한컴테크를 통해 한컴의 기술을 공유합니다. 한컴의 프로그래밍, 프레임워크, 라이브러리 및 도구 등 다양한 기술을 만나보세요. 한컴 개발자들의 다양한 지식을 회사라는 울타리를 넘어 여러분과 공유합니다. 한컴이 제공하는 기술블로그에서 새로운 아이디어와 도전을 마주하고, 개발자가 꿈꾸는 미래를 실현하세요.
인공지능에서 자연어처리가 어떤 기술이고 어떻게 개발을 진행하고 있는지 잘 모르는 분들을 위해 이해하기 쉽고 재밌게 글을 적어봤습니다. 이번 포스팅에서는 자연어처리가 무엇인지 한번 알아보는 시간을 가져보도록 하겠습니다.
1. 인공지능에서 자연어처리는?
출처 : 과학기술정보통신부
우리는 몇 년 전부터 “4차 산업혁명이 도래했다”, “인공지능이 세계를 지배한다”, “인공지능이 우리의 삶의 질을 바꿀 것이다” 라는 문구를 뉴스, 신문기사, 서점에서의 서적 표지만 보더라도 쉽게 접할 수 있었습니다.
음성인식(STT, Speech-To-Text), 음성합성(TTS, Text-To-Speech) 분야에서는 인공지능 스피커가 보편화되면서 사람들에게 편리성을 제공해줬고, Siri나 빅스비로 스케줄 관리, 전화 걸기, 카페에서 좋은 노래가 나오면 어떤 노래인지 찾는 등의 기능을 사용하며 삶의 질이 향상되는 것을 피부로 느꼈을 것입니다.
영상인식으로는 카메라의 필터 보정이나 얼굴인식을 통해 다양한 테마들을 설정해 재밌는 사진을 찍어 친구들과 공유하기도 했고 차량의 전방 충돌 방지, 차로 이탈 방지 등을 통해 안전한 주행을 할 수 있게 되었습니다. 이렇게 해가 거듭될수록 인공지능은 우리의 삶에 천천히 녹아들고 있음은 자명해 보입니다.
일반 사람들에게 AI 인공지능에 대해 물어본다면 당연하게도 우리와 밀접해있는 음성인식, 영상인식이 먼저 나올 것이라 생각됩니다. 그러나 이 외에도 다른 여러 분야의 인공지능 기술이 다양한 부분에서 우리를 돕고 있는데 자연어처리, 챗봇, 추천 시스템, 번역, 자율 주행 등의 많은 기술들이 보이지 않게 우리에게 많은 도움을 주고 있다고 할 수 있습니다. 이번 포스팅에서는 사람들에게 익숙하지 않은 자연어처리기술에 대해 한번 이야기해 보도록 하겠습니다.
1950년에 앨런 튜링에 의해 개발된 Turing test가 있는데 이 테스트는 인간 평가자가 인간과 같은 반응을 일으키도록 설계된 기계 사이의 자연 언어 대화를 판단하는 테스트로 평가자가 기계와 인간을 확실하게 구분할 수 없는 경우, 그 기계는 Turing test에 합격하였다고 이야기합니다[1]. 이 실험은 “기계가 생각할 수 있는가?”라는 튜링의 철학적인 질문에서 시작된 이 실험처럼 자연어처리 개발의 궁극적인 목적은 컴퓨터가 인간이 의도한 질문을 이해하고 사람처럼 답을 제시하고 행동하는 것입니다.
자연어처리에서 자연어(natural language)는 사람이 사용하는 모든 언어를 말하며, 자연어처리(natural language processing)는 컴퓨터가 자연어의 의미를 분석하여 읽고 처리할 수 있도록 하는 작업을 말합니다. 오래전부터 사람의 언어를 컴퓨터가 이해할 수 있도록 많은 연구들이 이루어져 왔지만 모든 인공지능 분야가 그렇듯 하드웨어 성능의 제한, 정제된 데이터의 부족 등의 다양한 이유로 연구에 많은 어려움이 있었습니다.
그러나 최근에는 고성능의 CPU, GPU, 메모리로 컴퓨터의 빠른 처리 속도 그리고 스마트폰이 개발되고 빠른 네트워크 통신 속도로 인터넷에 많은 데이터가 축적되면서 인공지능 연구와 개발이 수월하게 되었고 자연어처리 개발 또한 많은 발전을 이룰 수 있게 되었습니다.
자연어처리를 하기 위해서는 자연어의 특성을 잘 알고 있어야 합니다. 각각의 언어마다 가진 고유의 특성들이 있고 언어마다 형태가 다르기 때문에 컴퓨터가 이해하기 쉽게 잘 정리해서 알려줘야 좋은 성능의 인공지능 모델이 나올 수 있습니다.
자연어처리는 잘 드러나진 않지만 정말 많은 곳에서 사용되고 있습니다. 음성인식, 문장 분리, 내용 요약, 질문 분류, 질문 생성, 질의응답, 챗봇, 번역, 맞춤법 검사, 텍스트 분류, 비식별화 등 언어가 사용되는 모든 곳에 사용될 수 있습니다. 그렇기 때문에 한국의 인공지능 기술 발전을 위해 자연어 처리는 인공지능에서 필수 연구 분야이며 앞으로도 많은 진전이 필요한 분야입니다.
