요약
이 글은 Claude Code의 핵심 설정 파일인 CLAUDE.md를 효율적으로 관리하기 위한 컨텍스트 엔지니어링 전략을 다룹니다. 무분별한 규칙 추가가 오히려 AI의 성능을 저해하는 컨텍스트 부패(Context Rot) 현상을 설명하고, 이를 방지하기 위한 JIT(Just-In-Time) 전략, 메모리 계층 구조 활용, 그리고 안드레 카파시(Andrej Karpathy) 스타일의 간결한 지침 작성법을 제시합니다. 단순한 프롬프트 작성을 넘어 토큰 효율성을 극대화하고 AI의 추론 정밀도를 높이는 실전적인 운영 노하우를 제공하는 글입니다.
서론
Claude Code를 본격적으로 쓰기 시작한 사람들이 가장 자주 부딪히는 벽이 있습니다. “/init을 하면 자동으로 만들어지는 CLAUDE.md는 어떤 역할을 하는 거지?”, “CLAUDE.md는 어떻게 관리해야 할까?” 같은 활용법에 대한 궁금증이죠. 사실 CLAUDE.md에 대한 정해진 규칙이나 활용법은 없습니다. 프로젝트의 특성이나 운영 방식이 회사·팀·개인마다 모두 다르기 때문입니다. 다만, 정해진 규칙이 없는 CLAUDE.md 파일에도 효율적으로 관리하는 방법은 분명히 존재합니다. 저는 이러한 컨텍스트 문서 관리를 어떻게 하면 효율적으로 할 수 있는 지를 연구 자료와 공식 문서, 그리고 사람들이 많이 채택하고 있는 방법들(ex. Andrej Karpathy Skills)을 통해 소개해보려고 합니다.
조금만 찾아보면 여러 사이트에서 CLAUDE.md 작성 가이드나 권장 사항을 쉽게 찾아볼 수 있습니다. 그중에는 “Claude가 실수할 때마다 CLAUDE.md에 규칙이나 규약을 추가하라”는 권장 사항도 있습니다. 이를 본 우리는 설명에 따라 요구사항을 분명히 CLAUDE.md에 적었지만 Claude가 이를 무시하는걸 종종 목격하게 되며, 대문자로 IMPORTANT를 쓰고 NEVER를 외쳐도 같은 실수를 반복하는것을 경험하게 됩니다. 결국 더 자세히 적고 더 많은 예외사항을 추가하다 보면 작성된 CLAUDE.md는 정리되지 않은 복잡하고 거대한 규약집이 되어버리기 마련입니다.
이렇게 CLAUDE.md 관리를 하지 않으면 Claude Code를 사용할수록 데이터가 계속 쌓여 어떤 내용이 담겨 있는지 파악하기 힘들어집니다. 더 흥미로운 사실은 그렇게 길어진 CLAUDE.md가 오히려 Claude의 성능을 떨어뜨리는 주범이라는 점입니다. 이 글은 그 이유를 정리하고, 컨텍스트를 어떻게 관리해야 토큰도 아끼고 AI 성능도 함께 끌어올릴 수 있는지를 다룹니다.
이미 Claude Code를 어느 정도 쓰고 계신 분들을 대상으로, “컨텍스트가 뭐예요?” 같은 기초보다는 실제 운영에서 부딪히는 문제와 해법에 무게를 두려고 합니다.
기술 개요
프롬프트 엔지니어링에서 컨텍스트 엔지니어링으로
지난 몇 년간 우리는 프롬프트 기법에 익숙해졌습니다. 페르소나를 어떻게 부여할지, few-shot 예시를 어떻게 구성할지, CoT(Chain-of-Thought)를 어떻게 유도할지를 우리는 잘 알고 있습니다. 그런데 Anthropic은 이미 “프롬프트만 잘 쓰면 되는 시대는 끝났다”는 입장을 명확히 한 상태입니다. 프롬프트 엔지니어링이 단발성 작업을 위한 기술이라면, 컨텍스트 엔지니어링은 에이전트가 여러 단계의 복잡한 작업을 수행할 때 필요한 더 포괄적인 개념입니다.

