요약
이 글은 Microsoft Word의 DOC(.doc) 을 대상으로, 문서가 내부적으로 어떻게 저장되고 파싱되는지를 단계적으로 설명합니다. OLE2 기반 파일 구조를 바탕으로 WordDocument, Table, Data Stream의 역할을 살펴보고, 문서 해석의 핵심인 FIB(File Information Block) 를 중심으로 데이터 위치와 크기를 추적하는 방식을 다룹니다. 또한 CP 개념과 PLC·STTB·RG 등 주요 데이터 집합 구조를 통해 텍스트와 속성이 어떻게 매핑되는지 설명하며, MS-DOC 공식 명세을 활용해 필요한 데이터명을 찾고 구조를 해석하는 방법을 소개합니다. 마지막으로 Clx 예제를 통해 실제 바이너리 데이터 읽기와 파싱 과정(C++ 코드) 을 구체적으로 보여주며, DOC 포맷 내부 구조를 이해하고 문서 데이터를 직접 해석하는 기초를 제시합니다.
서론
안녕하세요, 한글과컴퓨터에서 한워드를 개발하고 있는 유영입니다.
이번 글은 비전공자분들도 쉽게 DOC(.doc) 포맷의 구조를 이해하고, 더 나아가 파싱 방법까지 접해보실 수 있도록 정보를 드리기 위해 작성했습니다.
워드로 문서 작업을 자주 하는 분들이라면 .docx와 .doc라는 확장자가 매우 익숙하실 텐데요. 최근에는 대부분의 문서가 기본으로 .docx 확장자로 저장되다 보니, 두 형식이 정확히 어떻게 다른지 모른 채 프로그램이 저장해 주는 대로 사용하는 경우가 많습니다.
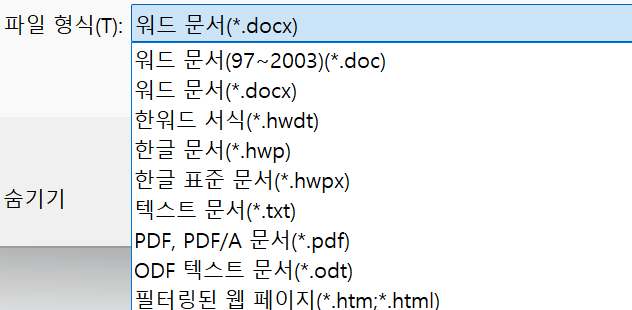
파일 형식 드롭다운을 내려 살펴보면, .doc 옆에 (97~2003)이라는 숫자가 붙어있는 것을 볼 수 있습니다. 아래에서 다시 설명하겠지만, 이는 DOC가 1997년부터 2003년 사이에 사용된 과거의 포맷임을 의미합니다.
그렇다면, 이제는 잘 사용되지 않는 옛 파일 형식을 굳이 공부해야 할까요?
당연히 저희는 DOC 포맷에 대해 공부해야 합니다. 여전히 기업이나 공공기관에는 오래 보존해야 하는 중요한 문서들이 많고, 그중 상당수가 여전히 .doc 형식으로 남아있기 때문입니다. 이것이 바로 우리가 DOC 포맷에 대해 끊임없이 연구하고 학습해야 하는 이유입니다.
DOC 포맷 소개
① DOC 포맷이란?
Word Binary File Format(.doc)는 워드 문서 처리를 위한 바이너리 형식의 파일 확장자입니다.
물론 .doc로 끝난다고 모두 같은 DOC 포맷은 아닙니다. 저희가 일반적으로 말하는 DOC 포맷은 MS Word 97 이후에 사용된 .doc 확장자로, [MS-DOC] 공식 명세를 따르고 있습니다. MS Word 97보다 더 이전에 나온 .doc 문서는 확장자만 같을 뿐 구조는 명세를 따르지 않았습니다.
| Word 6.0 / 95 | .doc 확장자를 사용하지만, 매우 오래된 바이너리 포맷명세도 비공개되어 있으며 구조도 다름 |
|---|---|
| Word 97 ~ 2003 | 우리가 일반적으로 말하는 DOC[MS-DOC] 공식 명세를 따름 |
| Word 2007 ~ | 이후부터는 .docx 포맷을 사용 |
💡DOC 포맷이 DOCX 포맷으로 대체된 이유?
