요약
이 글은 HWPX 문서의 본문 데이터 추출 과정을 설명합니다. 문서 구조(본문–구역–문단)와 section.xml·header.xml 간 참조 방식을 소개하고, run 요소에서 텍스트·표·그림 등 콘텐츠를 어떻게 파싱하는지 다룹니다. Python 코드 예제를 통해 데이터 모델 설계, 본문 XML 파일 구조와 추출 데이터 모델, 데이터 추출 과정을 보여주며, 실제 샘플 문서로 서식 정보가 본문에 적용되는 방식을 확인합니다.
서론
지난 글에서는 공개된 HWPX 포맷 정보에 따라, Python 코드 예제를 통해 문서 정보, 서식 정보 등을 추출하는 방법을 알아보았습니다.
이번 글에서는 문서의 핵심 정보인 본문 데이터를 추출하고, 이 데이터가 서식 정보와 어떻게 연결되는지 알아보겠습니다. HWPX는 HWP와는 다르게 원하는 데이터만 바로 추출할 수 있다는 장점이 있기 때문에, 이러한 특징을 활용하여 본문 내용과 서식 정보를 중심으로 설명하겠습니다.
* 표준 문서는 e-나라표준인증에서 확인 가능합니다.
* 수록된 예제 코드는 Python 내장 라이브러리만을 사용하여 작성되었으며, 데이터 추출 과정을 설명하기 위해 간단하게 작성된 점 참고 부탁드립니다.
HWPX 본문 구조
우리는 “한/글 문서 파일 형식 : HWPX 포맷 구조 살펴보기”를 통해 Contents 디렉토리에는 문서에서 사용되는 서식 정보와 본문 내용이 포함되어 있고, Contents/section.xml 파일에는 구역별 본문 내용이 포함된다는 것을 알게 되었습니다. 이어서 본문 내용은 어떻게 구성되어 있을지 살펴보겠습니다.
본문의 논리적 구조 ([KS X 6101] [그림 66] 참조)
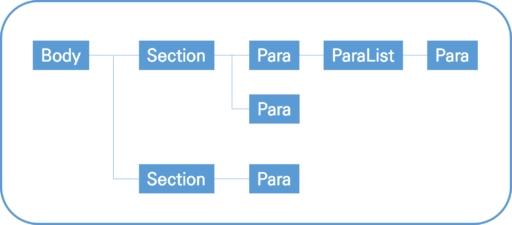
위 그림은 HWPX에서 본문을 이루는 논리적 구조를 도식화한 그림입니다. 표준 문서에서는 본문의 논리적 구조에 대해 다음과 같이 설명하고 있습니다.
[KS X 6101] 10.2 내용 요약
본문의 논리적인 구조는 ‘본문-구역-문단’이다. 실제 파일에 본문(Body)은 따로 존재하지 않고, 각 구역(Section)은 개별 파일로 저장된다. 본문을 이루는 구역은 반드시 한 개 이상 존재해야 하며, 한 구역은 반드시 한 개 이상의 문단(Para)을 가지고 있어야 한다. 표, 글상자와 같은 특수한 경우, 문단은 다시 문단 목록(ParaList)을 가지고 있을 수 있다. 문단에는 단순 텍스트뿐만 아니라 표, 그림, 그리기 객체 등 다양한 형태의 콘텐츠가 포함된다.
한/글의 “구역(Section)”은 한 문서 안에서 서로 다른 편집 용지, 바탕쪽, 각주/미주 모양, 쪽 테두리/배경, 개요 모양 등을 지정할 수 있도록 제공하는 구분 단위입니다.
구역이 구분되면 아래 이미지와 같이 동일한 문서 내에서도 페이지 방향을 다르게 하는 등 여러 요소를 분리하여 설정할 수 있습니다.
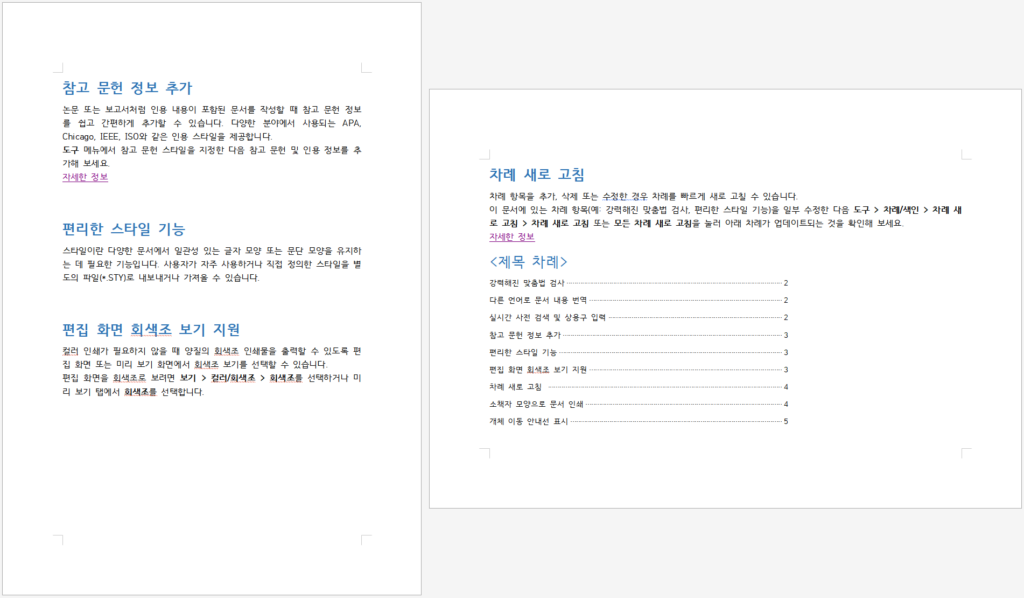
상태바를 통해 왼쪽 페이지(편집 용지 – 세로 방향)는 첫 번째 구역,