컨텍스트 엔지니어링이란
컨텍스트 엔지니어링은 LLM 추론(생성) 과정에서 시스템 프롬프트, 대화 히스토리, 외부 검색 문서, 도구 실행 결과, 메모리 등 컨텍스트 창에 들어오는 모든 토큰을 전략적으로 설계·관리하는 것을 말합니다.
이러한 컨텍스트 엔지니어링은 크게 Write(쓰기), Select(선택), Compress(압축), Isolate(격리) 네 가지로 나눌 수 있습니다.
- Write: 작업 중간 결과나 상태를 파일이나 메모리에 저장합니다. Claude Code의 메모리 시스템 등이 대표적입니다. 컨텍스트가 길어질 때 이걸 새 세션에 다시 로드해서 이어갑니다.
- Select: RAG(Retrieval-Augmented Generation)가 핵심 예시입니다. 전체 문서를 다 넣는 게 아니라, 쿼리에 관련된 청크만 검색해서 넣는 방식입니다.
- Compress: 대화 히스토리나 도구 실행 결과를 요약해서 토큰을 줄입니다. Anthropic의 경우 prompt caching을 통해 비용도 함께 절감할 수 있습니다.
- Isolate: 모든 컨텍스트를 하나의 모델 창에 넣는 대신, 특화된 시스템들로 컨텍스트를 분산시킵니다. 멀티 에이전트 아키텍처가 대표적입니다.
이 분류 자체보다 중요한 건, 각 전략이 토큰을 다르게 다룬다는 점입니다. Compress는 토큰을 줄이지만 정보 손실이 있고, Isolate는 토큰을 늘리지 않지만 다중 에이전트 비용이 듭니다. 어떤 전략을 언제 쓸 지가 핵심이지, 모든 전략을 항상 쓸 필요는 없습니다.
Context Rot : “많이 넣을수록 똑똑해진다”는 착각
LLM에 모든 정보를 주고 지시하면 잘할 거라고 생각하지만, 너무 많은 정보(긴 입력 토큰)를 제공할 때 모델의 정확도가 오히려 떨어집니다. 이러한 현상을 Context Rot이라고 합니다.
GPT-4.1, Claude 4, Gemini 2.5, Qwen3을 포함한 18개 최신 모델을 통제된 실험 환경에서 평가한 결과, 단 하나의 예외 없이 모든 모델이 입력 길이가 길어질수록 성능이 저하되었습니다.
Context Rot이 발생하는 기술적 이유는 크게 세 가지로 볼 수 있습니다.
- Lost-in-the-middle 현상: 모델은 긴 문맥의 앞부분이나 뒷부분은 잘 기억하지만, 중간에 숨겨진 정보를 찾는 데 약합니다.
- Attention 메커니즘 저하: 입력이 너무 길어지면 모델이 중요하지 않은 정보에 ‘주의(Attention)’를 분산시켜 핵심 정보를 놓칩니다.
- 위치 인코딩 제한: 매우 긴 입력 위치를 정확히 파악하지 못하는 모델의 기술적 한계가 있습니다.
최신 모델들이 100만 토큰 이상의 긴 문맥을 지원한다고 해도, 실질적인 복잡한 작업에서는 Context Rot으로 인해 성능이 보장되지 않을 수 있습니다. 따라서 단순히 긴 컨텍스트 윈도우에 의존하기보다, AI에게 제공하는 컨텍스트를 효율적으로 관리하는 기술이 무엇보다 중요합니다.
논문이 보여준 것 : 자동 생성 컨텍스트는 오히려 해롭다
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful…
흥미로운 논문이 한 편 있습니다. “Are Repository-Level Context Files Helpful for Coding Agents?” — 저장소 수준의 컨텍스트 파일이 코딩 에이전트에게 실제로 도움이 되는지 평가한 연구입니다.