DOC 포맷은 바이너리 형식이기 때문에 .docx 확장자처럼 xml 파일로 확인할 수 없습니다.
xml 파일이 묶인 zip 형식으로 이루어진 DOCX 포맷이 더욱 개발자 친화적이고, 용량도 압축되어 있죠.
이러한 한계를 보완하기 위해, 가볍고 구조가 명확한 XML 기반의 DOCX 포맷이 도입되었습니다.
② OLE2(Object Linking and Embedding 2.0)
.doc 파일은 OLE2(Object Linking and Embedding 2.0)로 저장되어 있습니다. OLE2는 Microsoft가 만든 Compound File Binary Format입니다. 바이너리 파일 내부가 디렉터리/파일처럼 동작합니다.
그렇다고 .docx처럼 실제 파일이 압축되어 있는 것은 아니고, 프로그램이 바이너리 파일을 읽을 때 논리적으로 구분할 수 있도록 저장하는 것입니다.
OLE2 파일은 내부를 구성하는 기본 단위로 Storage와 Stream이라는 개념을 사용합니다.
- Stream: 파일처럼 동작하는 데이터 단위
- Storage: 여러 Stream을 담는 디렉터리 형태의 컨테이너
③ 기본 개념
사람의 눈으로 읽을 수도 없는 DOC 포맷을 파싱하고 해석하려면, 반드시 필요한 문서가 있습니다.
MS-DOC 공식 명세 (Microsoft Open Specifications)
이 문서는 Microsoft에서 공개한 DOC 포맷의 공식 스펙으로, 문서 내부 구조와 각 데이터의 위치, 바이트 크기, 의미가 상세히 정의되어 있습니다.
MS-DOC 공시 명세를 보며 필요한 문서 정보의 위치와 바이트 크기를 찾아야 하는데요. 이 명세를 살펴보다 보면 자주 등장하는 용어들이 눈에 띕니다. 그에 대한 기본 개념들을 미리 알아보고자 합니다.
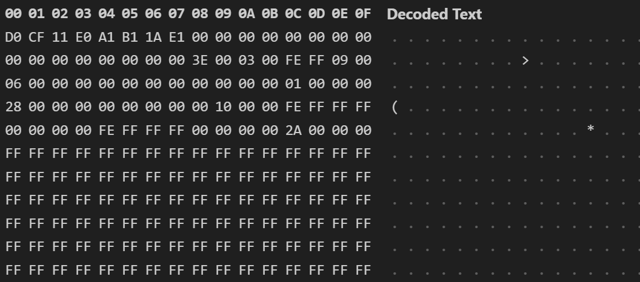
FIB (File Information Block)
문서에 대한 정보와 문서 구성 요소의 위치 및 크기를 지정하는 데이터입니다. 거의 모든 데이터는 FIB를 기준으로 위치와 크기를 확인할 수 있으므로, 매우 중요한 데이터입니다.
모든 DOC 포맷은 스트림의 시작 오프셋(offset 0)에 FIB가 위치해야 합니다.
- fc: Stream 기준 물리적인 위치 / lcb: 데이터의 바이트 크기
CP (Character Position)
문서 내에서 문자의 논리적인 위치를 나타내는 인덱스입니다.
문서가 어떤 문자 순서로 구성되어 있는지는 CP[n]로 나타내며, 예를 들어 CP 0은 문서 내 첫 번째 문자에 해당합니다.
CP의 개수는 문자 수 + 1이며, 마지막 CP는 끝점을 명시하기 위한 값입니다.
| CP0 | CP1 | CP2 | CP3 | CP4 | CP5 | CP6 |
| H | e | l | l | o | ! |
④ DOC 파일 구조
OLE2로 이루어진 .doc 파일은 그럼 어떤 Storage와 Stream을 가지고 있을까요? 주요 파일 구조를 통해 문서가 어떻게 나뉘어 있는지 알아봅시다.