2. 한국어와 언어모델
한국어는 다른 언어들과는 다른 특성들을 가지고 있습니다. 영어와 비교해보자면 영어는 문장에서 어형 변화 없이 단어의 위치로 문법적 기능이 정해지는 고립어에 가까운 언어이므로 주어진 단어 이후에 어떤 문장 성분이 올지 예측이 가능하지만, 한국어는 어근에 어미가 결합하여 의미가 변화하는 교착어 특성이 강한 언어이므로, 어순이 크게 중요하지 않고, 문장의 앞 뒤 맥락에 의해 생략되는 단어가 있음에도 의미 전달이 가능합니다.
예를 들어 보면 다음과 같습니다.
“나는 학교에서 공부를 한다.”
“학교에서 나는 공부를 한다.”
“학교에서 공부를 한다.”
“나는 공부를 한다 학교에서.”
“나는공부를학교에서한다.”
예시처럼 한국어는 단어 예측이 다른 언어보다 훨씬 까다롭기 때문에 확률에 기반한 한국어 언어 모델 개발에 어려움이 있습니다. 또한, 한국어는 5번처럼 띄어쓰기를 하지 않아도 의미 전달이 되기 때문에 데이터를 만들 때 문장의 띄어쓰기가 제대로 지켜지지 않는 데이터가 많아 학습 데이터를 만드는 데에도 많은 노력과 시간이 필요합니다. 띄어쓰기가 제대로 되지 않으면 데이터 전처리에서 제대로 된 형태소로 분리되지 않고 잘못된 데이터가 학습 데이터로 들어가면 좋은 성능의 모델이 나오지 않기 때문에 한국어 언어 모델 개발이 다른 언어 모델보다 개발이 더 어렵다고 할 수 있습니다.
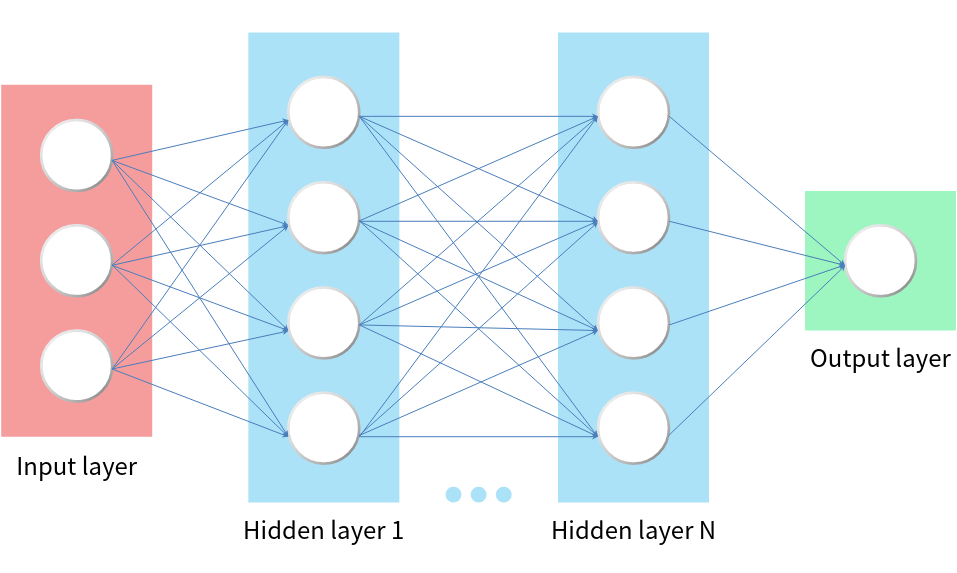
fully connected layer
자연어처리 언어모델은 규칙기반(rule-based)과 확률에 기반한 언어모델로 나뉠 수 있고 확률모델은 전통적인 통계기법으로 할 수 있지만 인공신경망으로도 구현할 수 있습니다. 인공신경망 학습을 진행할 때 Layer가 얕으면 Shallow한 형태, Layer를 많이 쌓아 학습하게 되면 Deep한 형태가 되는데 Layer가 Deep한 형태로 학습(Learning)하는 것을 딥러닝(Deep Learning) 모델이라고 부릅니다. 모든 인공지능 모델이 그렇듯 한국어 언어모델은 도메인이나 요구사항이 어떤 것인지에 따라 모델 구성이 달라질 수 있고 한국어 학습데이터 구성도 달라질 수 있습니다. 그래서 개발할 때 원하는 서비스에 맞는 양질의 데이터의 확보는 언어모델 개발만큼 중요합니다.
3. 자연어처리 데이터
한국어 자연어처리에 대한 인식은 한동안 좋지 못했습니다. 언어모델은 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 말뭉치의 양이 클수록 인식 정확도와 성능이 높아지는데 한국어로 된 언어 말뭉치 자료가 부족했기 때문입니다.