실험 환경 (Benchmarks)
- SWE-bench Lite: 인기 오픈소스 레포지토리 기반
- AgentBench: 연구진이 직접 구축한 최신/마이너 레포지토리 환경
실험 조건 (Test Conditions)
- 컨텍스트 없음 (No Context)
- LLM이 자동 생성한 컨텍스트
- 인간이 직접 큐레이션한 컨텍스트
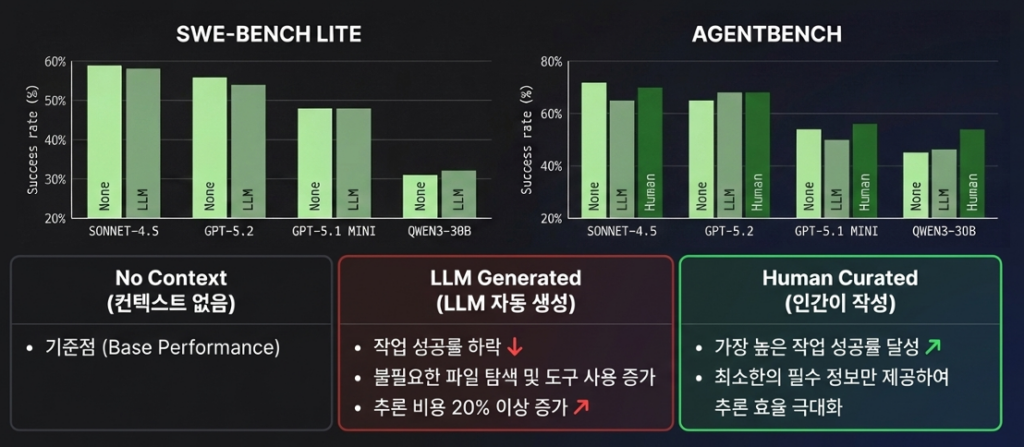
실험 결과, SWE-bench Lite에서 LLM이 자동 생성한 컨텍스트는 컨텍스트가 아예 없을 때보다 오히려 작업 성공률이 하락한 것을 확인할 수 있었습니다. 그리고 AgentBench에서는 인간이 직접 큐레이션 한 컨텍스트가 Sonnet-4.5를 제외한 대부분의 모델에서 가장 높은 성공률을 기록했습니다. 이 실험을 통한 결론은 두 가지로 요약할 수 있습니다.
- 컨텍스트 파일의 불필요한 요구 사항은 작업을 오히려 어렵게 만들고, 막대한 추론 비용과 시간 낭비를 초래합니다.
- 사람이 작성한 컨텍스트 파일은 최소한의 요구 사항만 기술해야 합니다.
현재는 Opus 4.7까지 나왔기 때문에 추가적인 실험이 필요할 수도 있지만, 그럼에도 해당 연구가 시사하는 바는 명확합니다. 같은 모델이라도 컨텍스트를 어떻게 구축하느냐에 따라 AI 코딩의 품질이 달라질 수 있다는 것입니다. 같은 모델을 사용해도 사용하는 사람에 따라 결과물이 다르다면, 이 또한 개인의 능력이고 경쟁력이 될 수 있다는 생각이 드는 대목입니다.
Claude Code 컨텍스트 동작 구조
결국 컨텍스트 관리의 본질은 “무엇을, 어디에 둘 것인가”의 문제입니다. 내가 원하는 대로 좋은 결과를 얻으려면 Claude Code가 컨텍스트를 어떻게 다루는지 먼저 이해해야 합니다.
3가지 컨텍스트
1. System prompt ← Anthropic이 작성, 사용자 제어 불가
2. Memory files ← CLAUDE.md, Skills, Rules 등 사용자가 정의
3. User + AI 대화 ← 실제 채팅 내용우리가 손댈 수 있는 건 2번과 3번입니다. 그리고 2번 안에서도 항상 로드되는 것과 필요할 때만 로드되는 것이 나뉩니다.
Memory files 로딩 구조
세션 시작 시 자동 주입 (항상 로드)
├── 1. user CLAUDE.md (~/.claude/CLAUDE.md) ← 모든 프로젝트
├── 2. project CLAUDE.md (./CLAUDE.md) ← 프로젝트 단위
├── 3. CLAUDE.local.md (./CLAUDE.local.md) ← gitignore, 개인용
├── 4. rules (.claude/rules/*.md)
└── 5. MEMORY.md (첫 200줄만)
조건부 주입 (필요할 때만 로드)
├── 6. Skills (.claude/skills/)
├── 7. 토픽 파일들 (phase1.md 등, 온디맨드)
└── 8. 대화 컨텍스트 (현재 세션 메시지)Claude가 프로젝트 컨텍스트를 로딩하는 과정에서, 모노레포 구조에서는 부모 디렉토리의 CLAUDE.md 및 CLAUDE.local.md는 자동으로 함께 로드되고, 자식 디렉토리의 CLAUDE.md는 그 폴더에서 작업할 때 온디맨드로 로드됩니다.