WordDocument Stream
DOC 파일에서 가장 중요한 Stream으로, 반드시 0번 오프셋에 FIB가 위치해 있어야 합니다. 이 Stream에는 문서의 텍스트 내용과 앞서 설명한 FIB 정보가 담겨 있습니다.
이 Stream에서 FIB를 읽어야 다른 Stream의 데이터를 참조할 수 있겠죠?
1Table Stream / 0Table Stream
1Table과 0Table은 둘 중 하나가 반드시 존재해야 합니다. 접두어에 붙는 숫자는 WordDocument Stream의 FIB에서 base.fWhichTblStm 값에 따라 결정됩니다. 이 Stream에는 글자 모양, 문단 스타일, 표 정보, 텍스트 정보 등 문서의 구조를 결정하는 데이터들이 모두 담겨 있습니다.
SummaryInformation Stream, DocumentSummaryInformation Stream
저희가 파일 탐색기에서 파일을 우클릭해 속성을 눌렀을 때 보이는 정보들은 여기에 모두 저장됩니다. 문서의 제목, 지은이, 마지막 저장 날짜 등의 메타데이터를 담고 있습니다.
Data Stream
문서 내에 삽입된 그림, 도형, 이미지 등의 바이너리 데이터가 저장되는 곳입니다. 텍스트와 섞이지 않고 별도의 공간에 바이너리 데이터 형태로 존재하며, 본문에서는 이 데이터의 위치를 가리키는 방식으로 개체를 표시합니다.
⑤ 주요 데이터 집합 구조
데이터는 복합 데이터로 이루어져 있을 수도 있고, 단일 데이터로 이루어져 있을 수도 있습니다. 복합 데이터의 경우 데이터 집합이 어떤 구조를 띠고 있는지에 대한 접두어를 사용합니다. 저희는 접두어로 데이터 집합인지, 또 어떤 구조로 이루어져 있는지를 대략적으로 파악할 수 있습니다.
PLC
연속적인 문서 내용 범위에 대한 속성값을 정의하는 구조입니다. CP 배열이 먼저 나오고, 그 뒤에 데이터 요소 배열이 구성되어 있습니다. 데이터 요소 개수는 CP 개수 -1로, 한 CP 범위당 하나의 데이터 요소를 가져야 하기 때문입니다. (CP0~CP1 = Data0)
- 데이터 요소 개수 구하기: (PLC 크기 – CP 크기) / (CP 크기 + 데이터 크기)
PLC 구조
├─ aCP # 문자 위치(논리) 배열
│ ├─ CP 0 (4 bytes)
│ ├─ CP 1 (4 bytes)
│ ├─ ...
│ └─ CP n (4 bytes)
└─ aData # 데이터 요소 배열
├─ Data 0
├─ Data 1
├─ ...
└─ Data n - 1STTB
문자열 배열에 헤더가 추가된 테이블입니다.
STTB 구조
├─ fExtend (variable) # 데이터(0xFFFF)가 존재할 경우 2 bytes 문자, 없으면 1 byte
├─ cData (2 bytes) # 요소 개수
├─ cbExtra (2 bytes) # ExtraData 크기
└─ aRecord
├─ Record 0
│ ├─ cchData 0 (1 byte / 2 bytes) # Data 문자 수
│ ├─ Data 0 (fExtend * cchData bytes) # 문자열
│ ├─ ExtraData 0 (variable)
├─ Record 1
├─ ...
└─ Record nRG
단순한 데이터 배열입니다 (Repeat Group). 추가 데이터 없이 단순하게 데이터만 나열해줍니다.
DOC 포맷 파싱을 위한 데이터 찾기와 읽기
① 데이터 구조 이름 찾기
눈으로 확인할 수도 없는 바이너리 파일에서 필요한 데이터를 찾는 과정은 상당히 까다롭습니다. 이를 위해 MS-DOC 공식 명세를 적극 활용해야 합니다.
다만 MS-DOC 공식 명세가 있더라도, 데이터의 이름을 알지 못하면 검색 자체가 어려운 경우가 많습니다. 이럴 때 다음과 같은 방법을 활용할 수 있습니다.