국내에서는 지난 1998년부터 정부가 ‘21세기 세종계획’을 통해 ‘세종 말뭉치(문장 모음)’를 구축해왔는데 2007년 이후로 사업이 중단되면서 영어 말뭉치 300억 어절, 중국 300~800억 어절, 일본 150억 어절보다 한국어 말뭉치 자료가 상대적으로 많이 부족한 상황이었습니다. 그러나 다행히 2017년을 시작으로 정부 예산으로 국립국어원에서 “모두의 말뭉치”를 구축하여 2022년까지 150억 어절 규모의 말뭉치를 구축할 예정이라고 하니 한국어 자연어처리기술의 미래가 밝다고 할 수 있습니다[2].
자연어처리기술에서 사용하는 학습 데이터는 도메인에 따라 다양한 형태로 데이터를 만들어 학습시킬 수 있습니다. 그러나 데이터도 사람들이 많이 사용하는 데이터나 학습에 필수적으로 들어가야 하는 데이터나 오랜 기간 축적해야하는 데이터의 경우, 표준을 정해 여러사람들이 데이터를 함께 만들고 연구하면 더 좋은 데이터가 나올 것입니다.
한국정보통신기술협회에서는 TTA 표준으로 여러 기관에서 사용한 품사 태그 세트를 바탕으로 “형태소 태깅 말뭉치 작성용 품사 태그 세트”를 작성하여 말뭉치 데이터의 재사용성 및 공유를 가능하게 하였습니다. 이 외에도 개체명 인식, 동음이의어/다의어 분석, 의존 구문분석, 의미역 인식 등 컴퓨터가 한국어의 고유 의미, 문맥 등을 파악할 수 있도록 정제된 데이터들이 데이터 표준에 따라 만들어지고 있으며, 이런 연구 개발자들 간의 약속을 통해 더 질 좋은 한국어 형태소 분석 데이터가 만들어져 한국어 자연어처리 모델 성능도 나날이 좋아지고 있는 것 같습니다. 국립국어원의 “모두의 말뭉치” 또한 데이터 라벨에서 약간의 다른 부분이 있을 수도 있지만 대부분 표준에 맞춰 제작되었다고 할 수 있습니다.
4. 언어모델 전처리과정
자연어처리기술에서 사용되는 언어 모델을 학습하기 위해선 우선 특성에 맞는 데이터가 있어야 합니다. 양질의 데이터가 많으면 많을수록 좋을 수도 있지만 데이터가 한쪽으로 치우쳐 있으면 좋은 모델이 될 수 없기 때문에 학습 데이터에 대한 전처리 과정이 꼭 필요합니다. 모델 특성에 맞게 학습될 수 있도록 데이터 전처리가 필요한데 전처리를 어떻게 처리하냐에 따라서도 성능에 많은 영향을 미칠 수 있습니다.
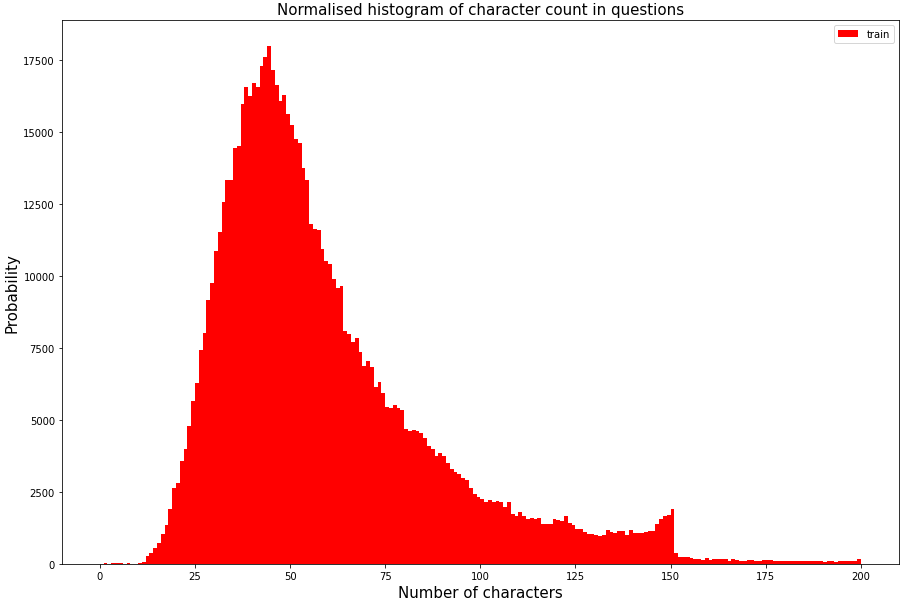
그래프는 학습데이터에 들어가는 문장들의 길이를 시각화한 것 입니다. 이렇게 시각화된 데이터를 비교 분석하여 학습데이터에 들어갈 문장들을 가공하는 전처리작업이 필요합니다.
전처리과정이란 텍스트 토큰화 과정이나, 데이터가 골고루 분포될 수 있도록 너무 문장이 길거나 짧은 데이터를 제거하거나 자를 수도 있고,