요약
이 글은 생성형 검색 시스템의 ‘어휘 불일치(Lexical Mismatch)’ 문제를 해결하기 위한 청크지식생성모델(Chunk Knowledge Generation Model) 의 구조와 성능을 소개합니다.
본 모델은 대형 언어 모델(LLM)을 사용하지 않고도 문서를 청크 단위로 나누어 키워드·제목·후보 질문을 동시에 생성함으로써, 검색 정확도와 효율성을 모두 향상시켰습니다.
T5 기반 멀티태스크 구조를 활용해 연산 비용을 줄이면서도, Qdrant 벡터 검색 환경에서 Top@1 정확도 84.26%, 평균 91.39%의 성능을 기록했습니다.
GPU 메모리 사용률은 10% 이하로 유지되어 RAG 환경에서도 실시간 응답이 가능한 경량형 생성형 검색 모델로 평가됩니다.
글에서는 모델의 설계 원리, 실험 구성, 성능 비교 결과, 그리고 향후 RAG 시스템 확장 방향을 함께 다룹니다.
1. 연구 배경
정보 검색(Information Retrieval) 분야에는 아주 오래되고 고질적인 문제가 하나 있습니다. 바로 ‘어휘 불일치(Lexical Mismatch)’ 문제입니다.
예를 들어 사용자가 “노트북 배터리 오래 쓰는 법”이라고 검색했지만, 실제로 완벽한 가이드를 담은 문서는 “랩탑 전원 관리 팁”이라는 제목을 가지고 있을 수 있습니다. 의미는 같지만, ‘노트북’과 ‘랩탑’, ‘배터리 오래 쓰는 법’과 ‘전원 관리 팁’처럼 사용된 단어가 달라 검색 결과에서 중요한 문서를 놓치게 되는 것이죠.

이 문제를 해결하기 위해 오랫동안 ‘질의 확장(Query Expansion)’ 기법이 사용되었습니다. 사용자의 쿼리에 유의어나 관련어를 추가해 검색 범위를 넓히는 방식입니다. 하지만 최근에는 이와 반대로, ‘문서 확장(Document Expansion)’ 접근법이 큰 주목을 받고 있습니다.
이때, 문서 확장의 대표적인 사례는 Doc2Query 기법입니다. T5와 같은 시퀀스-투-시퀀스(Seq2Seq) 모델을 사용해 문서 본문을 입력하면, 해당 문서가 답이 될 만한 예상 질문(쿼리)들을 여러 개 생성해내는 기술입니다.
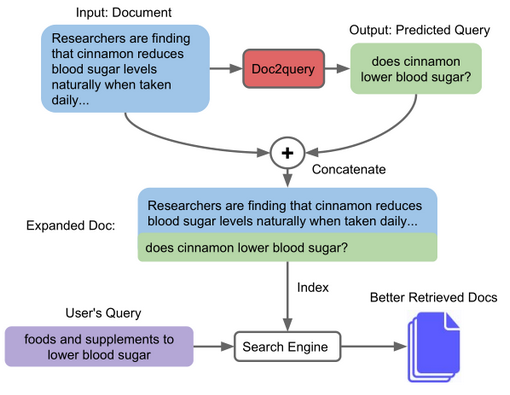
Doc2Query가 T5 모델을 기반으로 이 문제를 효과적으로 다루었다면, GPT-3, LLaMA 등 초거대 언어 모델(LLM)이 등장한 지금은 어떨까요? 자연스럽게 “더 강력한 LLM을 사용하면 더 품질 좋은 쿼리를 생성할 수 있지 않을까?”라는 흐름으로 이어졌습니다.
하지만 이 접근 방식은 생각보다 간단하지 않은 문제들을 안고 있습니다.
- 엄청난 비용과 시간: LLM은 T5와 비교할 수 없을 정도로 거대한 고비용 모델입니다. 수백만, 수천만 건의 문서 전체에 대해 LLM을 호출하여 확장 쿼리를 생성하는 것은 상상 이상의 막대한 연산 시간과 비용을 요구합니다.
- “과연 그만한 가치가 있는가?”: 더 큰 문제는, 이렇게 엄청난 자원을 투입하는 것이 기존의 T5 기반 Doc2Query 방식보다 압도적으로 우수한 성능을 보장하는지에 대해 아직 명확하게 검증되지 않았다는 점입니다. 잘못하면 비용은 비용대로 쓰면서 성능 향상은 미미할 수 있습니다.