MS-DOC의 2.4 Document Content 확인
MS-DOC 공식 명세의 2.4 Document Content 부분에는 텍스트 찾기, 단락 경계, 표 등 문서의 내용을 구성하는 방법이 표기되어 있습니다. 해당 부분의 링크를 따라가다 보면 필요한 데이터의 이름을 찾을 수 있습니다.

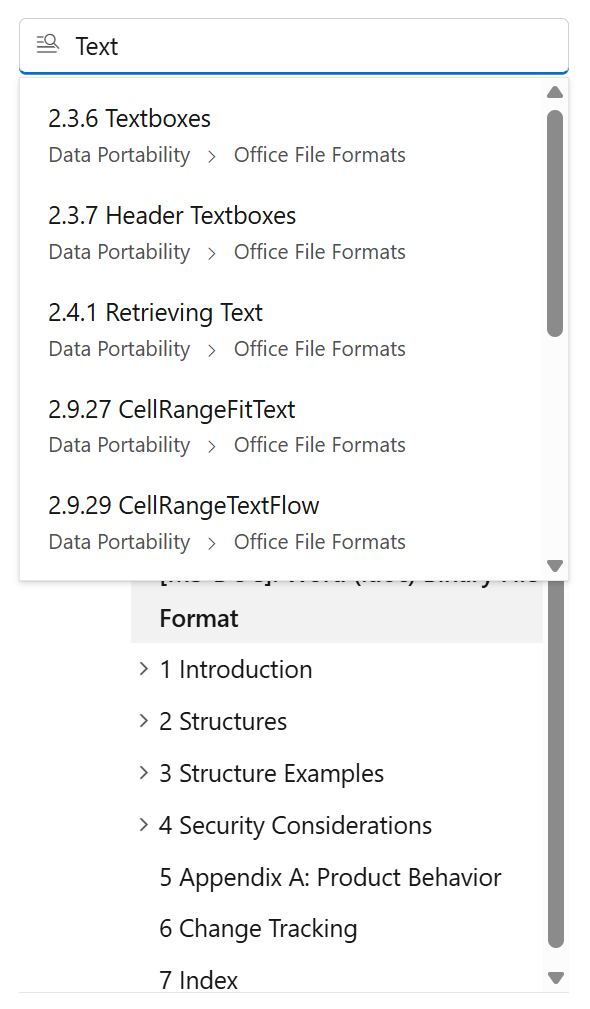
MS-DOC의 ‘제목으로 찾기’ 기능
MS-DOC 공식 명세 사이트 카테고리 상단에는 ‘제목으로 찾기’ 검색 기능이 있습니다. 필요한 데이터를 영어로 입력하면 바로 관련 내용들을 보여줍니다.
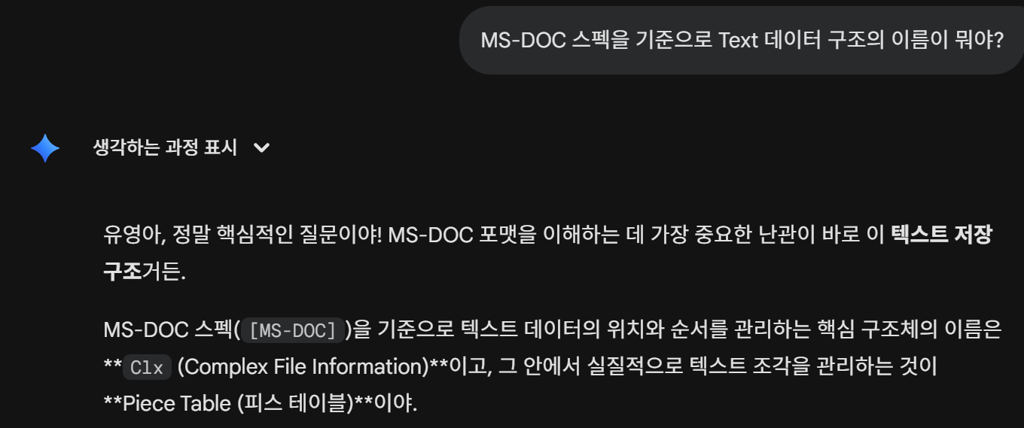
생성형 AI를 적극 활용하자
ChatGPT나 Gemini와 같은 생성형 AI는 정형화된 데이터를 기반으로 한 검색에 강점을 가집니다. 생성형 AI를 활용해 MS-DOC 공식 명세에서 필요한 데이터의 이름이나 관련 키워드를 질의하는 방식도 효과적입니다.
