요약
이 글은 한컴오피스 맞춤법 검사기의 자체 개발 가능성을 검토한 개인 프로젝트의 기록입니다. 범용 LLM의 일관성 문제와 과교정 경향을 분석하고, 이를 극복하기 위해 규칙 기반 교정과 KoBART 모델을 결합한 하이브리드 아키텍처를 설계했습니다. KoGPT-2에서 KoBART로의 전환 이유, 50개 이상의 규칙 엔진 설계, 글자 수 기반 검증 필터 구현 과정을 다루며, 프로토타입 개발부터 향후 한컴오피스 적용 계획까지의 여정을 공유합니다.
“맞춤법 틀리면 정 떨어진다”

안녕하세요, 한글개발팀에서 맞춤법 검사기 업무를 담당하고 있는 김민규입니다.
“맞춤법 틀리면 정 떨어진다.”
한 언론사의 설문 조사에 따르면, 맞춤법을 지키지 않았을 때 연인에게 가장 실망하는 순간 1위였다고 합니다. 비단 연인 사이만의 이야기가 아닙니다. 업무 메일이나 보고서, SNS에 이르기까지 맞춤법 실수는 생각보다 많은 사람에게 신경 쓰이는 요소입니다.
그래서 우리는 맞춤법 검사기를 사용합니다. 한컴오피스에도 오랫동안 제공되어 온 기능 중 하나입니다.
현재 한컴오피스의 맞춤법 검사기는 외부 전문 업체의 솔루션을 라이선스 형태로 제공하고 있습니다. 검증된 기술력을 갖춘 솔루션이지만, 외부 의존 구조로 인한 아쉬움도 존재했습니다.
“직접 만들어볼 수는 없을까요?”

사용자분들로부터 “이 단어 교정이 이상해요”라고 피드백이 들어와도, 저희가 바로 수정하기 어려운 구조입니다. 개발사에 요청을 전달하고 업데이트를 기다려야 하다 보니, 빠르게 대응하지 못하는 경우가 있었습니다.
이러한 문제의식 속에서 팀 내에서는 종종 다음과 같은 이야기가 오갔습니다.
“우리가 직접 만들어볼 수는 없을까요?”
“요즘 AI 기술이 좋아졌는데, 활용해 볼 수 있지 않을까요?”
이야기를 듣고 고민 끝에, 한 번 직접 맞춤법 검사기를 만들어 보기로 했습니다.
“그냥 AI로 맞춤법 검사하면 되는거 아닌가요?”

솔직히 저도 처음엔 그렇게 생각했습니다.
요즘 많이 사용되고 있는 ChatGPT, Gemini 와 같은 범용 AI를 통해 “맞춤법 고쳐줘”라고 하면 되는 거 아닐까요?
직접 해 본 결과, 다음과 같은 문제가 있었습니다.
같은 문장, 다른 결과
첫 번째 요청: "할수있어" → "할 수 있어"
두 번째 요청: "할수있어" → "할 수 있어요"어미가 바뀌었습니다. 범용 LLM은 확률 기반이라 매번 조금씩 다른 답을 합니다.
과잉 친절
입력: "오늘 날씨 좋다"
출력: "오늘 날씨가 좋네요"맞춤법만 고쳐달라고 했는데, 문장 자체를 바꿔버립니다. “더 자연스럽게” 만들려는 습성이 있습니다.
왜 틀렸는지 모름
“할수있어”가 왜 틀렸는지, 어떤 규칙을 위반했는지 알려주지 않습니다. 그냥 고쳐줄 뿐입니다.
느리고, 비쌈
문서 하나에 문장이 천 개라면? API 호출 천 번. 시간도, 비용도 만만치 않습니다.
결론: 범용 AI는 맞춤법 검사기를 “대체”할 수 없습니다.
그렇다면 어떻게 해야 할까요?
우리의 접근: 하이브리드

규칙 기반과 AI를 결합했습니다.
명확한 오류는 규칙으로 빠르게 잡고, 복잡한 문맥은 AI가 처리합니다. 그리고 AI가 과하게 고치려 하면, 필터가 막습니다.
이 글에서는 AI 맞춤법 검사기를 만들면서 겪은 시행착오와 기술적 결정들을 공유합니다.
- 왜 KoGPT-2를 포기하고 KoBART를 선택했는지
- 50개 이상의 규칙을 어떻게 설계했는지
- “글자 수가 늘면 거부”라는 단순한 규칙이 왜 효과적인지
시작합니다.
❗작성자는 AI 비전공자입니다. 내용과 정보가 부정확할 수 있으니 양해 부탁드립니다.
1. 첫 번째 시도: KoGPT-2