이러한 문제를 해결하고 보다 효율적이고 구조적인 방식으로 검색 성능을 개선하기 위해, 저희는 ‘청크지식생성모델(Chunk Knowledge Generation Model)’을 개발했습니다.
2. 청크지식생성모델
이 모델의 핵심 아이디어는 문서를 통째로 다루는 대신, 검색에 적합하도록 잘게 나눈 ‘청크(Chunk)’ 단위로 분석하는 것입니다.
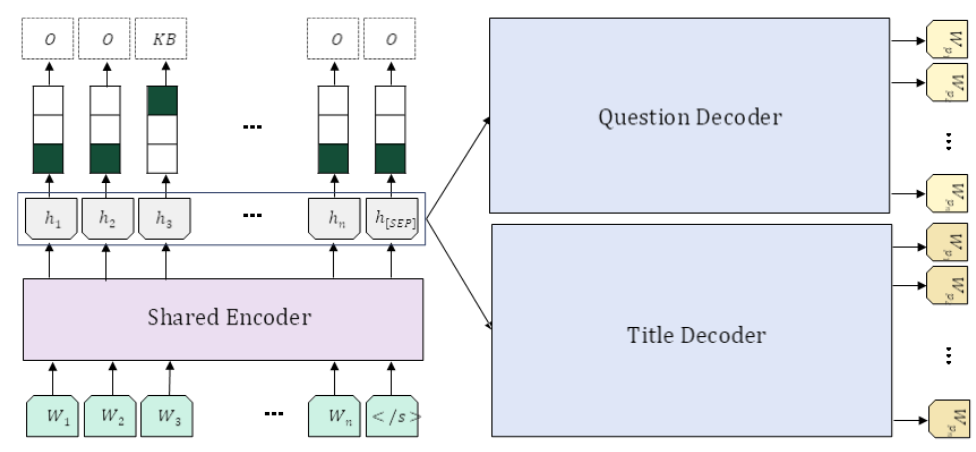
T5 모델(KETI-AIR/ke-t5-base)을 사용해, 하나의 청크에서 세 가지 다른 종류의 지식(메타데이터)을 동시에 생성하는 멀티태스크(Multi-task) 구조를 갖습니다.
이 모델의 가장 큰 구조적 특징은 ‘단일 인코딩, 병렬 생성’입니다.
입력된 청크는 T5 인코더를 단 한 번만 통과합니다. 이렇게 생성된 정보(인코더 출력 벡터)는 각기 다른 작업을 수행하는 3개의 모듈로 동시에 전달됩니다.
- 키워드 추출 (Keyword Extraction)
- 제목 생성 (Title Generation)
- 후보 질문 생성 (Candidate Question Generation)
이 구조 덕분에, 세 가지 작업을 별도로 수행할 때보다 연산 비용과 처리 시간을 획기적으로 줄일 수 있었습니다.
2.1 키워드 추출
- 역할: 청크 내의 핵심 단어를 정확히 식별해 추출합니다.
- 방식: 텍스트 생성이 아닌, 시퀀스 태깅(Sequence Tagging) 방식을 사용합니다. (NER 작업과 유사하게, 각 토큰이 키워드의 시작(KB)인지, 내부(KI)인지, 관계없는지(O)를 분류합니다.)
- 특징: T5의 인코더 출력만으로 바로 분류를 수행하여, 청크의 가장 중요한 중심 개념어들을 선별합니다.