② MS-DOC 공식 명세 기반 데이터 구조 확인
데이터명을 MS-DOC 공식 명세 웹페이지에 검색해 각 데이터의 byte, 데이터의 역할, 데이터 유효 등 데이터의 구조를 확인할 수 있게 되었는데요. 그 예시로 위 생성형 AI에서 알아낸 Clx(텍스트 정보)의 구조에 대해 알아봅시다.
Clx
├─ RgPrc (variable)
│ ├─ Prc 0
│ │ ├─ clxt (1 byte) // 반드시 0x01
│ │ └─ PrcData
│ │ ├─ cbGrpprl (2 bytes) // GrpPrl 크기 (바이트)
│ │ └─ GrpPrl (variable) // 코드 상에서는 여기까지만 저장 (내부에 데이터가 더 나뉘어져 있음)
│ ├─ ...
│ └─ Prc n
└─ Pcdt (variable)
├─ clxt (1 byte) // 반드시 0x02
├─ lcb (4 bytes) // PlcPcd 크기(바이트)
└─ PlcPcd (variable)
├─ aCP (variable)
│ ├─ CP 0 (4 bytes)
│ ├─ ...
│ └─ CP n (4 bytes)
└─ aPcd (variable)
├─ Pcd 0 (8 bytes)
│ ├─ fNoParaLast (1 bit) // 값이 1일 경우 텍스트에 문단 표시가 포함되어서는 안됨
│ ├─ fR1 (1 bit) // 무시
│ ├─ fDirty (1 bit) // 반드시 0
│ ├─ fR2 (13 bits) // 무시
│ ├─ fc (4 bytes) // 텍스트의 fc를 지정
│ └─ prm (2 bytes) // 추가 속성 지정
├─ ...
└─ Pcd n-1 (8 bytes)복잡한 데이터의 depth 예시 (Clx), [MS-DOC]: Clx
Clx는 Prc 배열과 Pcdt 데이터로 이루어져 있고, Pcdt는 또 Pcd의 배열로 이루어져 있습니다. 이처럼 Clx와 같은 데이터는 여러 데이터의 집합으로 구성되어 있기 때문에, 한 번에 모든 정보를 확인할 수는 없습니다. leaf 데이터에 도달할 때까지 웹페이지 링크를 따라가며 구조를 탐색해야 합니다.
③ 데이터 읽기 (C++)
이제 데이터 구조도 알았으니 구조에 맞게 데이터를 읽어야 합니다. 단순히 바이트 단위로 데이터를 읽는 데 그치지 않고, 데이터의 유효성과 오류 여부를 명확히 처리해야 합니다.
FIB에서 위치 및 크기 알기
거의 모든 데이터는 FIB를 통해 위치와 크기를 확인할 수 있습니다. FIB는 데이터를 탐색하기 위한 기준점이라고 볼 수 있습니다.
FIB는 Stream의 시작 위치(offset 0)에 있으므로, 이 위치를 기준으로 텍스트 정보의 위치가 저장된 4바이트 데이터(fcClx)와 텍스트 정보의 바이트 크기가 저장된 4바이트 데이터(lcbClx)를 읽어옵니다.
