요약
이 글은 국제 표준 OOXML 기반의 DOCX 포맷 구조를 중심으로, 워드 문서가 다양한 편집 프로그램에서 동일하게 열리고 수정될 수 있는 원리를 설명합니다. DOCX 파일을 ZIP 기반의 XML 묶음으로 바라보고, document.xml·styles.xml·numbering.xml·media 등 핵심 구성 요소와 역할을 체계적으로 정리합니다. 특히 WordprocessingML의 설계 철학인 스트림 기반 문서 구조, p–r–t 텍스트 계층, Twip·EMU 단위 체계, Story·Section·Style·Drawing·Table·Numbering 구조를 예시 XML과 함께 상세히 다룹니다. 이를 통해 DOCX 문서의 내부 데이터를 해석하고, 문서 자동화·대량 처리·커스텀 문서 생성 등 실무 활용에 필요한 포맷 이해 방법을 소개합니다.
서론
Microsoft Word로 작성한 DOCX(.docx) 포맷의 문서를 한컴오피스 한워드에서 변환 없이 그대로 열고 수정할 수 있습니다. 또한 Google Docs, LibreOffice Writer 같은 다양한 문서 편집 프로그램에서도 동일한 문서를 다룰 수 있습니다. 어떻게 이런 일이 가능할까요?
그 비밀은 바로 DOCX 포맷의 구조가 국제 표준으로 정의되어 있고, 누구에게나 열려 있기 때문입니다.
표준화된 DOCX 포맷의 스펙 문서에 따라 DOCX 내부의 데이터를 해석하면, 우리가 화면에서 보는 완성된 문서의 형태로 만들 수 있습니다! 이렇게 MS 워드뿐만 아니라 다른 프로그램에서도 문서를 열고 수정할 수 있게 됩니다.
하지만 스펙 문서를 처음부터 확인한다면 방대한 양의 자료에 이해가 어려울 수 있는데요. 그 구조와 주요 구성 요소를 알아보기 쉽게 정리했습니다.
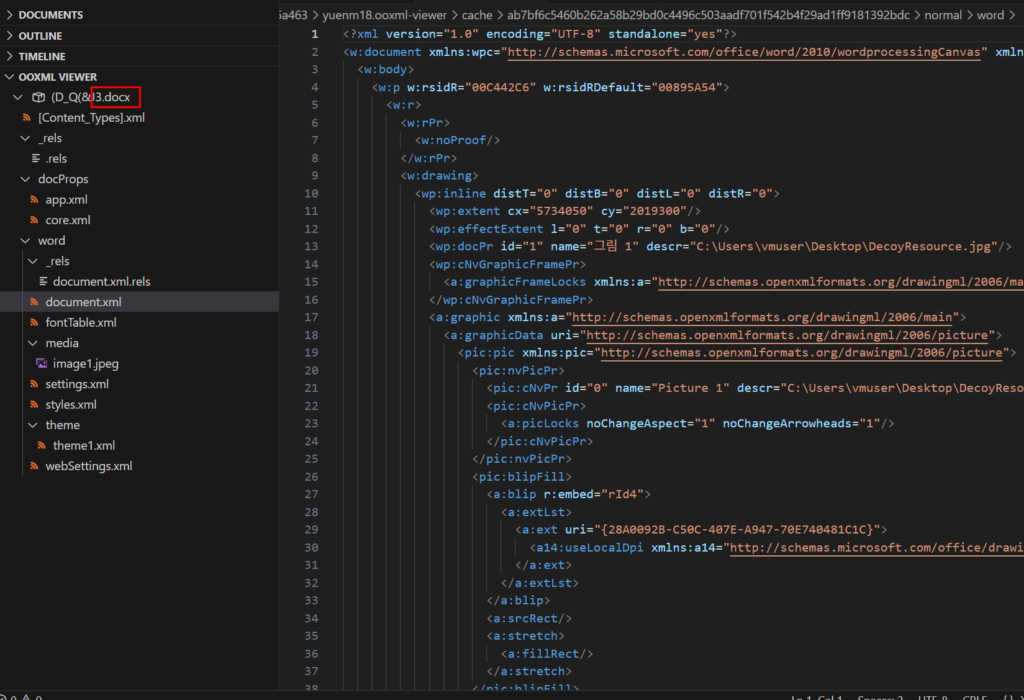
DOCX의 특징
DOCX 포맷 이전에 사용했던 doc 포맷의 경우 0과 1로만 이루어진 바이너리 파일로 이루어져, 사람이 해석하기 매우 어려웠습니다.  이뿐만 아니라 1 바이트만 깨져도 파일 전체를 읽을 수 없는 경우도 있었습니다. 이를 XML 파일 형식으로 구조화해 저장한 것이 DOCX 포맷입니다. XML 형식을 활용하여 사람이 더 읽기 쉬울 뿐만 아니라, 웹 서비스나 다른 프로그램에서도 쉽게 데이터를 추출할 수 있고 문서 손상에 대한 안정성도 올라갔습니다. Microsoft Office 2007 이후로 기본 포맷으로 사용되었으며, 국제 표준(ISO/IEC 29500)으로 채택된 OOXML(Office Open XML) 파일 형식을 따릅니다.