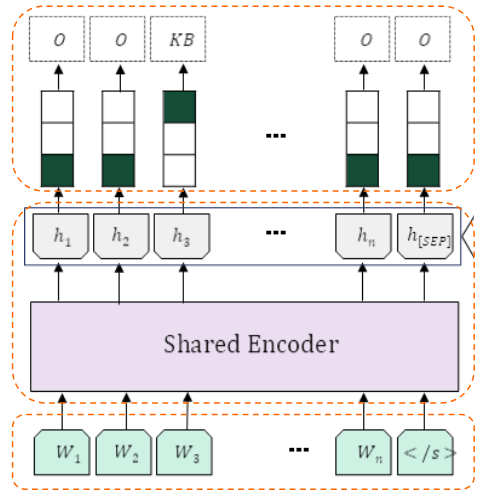
2.2 제목 및 후보 질문 생성
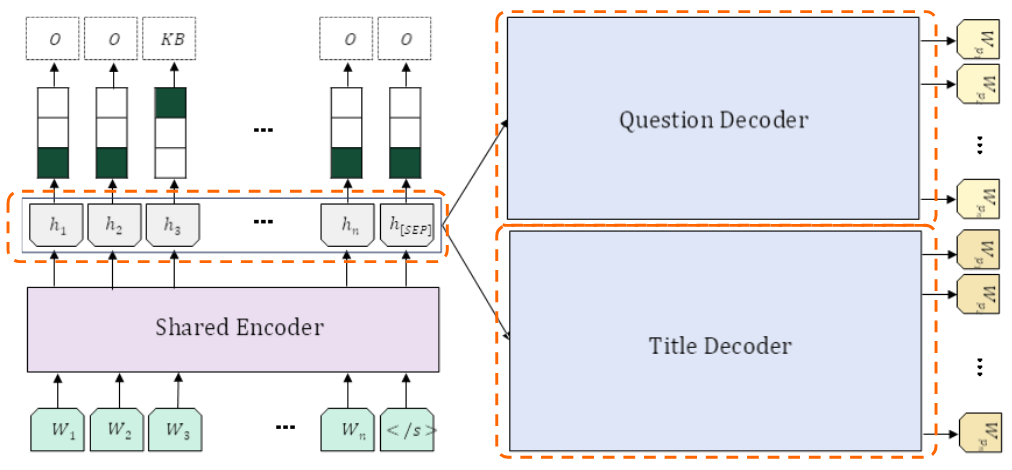
제목 생성 (Decoder 1)
- 역할: 해당 청크의 내용을 한 문장으로 요약하는 작업입니다.
- 방식: T5의 인코더 벡터를 받아, ‘제목 생성’에 특화된 독립적인 디코더가 한 문장의 제목을 생성합니다.
- 특징: 청크의 전체 주제를 대표하는 요약문을 만들어 검색 정확도를 높입니다.
후보 질문 생성 (Decoder 2)
- 역할: 기존 Doc2Query을 수행합니다. 이 청크가 정답이 될 수 있는 예상 질문들을 생성합니다.
- 방식: T5의 인코더 벡터를 받아, ‘질문 생성’에 특화된 또 다른 독립 디코더가 3개의 자연스러운 질문을 생성합니다.
- 특징: 어휘 불일치 문제를 해소하고 사용자의 다양한 검색 의도에 대응할 수 있게 합니다.
3. 실험
3.1 청크지식모델 학습 및 평가 데이터 셋
모델을 만들고 성능을 검증하기 위해, 저희는 두 종류의 목적에 맞는 데이터셋을 구축했습니다.
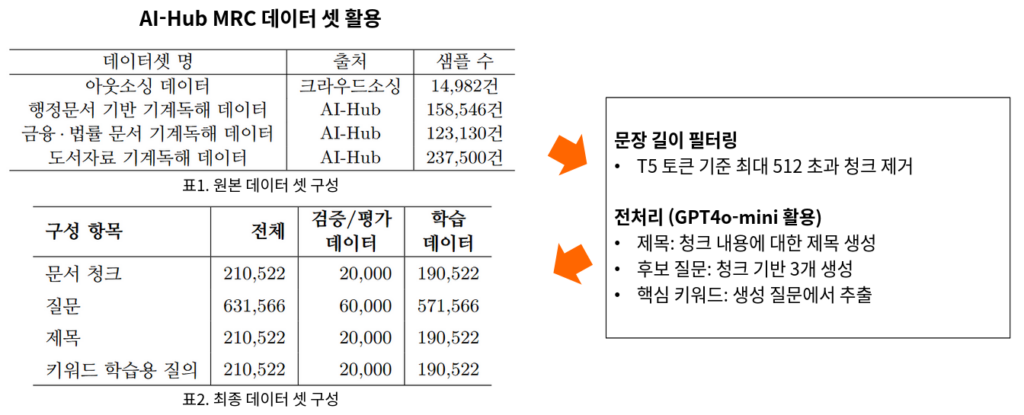
3.2 생성된 제목/질문 활용 시 검색 성능 향상 검증을 위한 검색 시스템 평가 데이터 셋
모델이 실제 검색 성능(Retrieval)을 얼마나 향상시키는지 평가하기 위한 별도의 테스트 데이터 셋을 구축했습니다.

이 데이터셋을 기반으로, “테스트용 질문이 주어졌을 때, 우리 모델이 정답 페이지(청크)를 얼마나 정확하게 찾아내는가”를 평가했습니다.
3.3 실험 환경 구축 및 평가 방법
실험 환경 구축
모델이 만든 ‘제목’과 ‘후보 질문’이 실제 검색 성능 향상에 얼마나 기여하는지를 검증하기 위해 여러 조합의 벡터 DB를 구축해 비교 실험을 진행했습니다.