AI로 맞춤법 교정을 하려면 어떤 모델을 써야 할까요?
처음 선택한 모델은 KoGPT-2였습니다. 한국어로 사전학습된 대규모 언어 모델이고, 텍스트 생성 능력이 뛰어나다는 점에서 맞춤법 교정에도 적합할 것이라 생각했습니다.
문제 발생: 과교정
그런데 테스트 과정에서 예상치 못한 문제가 발생했습니다.
입력: "오늘 날씨가 조습니다"
기대: "오늘 날씨가 좋습니다"
실제: "오늘은 날씨가 좋습니다"“조습니다”를 “좋습니다”로 교정하는 것까지는 좋았습니다. 그런데 없던 조사 “은”이 추가되었습니다. 이런 현상이 여러 테스트에서 반복되었습니다.
원인 분석
GPT 계열 모델은 Autoregressive 구조입니다. 쉽게 말해, 이전 단어들을 보고 다음 단어를 “예측”하는 방식입니다. 문장을 이어쓰는 데 최적화되어 있습니다.
그러나 맞춤법 교정은 다릅니다. 입력 문장을 이해하고, 오류 부분만 정확히 수정한 문장을 출력해야 합니다. “이어쓰기”가 아니라 “변환”에 가깝습니다.
GPT 구조로는 이 문제를 근본적으로 해결하기 어렵다고 판단했습니다.
2. 두 번째 시도: KoBART

Seq2Seq 구조
KoBART는 Encoder-Decoder(Seq2Seq) 구조입니다.
- 인코더: 입력 문장 전체를 이해
- 디코더: 변환된 출력을 생성
입력을 먼저 “이해”하고, 그 이해를 바탕으로 출력을 “생성”하는 구조입니다. 맞춤법 교정처럼 입력과 출력이 유사하지만 일부만 다른 태스크에 적합합니다.
저희가 사용한 모델은 Soyoung97/gec_kr입니다. KoBART를 기반으로 한국어 문법 교정에 특화되어 있으며, ACL 2023에서 발표된 연구 결과물입니다.
개선된 결과
입력: "오늘 날씨가 조습니다"
출력: "오늘 날씨가 좋습니다"불필요한 조사 추가 없이 오류 부분만 정확히 교정되었습니다.
그래도 완벽하지는 않았습니다
KoBART로 전환한 후 대부분의 과교정 문제는 해결되었습니다. 하지만 간헐적으로 이상한 결과가 나오는 경우가 있었습니다.
입력: "되서 그래요"
출력: "자신이 없어서 그래요"모델이 문맥을 과도하게 해석하여 전혀 다른 문장을 생성하는 경우였습니다. 모델만으로는 100% 신뢰할 수 없다는 결론에 도달했습니다.
3. 해결책: 하이브리드 아키텍처