이뿐만 아니라 1 바이트만 깨져도 파일 전체를 읽을 수 없는 경우도 있었습니다. 이를 XML 파일 형식으로 구조화해 저장한 것이 DOCX 포맷입니다. XML 형식을 활용하여 사람이 더 읽기 쉬울 뿐만 아니라, 웹 서비스나 다른 프로그램에서도 쉽게 데이터를 추출할 수 있고 문서 손상에 대한 안정성도 올라갔습니다. Microsoft Office 2007 이후로 기본 포맷으로 사용되었으며, 국제 표준(ISO/IEC 29500)으로 채택된 OOXML(Office Open XML) 파일 형식을 따릅니다.
“사실은 압축 파일(ZIP)입니다”
.docx 파일의 확장자를 .zip으로 바꾸고 압축을 풀면, 그 안에 수많은 XML 파일과 이미지 폴더가 들어있는 것을 볼 수 있습니다. 문서의 본문, 이미지, 스타일 등을 각각 별도의 파일로 나눈 뒤, 하나로 압축(ZIP)한 것이 바로 OOXML 파일입니다.
DOCX 파일 구조
DOCX 파일의 압축을 해제하면, 아래와 같은 파일 구조를 확인하실 수 있습니다.
내 문서.docx/
├── [Content_Types].xml
├── _rels/
│ └── .rels
├── 📂 word/
│ ├── document.xml
│ ├── _rels/
│ │ └── document.xml.rels
│ ├── styles.xml
│ ├── settings.xml
│ ├── numbering.xml
│ ├── theme/
│ └── media/
├── docProps/
│ ├── app.xml
│ └── core.xml
1. 루트 디렉터리 📂
- [Content_Types].xml: 파일 내에 포함된 모든 콘텐츠 타입(이미지, XML, 텍스트 등)의 목록을 정의합니다.
- _rels/
- .rels:
word/document.xml이나docProps/core.xml같은 주요 파일들이 어디에 있는지 알려주는 파일입니다.
- .rels:
2. word/ (문서의 핵심 데이터)
- 📄 document.xml: 가장 중요한 파일입니다. 사용자가 입력한 실제 텍스트 내용과 기본적인 문단 구조가 XML 형태로 들어있습니다.
- _rels/
- document.xml.rels: 본문 내의 하이퍼링크, 이미지 경로, 각주 등이 실제 어떤 파일(media 폴더 내의 이미지 등)과 연결되는지 정의합니다.
- settings.xml: 문서의 동작 방식, 표시 옵션 등을 정의합니다.
- theme/: 문서 전체에 적용되는 표준 색상 팔레트, 제목 및 본문의 기본 폰트 세트, 도형에 적용되는 특수 효과 등이 XML 형태로 저장되어 있습니다.