예를 들어, 아래 모노레포 구조에서 claude 명령을 실행했을 때의 컨텍스트 로드는 다음과 같습니다.
myproject/
├── CLAUDE.md ← (A) 루트
├── frontend/
│ ├── CLAUDE.md ← (B) 프론트엔드용
│ └── src/
│ └── components/
└── backend/
└── CLAUDE.md ← (C) 백엔드용- myproject/에서 실행 → myproject/CLAUDE.md만 로드 (frontend/backend의 것은 자식이라 온디맨드로 로드)
- frontend/에서 실행 → myproject/CLAUDE.md + frontend/CLAUDE.md 로드
- backend/에서 실행 → myproject/CLAUDE.md + backend/CLAUDE.md 로드
우선순위
여러 위치에 CLAUDE.md가 있으면, 더 구체적인 것이 더 광범위한 것보다 우선합니다.
- 엔터프라이즈 정책
- → 유저 (~/.claude/CLAUDE.md)
- → 프로젝트 루트 (./CLAUDE.md)
- → 자식 디렉토리 CLAUDE.md
이 한 가지 원칙만 잘 잡고 있어도, 에이전트를 어떻게 만들지, Skill과 Rule을 어떻게 분리할지 자연스럽게 감을 잡을 수 있습니다.
@import 문법
CLAUDE.md 안에서 @path/to/file 문법으로 다른 파일을 포인터로 참조할 수 있습니다. 토큰 운영의 관점에서 꽤 중요한 기능입니다.
# Project Overview
See @README.md for project overview and @package.json for available npm commands.
# Additional Instructions
- Git workflow: @docs/git-instructions.md
- Personal overrides: @~/.claude/my-project-instructions.md핵심은 “포인터 vs 복사”입니다. CLAUDE.md에 내용을 통째로 복사해 넣지 말고, 파일 주소만 가리키게 하면 토큰을 훨씬 아낄 수 있습니다. 게다가 참조 대상 파일이 업데이트 되면 별도 동기화 없이 자동으로 반영되니 운영 비용도 줄어듭니다.
CLAUDE.md 작성 전략
이제 기본 설명은 끝났으니, 본격적으로 어떻게 작성하는 것이 효율적인지 이야기해 보려고 합니다.
WHAT / WHY / HOW 프레임
CLAUDE.md에는 이 세 가지면 충분합니다.
- WHAT — 기술 스택, 프로젝트 구조, 코드 베이스 지도. 모노레포라면 “각 앱이 무엇이고, 공유 패키지가 무엇이고, 각자 용도가 무엇인지”
- WHY — 각 부분의 목적. “이 모듈은 왜 존재하는가” 를 적어두면 Claude가 수정 범위를 오판하지 않습니다.
- HOW — 작업 방식. bun인지 node인지, 테스트·타입 체크는 어떤 명령으로 돌리는지
목표는 200줄 이하
실무 권장 값은 200줄 이하입니다.
- Claude Code 시스템 프롬프트 자체가 이미 약 50개의 지시를 차지합니다.
- 일부 팀이 운영하는 CLAUDE.md는 60줄 정도입니다.
- 각 줄의 지시마다 “이 줄을 빼면 Claude가 실수할까?”라고 자문해보고 아니라면 삭제하세요.
기본적으로 Claude 모델이 잘하는 건 CLAUDE.md에 작성할 필요가 없습니다. 영양가 없는 지시들이 담긴 CLAUDE.md는 정작 중요한 지시를 무시하게 만듭니다.
JIT(Just-In-Time) 전략
핵심은 Claude가 코드 전체를 미리 읽지 않게 하는 것입니다. CLAUDE.md에는 “어디를 보면 된다”는 지도만 두고, 디테일은 필요할 때 Claude가 직접 파일을 열도록 만듭니다.