순수 딥러닝 모델의 한계를 인식하고, 새로운 접근법을 설계했습니다.
규칙 기반 + 딥러닝 + 검증 필터를 결합한 하이브리드 구조입니다.
처리 흐름
입력 → 유효성 검사 → 규칙 교정 → 모델 교정 → 검증 필터 → 출력각 단계가 역할을 분담합니다.
- 유효성 검사: 자음/모음만 있는 입력, 빈 문자열 등 필터링
- 규칙 교정: 명확한 패턴은 규칙으로 먼저 처리
- 모델 교정: 규칙으로 해결되지 않은 부분을 KoBART가 처리
- 검증 필터: 과교정 방지
왜 규칙을 먼저 적용할까요?
규칙 기반의 장점은 예측 가능성입니다.
- 동일한 입력에 항상 동일한 출력
- 오류 발생 시 규칙만 수정하면 됨
- 속도가 빠름
“할수있어” → “할 수 있어”처럼 명확한 패턴은 굳이 모델을 거칠 필요가 없습니다. 규칙으로 빠르게 처리하고, 모델은 복잡한 경우에만 개입하도록 했습니다.
4. 규칙 엔진 설계
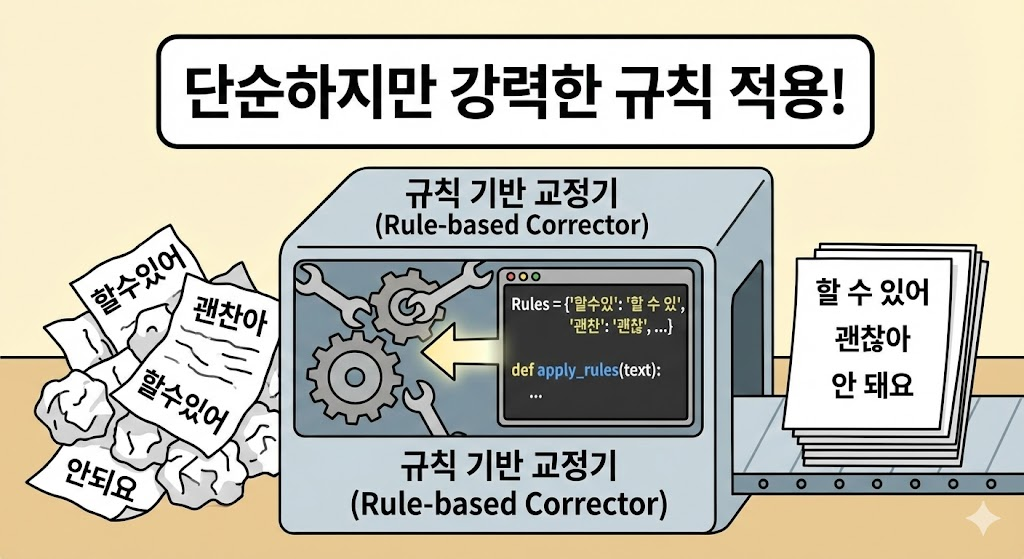
50개 이상의 규칙을 구현했습니다. 주요 카테고리는 다음과 같습니다.
받침 오류
"읽엇습니다" → "읽었습니다" (ㅅ/ㅆ 혼동)
"괜찬아" → "괜찮아" (ㅎ 받침 탈락)
"조습니다" → "좋습니다" (ㅎ 받침 탈락)띄어쓰기 오류
"할수있어" → "할 수 있어" (의존명사 '수')
"할때" → "할 때" (의존명사 '때')
"할것" → "할 것" (의존명사 '것')어미 오류
"안되요" → "안 돼요" (되/돼 혼동)
"않해요" → "안 해요" (안/않 혼동)
"할께" → "할게" (ㄹ게/ㄹ께)구현 방식
rules = {
"할수있": "할 수 있",
"할수없": "할 수 없",
"괜찬": "괜찮",
"안되요": "안 돼요",
# ... 50개 이상
}
def apply_rules(text):
for pattern, replacement in rules.items():
text = text.replace(pattern, replacement)
return text단순한 문자열 치환이지만, 실제 사용자 오류 패턴을 분석하여 규칙을 설계했기 때문에 적중률이 높습니다.
5. 검증 필터: 과교정 방지
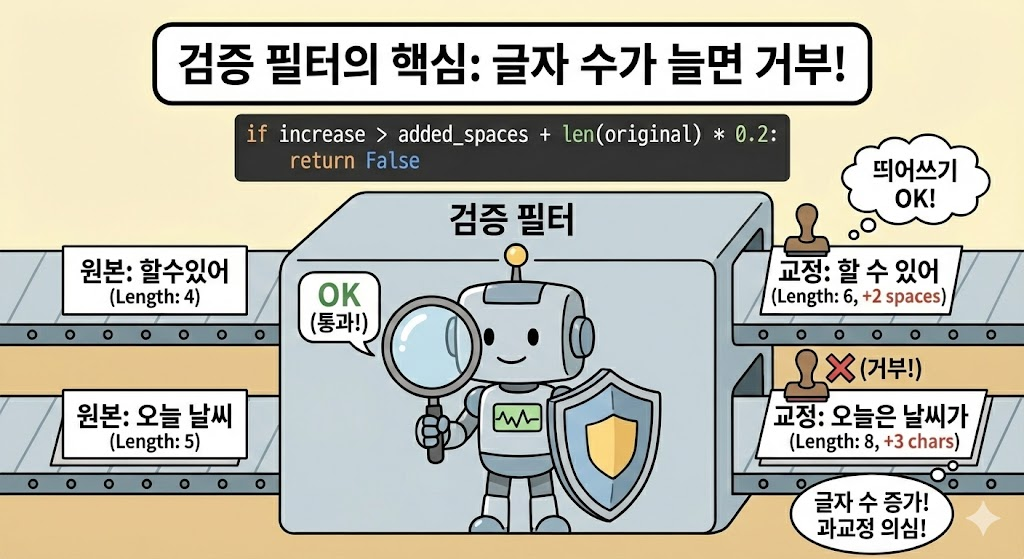
하이브리드 구조의 핵심은 검증 필터입니다.
핵심 로직
def validate_correction(original, corrected):
# 빈 결과 거부
if not corrected:
return False
# 글자 수 증가 거부 (띄어쓰기 제외)
if len(corrected) > len(original):
added_spaces = corrected.count(' ') - original.count(' ')
increase = len(corrected) - len(original)
if increase > added_spaces + len(original) * 0.2:
return False
return True왜 효과적일까요?
맞춤법 교정에서 글자 수가 크게 늘어나는 경우는 드뭅니다.
- “할수있어” → “할 수 있어” (띄어쓰기 2개 추가)
- “읽엇습니다” → “읽었습니다” (글자 수 동일)
- “괜찬아” → “괜찮아” (글자 수 동일)
반면 과교정은 대부분 글자 수가 늘어납니다.
- “오늘 날씨” → “오늘은 날씨가” (조사 추가)
- “되서 그래요” → “자신이 없어서 그래요” (문장 변경)
“글자 수가 늘면 거부”라는 단순한 규칙으로 과교정의 대부분을 필터링할 수 있었습니다.
6. 테스트