- media/: 문서에 삽입된 이미지, 비디오 등 바이너리 파일들이 원본 형태로 저장되는 곳입니다.
3. docProps/ (문서 속성 정보)
- app.xml: 문서의 통계 정보(페이지 수, 단어 수, 줄 수, 응용 프로그램 버전 등)가 포함됩니다.
- core.xml: 문서의 메타데이터(제목, 작성자, 생성 날짜, 수정 날짜 등)가 포함됩니다.
WordprocessingML 이란?
OOXML 파일 형식은 워드 문서를 위한 WordprocessingML, 프레젠테이션 문서를 위한 PresentationML, 그리고 스프레드시트 문서를 위한 SpreadsheetML을 각각 정의하여 .docx, .pptx, .xlsx의 파일 구조를 구성합니다. WordprocessingML(이하 WordML)이란 워드 문서의 텍스트, 서식, 레이아웃 등을 구조화된 XML 형식으로 표현한 것입니다. 각 문서들이 공통으로 가지는 도형과 차트는 DrawingML, 수식은 Office MathML에서 정의합니다.
WordprocessingML의 특징
1. 페이지별 문서 정보를 저장하지 않는다.
많은 분들이 오해하실 수 있는 부분인데, .docx 파일 내부에는 “1 페이지가 어디서 끝나는지”에 대한 정보가 직접적으로 들어있지 않습니다. 이렇게 설계한 이유가 무엇일까요? 워드 문서는 종이에 고정된 인쇄물이 아니라, 내용이 흐르는 스트림(Stream)으로 설계되었습니다.
HTML을 생각하면 쉽습니다. 브라우저 창의 너비를 넓히면 글자가 옆으로 퍼지고, 좁히면 아래로 밀려나죠? WordprocessingML도 이와 비슷하게 내용의 순서와 관계만 정의할 뿐, 페이지가 어디서 끊길지는 렌더링 시점에 결정합니다.
💡 왜 이렇게 만드나요? 똑같은 문서라 할지라도 파일을 여는 환경에 따라 한 페이지에 들어가는 정보량이 달라질 수 있습니다. 사용자 PC에 설치된 폰트의 차이, OS의 텍스트 렌더링 방식(GDI, DirectWrite 등)에 따라 한 줄에 들어가는 글자 수가 달라질 수 있습니다.
하지만 문서의 흐름을 나누는 구조가 아예 없는 것은 아닙니다. 페이지 단위 대신 섹션(<w:sectPr>)이라는 단위를 씁니다. 섹션은 페이지의 가로/세로 방향, 여백 등의 규칙을 담고 있습니다.
2. 텍스트의 3단계 계층 구조 (p – r – t)
WordprocessingML에서 텍스트는 단순히 나열되지 않고, 3단계 계층 구조를 가집니다.
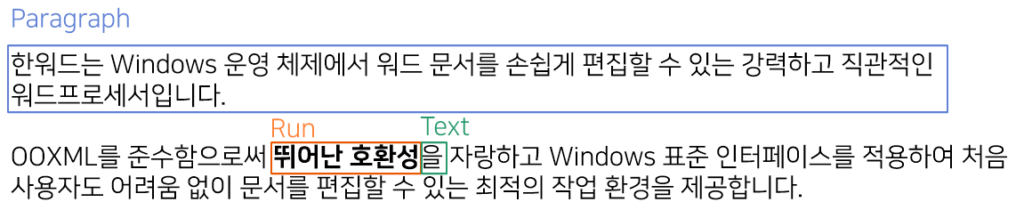
<w:p>(Paragraph): 문단 단위. 줄바꿈을 기준으로 나뉩니다.<w:r>(Run): 동일한 서식을 공유하는 텍스트 그룹. (예: “안녕하세요”에서 ‘안녕’과 ‘하세요’는 서로 다른 Run입니다.)<w:t>(Text): 실제 문자열 데이터가 들어가는 가장 하위 태그입니다.
이러한 구조를 통해 같은 서식이 적용된 글자들은 묶어서 관리할 수 있습니다.