실천 팁: /context 명령어로 주기적으로 토큰 사용량을 점검하면 어디서 토큰이 새는지 보입니다.
CLAUDE.md에서 빼야 할 것들
1) 코드 스타일 가이드 → linter + Hook으로
LLM에게 linter의 일을 시키지 마세요. LLM은 전통 linter보다 느리고 비쌉니다. 게다가 스타일 규칙은 프로젝트와 무관한 코드 스니펫들을 컨텍스트 창에 더해 성능을 떨어뜨립니다.
// .claude/settings.json
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [{ "command": "prettier --write $FILE" }]
}
]
}
}2) 긴 코드 스니펫 → 파일 경로 포인터로
스니펫은 금방 구식이 되고, 컨텍스트만 차지합니다. file:line 참조나 @import를 쓰세요.
Before:
# Auth Pattern
... 40줄짜리 코드 블록 ...After:
# Auth Pattern
See `src/auth/authenticate.ts:12-54` for the canonical auth pattern.3) 가끔만 필요한 도메인 지식 → Skills로
CLAUDE.md는 매 세션마다 로드되므로 광범위하게 적용되는 내용만 넣어야 합니다. 결제 흐름, DB 마이그레이션처럼 가끔만 필요한 지식은 Skills로 분리하세요. Skills는 관련성이 있을 때만 온디맨드로 로드됩니다.
.claude/skills/
├── payment-flow/
│ └── SKILL.md
└── db-migration/
└── SKILL.mdAdvisory vs Deterministic — 판단 기준
뭘 어디에 둘지 고민 될 때, 이 질문 하나면 됩니다.
“이게 반드시 매번 일어나야 하는가?”
- YES → Hook 또는 settings.json (deterministic, 100% 실행)
- NO, 상황에 따라 판단 → CLAUDE.md (advisory, 약 80% 준수)
포매팅, 린트, 보안 체크처럼 무조건 일어나야 하는 것들은 Hook이 정답입니다.
압축하지 말고 새로 시작하기
/compact로 압축해도 장기 프로젝트에서는 불필요한 정보가 계속 쌓입니다. Anthropic이 권장하는 해법은 아예 대화를 종료하고 새로 시작하는 것입니다.
현재 작업 내용을 다음 세션에서 알 수 있도록 기록하는 루틴을 만들어야 합니다.
- 작업 끝에 명확한 git 커밋 메시지를 남기기
- 진행 상황 문서(예:
PROGRESS.md)를 작성하기 - 새 세션의 Claude가 단숨에 맥락을 파악할 수 있도록 만들기
꼭 /compact를 써야 한다면 무엇을 보존할지 명시적으로 지정할 수 있습니다.
/compact focus on the API changes and the list of modified filesAI가 스스로 관리하는 구조화된 메모
AI에게 외부 파일에 자기 생각과 진행 상황을 기록할 권한을 주면 프로젝트 관리가 훨씬 좋아집니다. decisions.md 같은 파일을 두고 “작업 중 결정 사항이나 막힌 지점을 여기에 기록해”라고 지시해두면, 긴 세션에서도 길을 잃지 않습니다.
서브에이전트로 메인 컨텍스트 보호
메인 에이전트의 컨텍스트는 깨끗하게 유지하고, 전문화된 하위 에이전트가 격리된 컨텍스트에서 작업하게 하세요. 서브 에이전트로부터 깔끔하게 정제된 1,000~2,000 토큰 요약본을 메인에 전달하면, 메인 컨텍스트를 항상 쾌적하게 유지할 수 있습니다.
주의해야 할 점은, 너무 많은 하위 에이전트가 있으면 많은 토큰을 소모할 수 있기 때문에 작업이 겹치지 않도록 적절한 에이전트들로 구성해야 한다는 것입니다.
65줄의 CLAUDE.md 파일
AI는 가끔 사용자의 의도를 넓게 해석하고, 그럴듯하지만 애매한 해결책을 먼저 제시하기도 합니다. 그리고 일회성 코드를 생성해내며 빠르게만 돌아가는 코드를 찍어내어, 결국 유지보수에 드는 시간만 늘어나는 경우가 발생하기도 합니다.