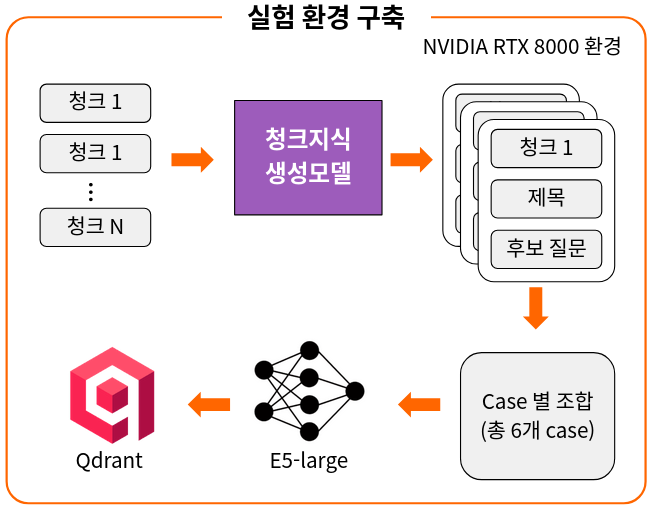
- 임베딩 모델은 검색에 특화된
E5-large모델을 사용했습니다. 원본 청크, 생성된 제목, 후보 질문들을<s> ... </s>(특수 토큰)으로 명확히 구분하여 E5 모델이 각 항목을 잘 이해할 수 있는 형태로 가공했습니다. - 벡터 DB는 고성능 벡터 검색을 지원하는
Qdrant를 사용했습니다. 코사인 유사도(Cosine Similarity)를 기준으로, 사용자의 질문 벡터와 가장 유사한 문서 청크를 찾아 반환하도록 설정했습니다. - 비교 실험은 검색 성능을 제대로 비교하기 위해, 총 7가지의 서로 다른 조합으로 벡터 DB를 구성했습니다.
| Case | 구성 방식 |
|---|---|
| 1 | <s> 문서 청크 </s> |
| 2 | <s> 제목 </s> |
| 3 | <s> 후보 질문 </s> |
| 4 | <s> 제목 </s> 후보 질문 </s> 문서 청크 </s> |
| 5 | <s> 후보 질문 </s> 제목 </s> 문서 청크 </s> |
| 6 | <s> 후보 질문 </s> 문서 청크 </s> |
| 7 | <s> 제목 </s> 문서 청크 </s> |
- 모든 실험은
NVIDIA RTX 8000 (48GB)GPU 환경에서 공정하게 수행되었습니다.
평가 방법
저희는 크게 두 가지 방식으로 성능을 측정했습니다.
(1) 정량 평가: BERTScore
- 단순히 단어가 몇 개 겹치는지(BLEU, ROUGE 등)를 넘어, 의미가 얼마나 유사한지를 측정하기 위해 BERTScore를 사용했습니다.
- 생성된 제목, 후보 질문, 키워드가 우리가 만든 정답 데이터와 문맥적으로 얼마나 가까운지를 정밀도(Precision), 재현율(Recall), F1 점수로 평가했습니다.
(2) 정성/자동 평가: GPT-4o
GPT-4o는 다음과 같은 4가지 핵심 기준을 ‘Pass’ / ‘Fail’로 냉정하게 판단했습니다.
- 검색 적절성: “검색 시스템이 찾아낸 청크가, 정말 사용자의 질문에 대한 정답을 포함하고 있는가?”
- 질문 생성 품질: “모델이 생성한 ‘후보 질문’이 원본 청크의 내용을 충실히 반영하는가?”
- 제목 생성 품질: “생성된 ‘제목’이 청크의 핵심 내용을 간결하게 잘 요약했는가?”
- 질문-키워드 정합성: “질문에서 추출한 ‘키워드’가 정말 그 질문의 핵심 의도를 담고 있는가?”
3.4 청크지식생성모델 실험 결과
평가 결과, 제안하는 ‘청크지식생성모델’은 제목(BERTScore 95.0%), 키워드(95.0%) 생성에서 가장 높은 정합성을 보였으며, 타 모델 대비 전반적인 성능과 균형 면에서 우수했습니다.