3. Twip, EMU 단위 사용
WordML 내부의 단위는 흔히 사용되는 단위는 아닙니다. 여백 설정을 보면 1440이라는 숫자가 적혀 있고, 이미지 크기에는 무려 914400이라는 엄청난 숫자가 찍혀있는 것을 보실 수 있습니다. 이 거대한 숫자들은 오타가 아닌데요. 바로 정밀도와 호환성을 위해 설계된 OOXML만의 독특한 단위 체계 때문입니다.
💡 왜 픽셀(px)이나 센티미터(cm)를 안 쓸까요?
컴퓨터가 실수를 다루는 방식인 부동소수점(Floating Point) 연산에는 미세한 오차가 존재합니다. 문서 포맷에서
10.3333...같은 소수점을 사용하면, 문서를 열 때마다 혹은 뷰어마다 반올림 오차가 누적되어 레이아웃이 미세하게 틀어질 수 있습니다. 이를 막기 위해 WordML은 아주 작은 단위의 정수를 사용하여 오차를 원천 차단합니다.
아래는 WordML 개발자가 알아야 할 주요 단위 3가지를 정리했습니다.
① Twip (Twentieth of a Point)
- 용도: 레이아웃의 기본 단위 (여백, 위치, 너비 등)
- 정의: 이름 그대로 1포인트(pt)의 1/20입니다.
- 주로
w:w,w:left,w:right등의 레이아웃 속성 값의 단위로 사용됩니다. 때로는dxa라는 명칭으로 불리기도 합니다.
② Half-point (1/2 pt)
- 용도: 글자 크기 (
w:sz) - 정의: 1 unit이 0.5pt를 의미합니다.
- 예시: 워드 화면에서 12pt 폰트는 XML 내부에서
w:val="24"로 저장됩니다. - WordML 내부에서는 따로 단위 표시가 되어있지 않고, 스펙 문서를 통해 단위를 확인하실 수 있습니다. 일반적인 레이아웃에서는 twip 단위를 주로 사용하나, 글자 크기의 경우 half-point를 사용한다는 점을 알아두시면 좋습니다.
③ EMU (English Metric Unit)
- 용도: 이미지, 도형, 차트 (DrawingML 영역)
- 정의: 1 pt의 1/12700로 가장 정밀한 단위입니다.
- 인치(Inch)와 센티미터(cm)를 소수점 없이 변환 없이 표현할 수 있습니다.
| 단위 | 설명 | 변환 관계 |
|---|---|---|
| Point (pt) | 인쇄용 표준 단위, 1 inch = 72 pt | 1 pt = 1/72 inch |
| Pixel (px) | 화면 표시용 단위, 해상도에 따라 다름 | 일반적으로 96 dpi에서 1 px = 1/96 inch |
| Twip | Twentieth of a Point의 약자, 레이아웃의 기본 단위 | 1 pt = 20 twip → 1 inch = 1440 twip |
| Half-point | 폰트 크기(w:sz) | 1 unit = 1/2 Point |
| EMU | English Metric Unit. 이미지 크기, 도형 등에 사용 | 1 inch = 914400 EMU, 1 pt = 12700 EMU |
WordprocessingML의 주요 구성 요소
1. Story
WordML은 문서를 단일 텍스트 덩어리가 아닌, 성격이 다른 여러 개의 Story(이야기 흐름)로 나누어 관리합니다. 문서의 본문과 별개로 존재하는 머리말/꼬리말, 각주/미주 등은 각각 하나의 Story로 여겨집니다. 따라서 document.xml에 저장되는 것이 아닌 스토리별 파일에 저장됩니다.
- 머리말 → header1.xml에 저장
- 꼬리말 → footer1.xml에 저장
- 각주 → footnotes.xml에 저장
- 미주 → endnotes.xml에 저장
- 주석 → comments.xml에 저장
[주의] 글상자와 같은 경우 본문과 다른 스토리로 취급되지만 document.xml에서 데이터를 저장합니다.