검증 범위
주요 오류 유형별로 동작을 확인했습니다.
- 받침 오류 (ㅅ/ㅆ 혼동, ㅎ 탈락 등)
- 띄어쓰기 오류 (의존명사 등)
- 어미 오류 (되/돼, 안/않 등)
- 유효성 검사 (빈 입력, 자음/모음만 있는 입력 등)
설계한 규칙 범위 내에서 의도대로 동작하는 것을 확인했습니다.
한계
현재는 프로토타입 단계입니다. 실제 서비스에 적용하려면 다음과 같은 추가 검증이 필요합니다.
- 실제 사용자 오류 로그 기반 대규모 테스트
- 엣지 케이스 및 예외 상황 테스트
- 기존 맞춤법 검사기와의 비교 평가
처리 속도
규칙 기반 패턴 매칭이 대부분의 오류를 빠르게 처리하고, 모델은 필요한 경우에만 개입하기 때문에 실시간 사용에 충분한 속도를 보였습니다.
7. 향후 계획: 한컴오피스에 적용하기

개발 중인 맞춤법 검사기는 Python 기반 프로토타입입니다. Hugging Face에서 모델을 불러와 사용하는 구조로, 온라인 환경이 필요합니다.
추후 한컴오피스에도 적용할 수 있도록 개발을 진행할 예정입니다.
검토 중인 방향은 다음과 같습니다.
모델 경량화
현재 KoBART 모델은 약 400MB 수준입니다. 오프라인 배포를 위해서는 용량을 줄일 필요가 있습니다. 양자화(Quantization)나 경량 모델로의 교체를 검토하고 있습니다.
오프라인 동작
현재는 Hugging Face 모델 허브에 의존하고 있어 인터넷 연결이 필요합니다. 한컴오피스에 적용하려면 모델을 로컬에 포함하여 오프라인에서도 동작하는 구조가 되어야 합니다.
테스트 케이스 확보
프로토타입 검증을 위한 최소한의 테스트만 진행한 상태입니다. 실제 서비스 적용 전에 다양한 오류 패턴과 엣지 케이스를 커버하는 충분한 테스트 케이스 확보가 필요합니다.
기존 인터페이스 호환
애플리케이션 수정 없이 적용 가능한 형태로 개발할 예정입니다.
구체적인 적용 방식은 추가 검토 후 결정될 예정입니다.
8. 결론

달성한 것
- 하이브리드 아키텍처: 규칙 + 딥러닝 + 검증 필터 구조 설계
- 규칙 엔진: 주요 맞춤법 오류 패턴 커버
- 과교정 방지: 단순하지만 효과적인 검증 로직
배운 것
순수 딥러닝의 한계
AI 모델은 강력하지만 예측 불가능한 결과를 낼 수 있습니다. 맞춤법 검사처럼 정확성이 중요한 기능에서는 이것이 큰 문제가 됩니다.
하이브리드의 힘
규칙과 딥러닝의 장점을 결합하면 더 안정적인 결과를 얻을 수 있습니다. 규칙이 예측 가능성을 제공하고, 딥러닝이 유연성을 제공합니다.
단순한 검증의 효과
“글자 수가 늘면 거부”라는 단순한 규칙이 과교정의 대부분을 방지했습니다. 복잡한 문제에 단순한 해결책이 효과적일 때가 있습니다.
앞으로
현재 맞춤법 검사기는 프로토타입 단계입니다. 모델 경량화, 오프라인 동작 지원, 테스트 케이스 확보 등을 거쳐 한컴오피스에 적용하는 것을 목표로 하고 있습니다.
맞춤법 검사기를 직접 만들어보면서, 단순해 보이는 기능에도 많은 기술적 고민이 필요하다는 것을 배웠습니다. 이 경험이 비슷한 고민을 하시는 분들께 도움이 되었으면 합니다.