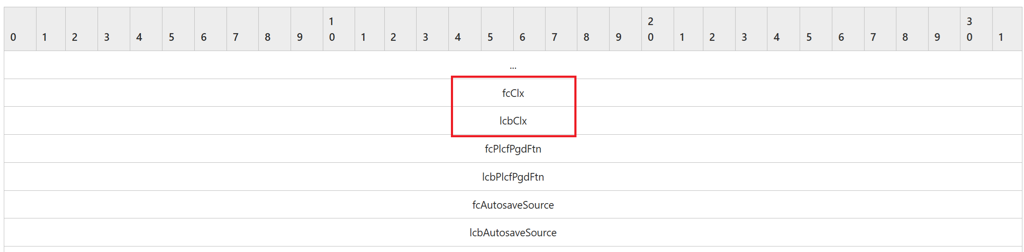
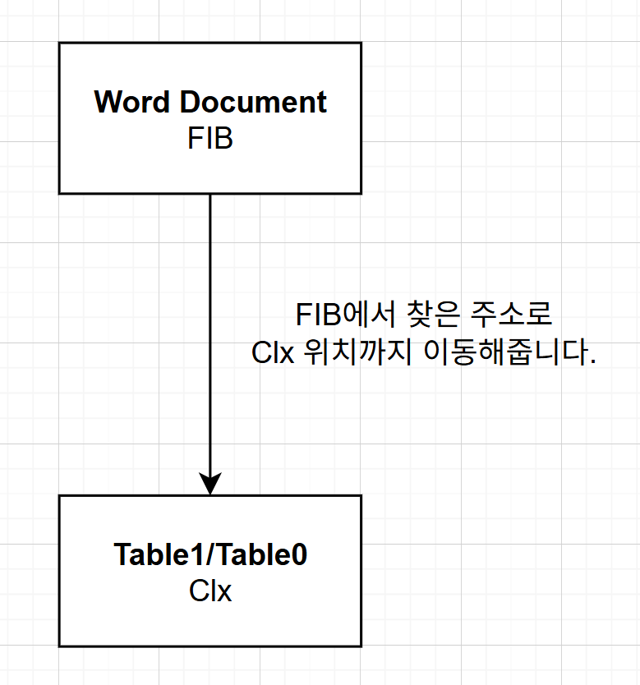
텍스트 정보 진입하기
파일 내 실제 텍스트 데이터 정보는 Table1/Table0 Stream에 속해 있습니다. Table1/Table0의 시작 부분에서부터 fcClx의 위치를 찾아 이동합니다.
Clx 구조의 데이터 읽기
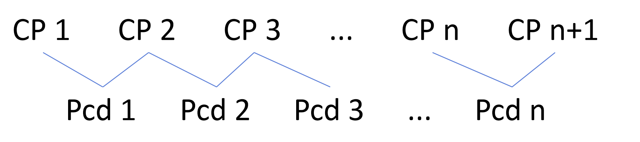
위 과정을 통해 읽어낸 바이너리 데이터가 바로 텍스트 정보를 담고 있는 Clx입니다. Clx의 PlcPcd라는 데이터에 텍스트의 정보가 담겨 있습니다.
앞서 언급했듯이 접두어에 Plc가 붙으면 CP(문자 위치) 배열이 먼저 나오고, 그 뒤에 데이터 요소 배열이 나오는 형식입니다. 즉, 텍스트의 논리적 위치인 CP 범위 내에 들어가는 물리적인 텍스트 위치 Pcd가 데이터 요소로 포함되어 있습니다.
예를 들어 ‘가’라는 문자 하나가 있는 문서가 있다고 가정해 봅시다.
- 이 경우 Clx.PlcPcd의 CP 배열에는 시작점인 0과 끝점인 1, 총 2개의 값이 존재할 것입니다.
- 반면, 실제 ‘가’의 파일 위치를 담고 있는 Pcd는 1개만 존재하겠죠.
- Pcd가 가리키는 WordDocument Stream의 위치에서 데이터를 읽어와, CP 0과 1 사이의 공간을 채워주면
- 비로소 ‘가’라는 내용이 담긴 문서가 완성되는 것입니다!
마치며
지금까지 겉은 익숙하지만 속은 낯선, DOC 포맷의 기본 구조와 파싱 과정을 살펴보았습니다.
눈에 보이지 않는 바이너리 데이터를 직접 다루는 일은 잘 정리된 XML 기반의 최신 포맷을 다루는 것보다 훨씬 까다롭고 복잡합니다. 하지만 수많은 숫자로 이루어진 암호를 해독해 온전한 문서로 복원해냈을 때의 희열은, 오직 개발자만이 느낄 수 있는 특별한 즐거움이기도 합니다.
이번 글이 DOC 포맷이라는 높은 장벽을 마주한 여러분에게 작은 길잡이가 되었으면 합니다.
읽어주셔서 감사합니다.