이러한 AI 코딩의 문제점들을 Andrej Karpathy는 “AI가 만들어 내는 오류들은 구문의 오류가 아닌 개념적 오류이며, 성급하고 부주의한 주니어 개발자가 저지르는 종류의 실수”라고 설명하고 있습니다.
최근 Andrej Karpathy의 이러한 지적을 개선하기 위한 행동 지침이 만들어졌습니다. 그것은 andrej-karpathy-skills라는 이름의 CLAUDE.md 파일로, 65줄에 불과하지만 120k stars(2026년 5월 기준)를 받고 있으며, 내용도 좋고 컨텍스트 효율성에도 잘 들어맞는 문장들로 구성되어 있습니다. 저는 이 andrej-karpathy-skills가 얼마나 좋고 컨텍스트 구성에 있어 효율적인지에 대해 간단하게 제 견해를 담아보고자 합니다.
andrej-karpathy-skills
andrej-karpathy-skills/CLAUDE.md at main · multica-ai/andrej-karpathy-skills
군더더기 없는 이 지시문들은 LLM의 실패들을 최소화하는 데 중점을 둡니다.
| andrej-karpathy-skills | 차단하려는 LLM 실패 모드 |
|---|---|
| “Don’t hide confusion” | 모르면서 자신 있게 답하는 환각 |
| “Don’t pick silently” | 가능한 여러 해석들 중 임의로 하나 골라 실행하는 습관 |
| “No abstractions for single-use code” | 한 번 쓰는 코드에 인터페이스/추상 클래스 만드는 over-engineering |
| “No flexibility that wasn’t requested” | 요청 안 한 옵션·설정·확장점 추가하는 speculative generality |
| “No error handling for impossible scenarios” | 절대 안 일어날 케이스에 try/catch 도배하는 방어적 코드 비대화 |
| “Don’t improve adjacent code” | 부탁한 함수 고치다가 옆 함수도 “더 좋게” 바꿔 놓는 scope creep |
| “Don’t refactor things that aren’t broken” | 멀쩡한 걸 “더 깔끔하게” 리팩토링하는 자기만족 |
| “Match existing style” | 본인 취향대로 스타일 바꾸는 일관성 파괴 |
| “Define success criteria. Loop until verified” | 다 했다고 선언만 하고 검증 안 하는 false-completion |
forrestchang의 “Andrej Karpathy Skills” CLAUDE.md를 보면, 마치 신입 개발자에게 주는 가이드라인처럼 보입니다. 한 줄 한 줄이 모두 LLM의 전형적인 실수 패턴 하나씩을 차단하는 부정형 명령들로, 결국 시니어 개발자가 신입에게 알려주는 개발 노하우와 비슷합니다. 그리고 과한 것이 결코 좋은 것은 아니라는 절제의 기술을 알려주는 것처럼 느껴지기도 합니다. 우리는 이미 CLAUDE.md를 200줄 이하로 쓰는 게 좋다는 걸 알고 있지만, 단순히 ‘200줄 이하로 줄여야지’가 아니라 ‘무엇을 200줄에 담아야 하는가’를 고민해야 할 숙제처럼 느껴집니다.
부정형 활용
이 파일은 거의 전부가 “하지 마라” 명제로 되어 있습니다. 일반적으로는 긍정형 지시가 LLM에 더 잘 작동한다는 게 여러 연구에서 입증되었습니다. 다만 코딩 에이전트처럼 디폴트 행동이 강하게 편향된 영역에서는, 그 디폴트를 명시적으로 차단하는 부정형 제약이 토큰 효율 측면에서 유효할 수 있을 것으로 판단됩니다. LLM은 안 시키면 알아서 잘하는 게 아니라, 시키면 과하게 하는 게 디폴트라서, 행동 제약에 한해서는 긍정형보다 부정형이 더 효율적으로 보여집니다.
자기 점검 질문
“Would a senior engineer say this is overcomplicated?”같이 LLM이 스스로에게 던질 수 있는 질문이 들어가 있습니다. 이건 단순 지시가 아니라 자기 감독(self-supervision) 트리거로 보이며, Claude가 코드를 쓰기 전에 이 질문을 되새기게 만드는 효과가 있습니다.