추가 실험 결과: 500건 데이터 셋에서 타 모델과 성능 비교

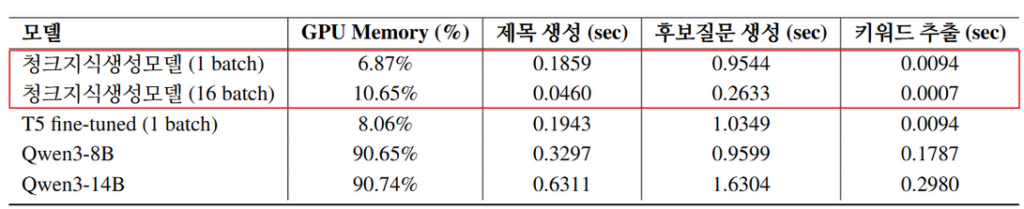
3.5 모델 별 평균 추론 시간 및 GPU 메모리 사용률 측정 결과
청크지식생성모델은 sLLM(Qwen)이 GPU 메모리의 90% 이상을 사용하는 것과 달리, 6~11%의 낮은 메모리 사용률로도 빠른 배치 추론이 가능했습니다.
이를 통해 압도적인 자원 효율성을 입증했습니다.
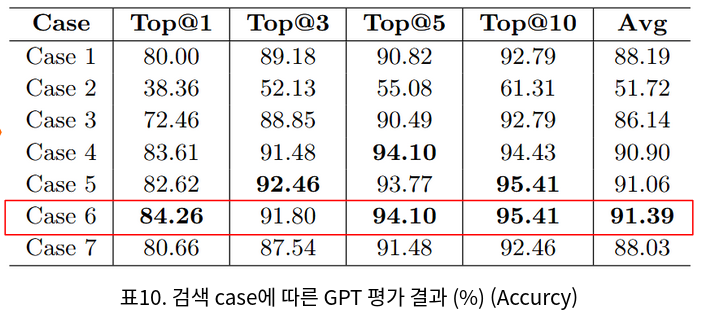
3.6 검색 시스템 적용 평가
검색 성능 평가 결과, 생성된 후보 질문과 제목을 원본 청크와 결합한 방식(Case6)이 Top@1 84.26%, 평균 91.39%로 가장 높은 성능을 보였습니다.
4. 결론 및 향후 방향
청크지식생성모델 성능
- 제목 생성 정확도는 92.0%, 후보 질문 생성은 90.0%, 키워드 추출은 93.6%로 SLM 기반 모델 (Qwen8B, 14B) 대비 안정적이고 우수한 결과를 보였습니다.
검색 성능
- 후보질문과 문서 청크를 결합한 Case 6과, 제목까지 함께 결합한 Case 5에서 그 다음으로 우수한 성능을 보여 다른 조합에 비해 검색 정확도가 크게 향상되었습니다.
- 이는 단순 요약보다 생성된 후보질문과 제목이 검색 과정에서 중요한 보조 수단임을 의미합니다.
효율성
- 청크지식생성 모델은 GPU 메모리 사용량이 6~11%로 매우 낮으며, 추론 속도가 밀리초(ms) 단위로 실시간 응답이 가능합니다. RAG 환경에서 속도와 효율성을 동시에 만족시키면서도 검색 품질을 향상시킬 수 있습니다.
향후 계획
- 청크지식생성 모델은 작은 규모에서도 후보 질문·제목 결합으로 검색 정확도와 효율성을 동시에 확보하여, 실시간 RAG 환경에 실용적입니다. 향후에는 키워드 추출과 메타데이터 필터링을 결합해 검색 정밀도를 강화할 예정입니다.
5. 연구 의의
이번 연구는 검색 정확도와 효율성을 동시에 높일 수 있는 현실적인 접근법을 제시했다는 점에서 의미가 있습니다.
대형 언어 모델을 사용하지 않고도 문서를 청크 단위로 나누어 핵심 정보를 생성·활용함으로써, 실제 서비스 환경에서도 충분히 적용 가능한 성능을 입증했습니다.
또한, 생성형 검색 시스템이 단순히 문서를 불러오는 수준을 넘어 사용자의 질문 의도를 더 정확히 이해하고 관련 정보를 찾아주는 방향으로 발전할 수 있음을 확인했습니다.
결국 이번 연구는 효율성과 성능을 함께 고려한 RAG 시스템의 새로운 설계 방향을 제시했다는 점에서 의의가 있습니다.
참고 자료
- 논문: Chunk Knowledge Generation Model for Enhanced Information Retrieval: A Multi-task Learning Approach (arXiv, 2025)
- 발표: 한글 및 한국어 정보처리학술대회, 2025년 10월 2일