2. Section
Section은 문서 내에서 페이지 레이아웃 설정이 달라지는 구획을 의미합니다. 하나의 문서는 여러 개의 섹션으로 구성될 수 있으며, 각 섹션마다 독립적인 페이지 설정을 가질 수 있습니다.
- 주요 속성: 페이지 방향, 여백, 크기 설정 / 다단 설정 / 머리말과 꼬리말 설정
- XML 표현:
<w:sectPr>요소로 표현되며, 각 섹션의 마지막 단락에 포함됩니다
<w:sectPr>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"/>
<w:cols w:space="720"/>
</w:sectPr>3. Column
Column은 신문이나 잡지처럼 페이지를 여러 세로 단으로 나누는 기능입니다. 섹션 속성의 일부로 정의되며, 각 섹션마다 다른 단 설정을 가질 수 있습니다.
- 단 설정 속성: 단 개수, 단 간격, 단 너비, 구분선 표시 여부
- XML 표현:
<w:cols>요소 내에 정의됩니다
<w:cols w:num="2" w:space="720">
<w:col w:w="4320"/>
<w:col w:w="4320"/>
</w:cols>
4. 텍스트 서식 (스타일)
WordML에서 텍스트 서식은 직접 서식(Direct Formatting)과 스타일 기반 서식으로 나뉩니다.
직접 서식
개별 텍스트에 직접 적용되는 서식으로 <w:rPr> (Run Properties) 요소에 정의됩니다.
<w:r>
<w:rPr>
<w:b/> <!-- 굵게 -->
<w:i/> <!-- 기울임 -->
<w:sz w:val="28"/> <!-- 글꼴 크기 14pt -->
<w:color w:val="9D5CBB"/> <!-- 보라색 -->
</w:rPr>
<w:t>한워드, 문서 작성도 매끄럽게</w:t>
</w:r>출력 결과

스타일 기반 서식
styles.xml에 정의된 재사용 가능한 서식 집합입니다. 스타일이 적용될 수 있는 요소(표, 문단 등)에 따라 구분할 수 있습니다.
- 문단 스타일: 제목, 본문 등 단락 전체에 적용
- 문자 스타일: 특정 텍스트 범위에만 적용
- 표 스타일: 표 전체의 서식 정의
- 다단계 목록 스타일: 번호 매기기 및 글머리 기호 스타일
- 기본 스타일: 문서 전체에 기본으로 적용되는 스타일
문단 스타일 예제
<w:pPr>
<w:pStyle w:val="a4"/
</w:pPr>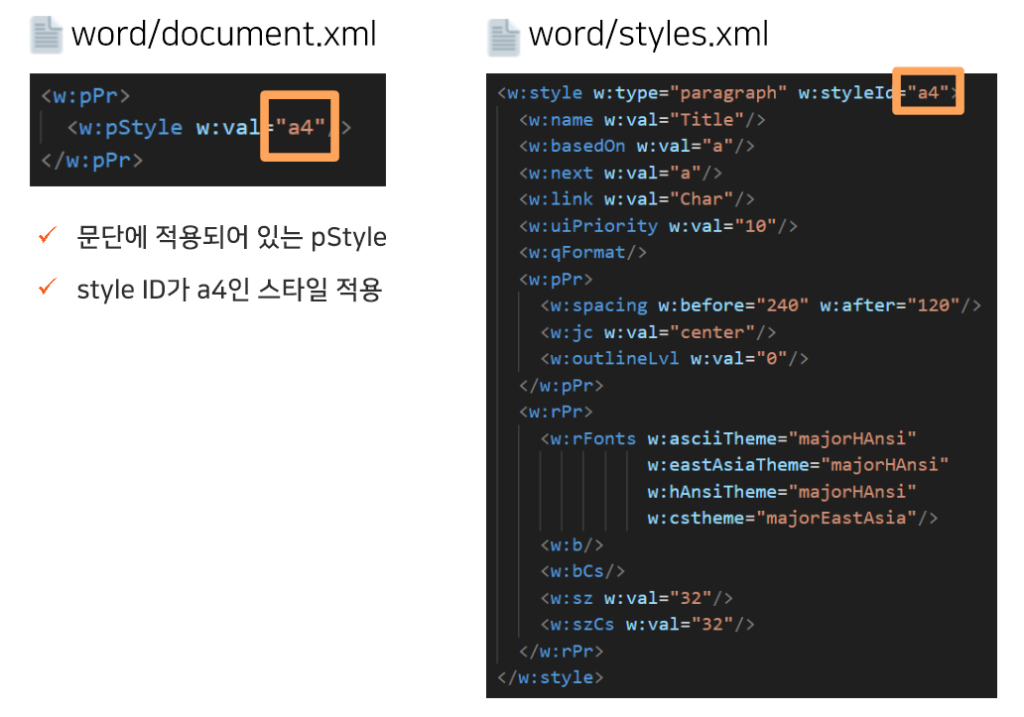
여러 가지 스타일이 겹친다면?
