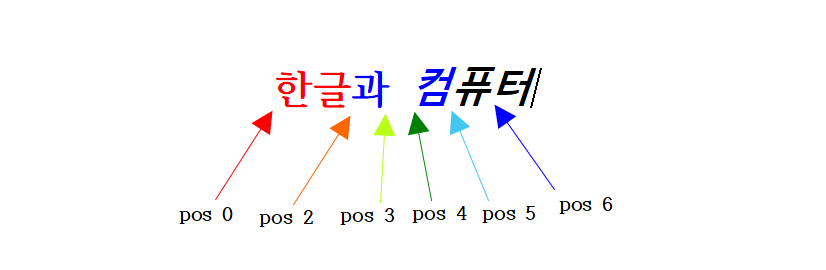
파일을 열어 확인해보면 샘플 파일의 서식과 일치하고 있음을 확인할 수 있습니다.
4) 문단 모양 분석
paraShapeID를 이용해 ShapeManager에서 해당 문단 모양 객체를 찾아 속성값을 분석해봅시다.
[표 18] 문단 모양 (공식 문서 [표 43] 참조)
| 데이터 | 설명 |
|---|---|
| 속성 (attriute) | [공식 문서 [표 44] 문단 모양 속성1] 참고 |
[표 19] 문단 모양 속성1 (공식 문서 [표 44] 참조)
| 범위 | 구분 | 값 | 설명 |
|---|---|---|---|
| bit 0 ~ 1 | 줄 간격 종류 한/글 2007 이하 버전에서 사용 | 0 | 글자에 따라 |
| 1 | 고정값 | ||
| 2 | 여백만 지정 | ||
| bit 2 ~ 4 | 정렬 방식 | 0 | 양쪽 정렬 |
| 1 | 왼쪽 정렬 | ||
| 2 | 오른쪽 정렬 | ||
| 3 | 가운데 정렬 | ||
| 4 | 배분 정렬 | ||
| 5 | 나눔 정렬 | ||
| bit 5 ~ 6 | 줄 나눔 기준 영어 단위 | 0 | 단어 |
| 1 | 하이픈 | ||
| 2 | 글자 | ||
| bit 7 | 줄 나눔 기준 한글 단위 | 0 | 어절 |
| 1 | 글자 | ||
| bit 8 | 편집 용지의 줄 격자 사용 여부 | ||
| … | |||
| ParaShapeID | 속성 (attribute) |
|---|---|
| 20 | 268 (0001 0000 1100)bit 2 ~ 4가 3이므로 가운데 정렬 적용됨bit 8이 켜져있으므로 편집 용지의 줄 격자 사용 여부 적용됨 |
실제 HWP 파일의 문단 정보와 일치하는 것을 확인할 수 있습니다.
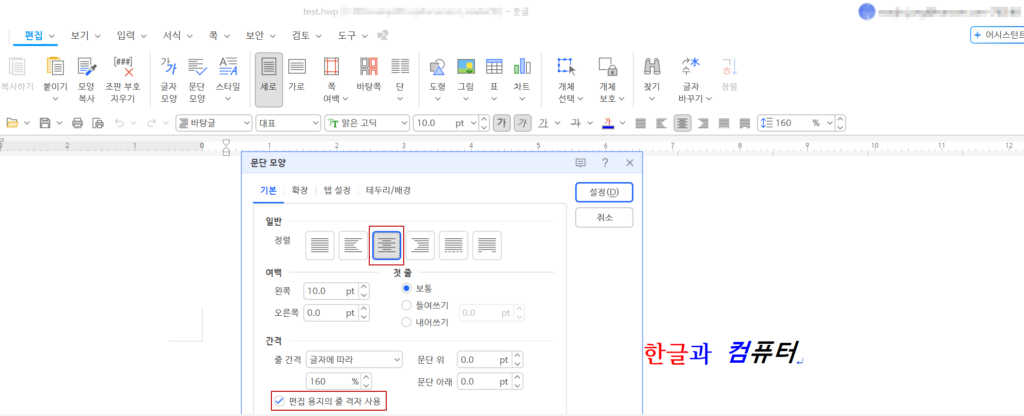
마치며
이번 시간에는 Python을 이용해 HWP 파일의 본문을 구성하는 문단, 텍스트 등을 파싱하는 과정을 다루었습니다.
다음 시간에는 이 코드 기반으로 표, 그림과 같은 더 복잡한 컨트롤 객체들을 파싱하는 방법을 확인해보겠습니다.