검증 가능한 목표 변환 패턴
섹션 4의 “Add validation” → “Write tests for invalid inputs, then make them pass” 변환 예시는 모호한 요청을 검증 가능한 목표로 바꾸는 사고 절차를 LLM에게 가르치고 있는데, 이 문장은 TDD(Test-Driven Development) 마인드셋을 한 줄로 압축한 것으로 보입니다.
자체 평가 지표 명시
마지막에 등장하는 “These guidelines are working if: 불필요한 변경 사항이 줄어들고, 과도한 복잡성으로 인한 재작성이 줄어들며, 구현 후 오류가 발생한 후가 아니라 구현 전에 명확한 설명을 위한 질문이 제기됩니다.”와 같은 문장은 가이드라인의 운영 마인드셋을 주입하고 있으며, 작동 여부를 어떻게 판단할지 명시한 부분입니다.
LLM은 학습 데이터 특성상 디폴트로 신입 개발자의 행동 패턴을 보입니다. 의욕 넘치고, 더 많이 만들어주고 싶어하고, 이왕 손댔으니 옆도 정리하고 싶어 하고, 빨리 끝났다고 선언하고 싶어 하는 경향이 있습니다. 이 CLAUDE.md 파일은 그걸 정확히 시니어의 습관으로 교정하는 4개의 명제입니다.
| Karpathy가 지적한 문제 | CLAUDE.md 대응 섹션 |
|---|---|
| 잘못된 가정 | §1 Think Before Coding |
| 과도한 복잡화 | §2 Simplicity First |
| 의도치 않은 부작용 | §3 Surgical Changes |
| (검증 부재 — 위 셋의 공통 원인) | §4 Goal-Driven Execution |
65줄의 내용만으로 12만 개의 stars를 받았다면, 이미 수많은 개발자들에게 검증받은 내용이라고 생각됩니다. Andrej Karpathy Skills처럼 앞으로는 CLAUDE.md뿐만 아니라 모든 컨텍스트에 들어가는 행동 지침이나 규약, 정의들을 어떻게 간략하게 작성해야 하고, 어떻게 핵심만 명확히 전달해야 할지에 대한 많은 고민이 필요해질 것 같습니다.
결론
이 글의 출발점은 단순했습니다. “분명히 적었는데 왜 Claude가 무시할까?” 그 답은 결국 “너무 많이 적었기 때문”이라는, 다소 직관과 어긋나는 결론이었습니다. 그래서 컨텍스트 관리의 본질은 “무엇을, 어디에 둘 것인가”라는 한 문장으로 압축됩니다. “CLAUDE.md를 줄이고, 결정적 규칙은 Hook에 맡기고, 가끔 쓰는 지식은 Skills로 빼고, 메인 컨텍스트는 서브 에이전트로 보호하기.” 결국 각자의 자리에 맞게 옮기는 일입니다.
Andrej Karpathy Skills의 CLAUDE.md는 그 답의 한 가지 모범을 보여줍니다. “많이 담는 것”이 아니라 “무엇을 담지 않을지”를 결정하는 일이 핵심이라는 점입니다. 시니어 개발자가 신입에게 “이건 하지 마”라고 짚어주는 것처럼, LLM에게도 디폴트 행동 중 위험한 것들을 명시적으로 차단해 주는 것이 오히려 더 효율적일 수 있다는 사실은 곱씹어 볼 만합니다.
컨텍스트나 에이전트를 자동으로 관리해 주는 플러그인도 빠르게 늘어나고 있습니다. 다만 그런 도구를 잘 쓰려면 이 글에서 다룬 raw level 개념이 결국 출발점이 됩니다. 어떤 자동화 도구를 만나더라도 빠르게 이해하고 자기 워크플로우에 맞춰 조정할 수 있게 해주는 토대가 되어줄 것입니다.
참고 자료
- Anthropic, “Best Practices for Claude Code”
- Anthropic, “Sub-agents”
- Anthropic, “Memory — How CLAUDE.md files load”
- HumanLayer, “Writing a good CLAUDE.md”
- forrestchang, “andrej-karpathy-skills”
- “Are Repository-Level Context Files Helpful for Coding Agents?”
- Context Rot 관련 연구