하나의 글자에는 여러 계층의 서식이 중첩될 수 있습니다. 만약 기본 스타일은 ‘검정’인데, 특정 문단은 ‘파랑’, 그 안의 특정 문자는 ‘빨강’으로 설정했다면 무엇이 보일까요? 정답은 빨강색입니다. 우선순위 원칙은 “좁고 구체적인 설정이 넓고 일반적인 설정을 이긴다.”라는 것입니다.
- 적용 순서: 기본 스타일(Doc Defaults) → 문단 스타일(pPr) → 문자 스타일(rPr) → 직접 서식(Direct Formatting) 순으로 덮어씁니다.
5. 그림 요소
그림과 도형은 Drawing 요소로 표현되며, document.xml에 참조 형태로 저장되고 실제 이미지 파일은 word/media/ 폴더에 별도로 보관됩니다.
주요 구성 요소
- 인라인 이미지:
<w:drawing>→<wp:inline>– 텍스트처럼 취급되어 텍스트 흐름을 따릅니다 - 플로팅 이미지:
<w:drawing>→<wp:anchor>– 텍스트와 독립적으로 배치됩니다
<w:drawing>
<wp:inline>
<a:graphic>
<a:graphicData uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic>
<pic:blipFill>
<a:blip r:embed="rId4"/> <!-- media/image1.png 참조 -->
</pic:blipFill>
</pic:pic>
</a:graphicData>
</a:graphic>
</wp:inline>
</w:drawing>- rId란? 실제 이미지 파일 경로를 연결해 주는 id입니다. document.xml.rels에서
rId4가 media/image1.png를 가리킵니다.
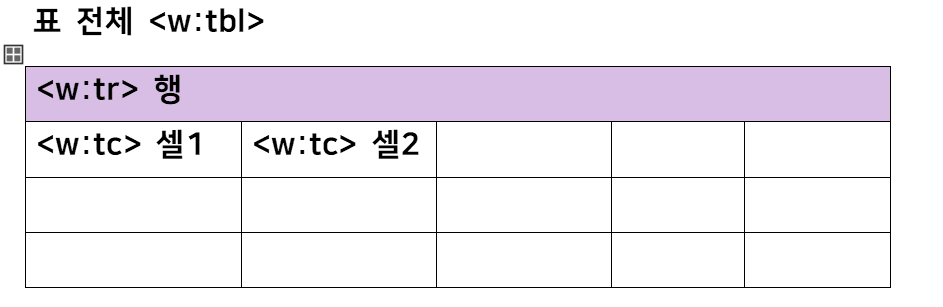
6. 표
표는 <w:tbl> 요소로 표현되며, 행 <w:tr>과 셀<w:tc>의 계층 구조로 구성됩니다.
표 구조
<w:tbl>
<w:tblPr> <!-- 표 속성 -->
<w:tblW w:w="5000" w:type="pct"/> <!-- 표 너비 -->
<w:tblBorders> <!-- 테두리 설정 -->
<w:top w:val="single" w:sz="4" w:color="000000"/>
</w:tblBorders>
</w:tblPr>
<w:tblGrid> <!-- 열 너비 정의 -->
<w:gridCol w:w="2500"/>
<w:gridCol w:w="2500"/>
</w:tblGrid>
<w:tr> <!-- 행 -->
<w:tc> <!-- 셀 -->
<w:tcPr>
<w:tcW w:w="2500" w:type="dxa"/>
</w:tcPr>
<w:p>
<w:r><w:t>셀 내용</w:t></w:r>
</w:p>
</w:tc>
</w:tr>
</w:tbl>주요 기능
- 셀 병합:
<w:vMerge>(세로),<w:hMerge>(가로) - 표 속성:
<w:tblPr>
7. 다단계 목록
다단계 목록은 번호 매기기나 글머리 기호를 사용한 계층적 목록 구조입니다. numbering.xml에 정의됩니다.
Numbering의 상속 구조
WordML의 다단계 목록은 효율적인 재사용을 위해 추상 번호 정의(Abstract Numbering Definition)와 번호 인스턴스(Numbering Instance)의 2단계 상속 구조를 사용합니다.
- Abstract Numbering (
<w:abstractNum>): 목록의 기본 템플릿으로, 각 레벨의 번호 형식, 들여 쓰기, 서식 등을 정의합니다. 여러 목록 인스턴스가 공유할 수 있습니다. - Numbering Instance (
<w:num>): 실제 문서에서 사용되는 목록으로, abstractNum을 참조하여 속성을 상속받습니다. 필요시 특정 레벨의 속성을 재정의(override)할 수 있습니다.
이러한 구조를 통해 동일한 스타일의 목록을 여러 곳에서 재사용하면서도, 각 인스턴스별로 시작 번호를 다르게 하거나 일부 속성만 변경할 수 있습니다.
Numbering 구조
<!-- numbering.xml -->
<w:numbering>
<w:abstractNum w:abstractNumId="0">
<w:lvl w:ilvl="0"> <!-- 레벨 0 -->
<w:start w:val="1"/>
<w:numFmt w:val="decimal"/>
<w:lvlText w:val="%1."/>
<w:lvlJc w:val="left"/>
</w:lvl>
<w:lvl w:ilvl="1"> <!-- 레벨 1 -->
<w:start w:val="1"/>
<w:numFmt w:val="lowerLetter"/>
<w:lvlText w:val="%2)"/>
</w:lvl>
</w:abstractNum>
<w:num w:numId="1">
<w:abstractNumId w:val="0"/>
</w:num>
</w:numbering>
<!-- document.xml -->
<w:p>
<w:pPr>
<w:numPr>
<w:ilvl w:val="0"/> <!-- 들여쓰기 레벨 -->
<w:numId w:val="1"/> <!-- 목록 ID -->
</w:numPr>
</w:pPr>
<w:r><w:t>첫 번째 항목</w:t></w:r>
</w:p>목록 스타일 옵션
- 번호 형식: 숫자, 알파벳, 로마 숫자, 한글, 한자 등
<w:numFmt w:val="decimal"/> - 시작 번호: 각 레벨의 시작 값 지정
<w:start w:val="1"/> - 들여 쓰기: 레벨별 왼쪽 여백 및 첫 줄 들여쓰기
<w:lvlJc w:val="left"/> - 글머리 기호: 특수 문자나 사용자 정의 기호 사용 가능
<w:lvlText w:val="○"/>

마치며
DOCX 포맷에서 데이터를 어떻게 저장하고 구조화하는지를 알아보았습니다.
이를 통해 왜 동일한 문서가 다양한 프로그램에서 일관되게 렌더링 될 수 있는지와 문서 데이터를 어떻게 효율적으로 저장하는지 이해하시는 데 도움이 되셨길 바랍니다.
이러한 내부 구조에 대한 이해는 단순히 문서 포맷을 아는 것을 넘어, 문서 자동화 도구 개발, 대량 문서 처리, 커스텀 문서 생성 시스템 구축 등 실무에서 강력한 무기가 될 수 있습니다. 감사합니다.