오른쪽 페이지(편집 용지 – 가로 방향)는 두 번째 구역에 속한다는 것을 확인할 수 있습니다.

이렇게 구분된 구역은 section0.xml, section1.xml, … 과 같은 형태로, 각 구역이 별개의 XML 파일로 HWPX 문서에 저장됩니다. 구역의 개수는 header.xml에 포함되어 있습니다.
데이터 모델 설계 방법
지난 시간에 다룬 header.xml, settings.xml, content.hpf 파일들은 대부분의 문서에서 구조가 거의 동일합니다. 하지만 section.xml 파일은 문서의 본문 내용이 포함되기 때문에 작성된 문서 내용에 따라 내부 구성 요소가 크게 달라집니다.
우리는 특정 문서가 아닌 다양한 HWPX 문서에서 데이터를 추출하려는 것이므로, 이렇게 내용에 따라 구조가 변하는 상황에 대응할 수 있는 유연한 데이터 모델을 설계해야 합니다. 이를 위해서는 XML 요소 간의 포함 관계와 구조를 파악하는 것이 중요합니다. 표준 문서에 포함된 스키마 정보는 이러한 요소 간의 관계를 정의하고 있기 때문에, 이를 바탕으로 각 요소 간의 관계를 정리하고 모델을 구성해보겠습니다.
이전 글에서는 완성된 데이터 모델을 먼저 제시하고 설명하는 방식으로 진행했습니다. 이번에는 1. 부속서 스키마(XSD)와 2. 표준 문서 내용을 확인하고, 3. 데이터 모델을 작성하는 순서로 진행하여, 데이터 간 연결을 중점적으로 보려고 합니다.
본격적으로 본문 데이터를 추출하기 전에, 이전 글에서 추출한 데이터 중 비교적 간단한 요소인 beginNum으로 데이터 추출 과정을 복습하면서, XML 스키마(XSD; XML Schema Definition)와 실제 XML 문서, 표준 문서를 어떻게 연계하여 데이터 모델을 만들어야 할지 위의 순서대로 알아보겠습니다.
1. 부속서 스키마(XSD) 확인
표준 문서의 부속서에는 HWPX 문서의 XML 스키마가 포함되어 있습니다.

위 목록은 표준 문서에 포함되어 있는 부속서 중 XML 스키마 목록입니다. 이 중에서 header.xml을 구성하는 요소들이 포함되어 있는 부속서 C의 내용을 확인하겠습니다.
[KS X 6101] 부속서 C. Header XML 스키마
<xs:element name="head" type="HWPMLHeadType">...</xs:element>
<xs:complexType name="HWPMLHeadType">
<xs:sequence>
<xs:element name="beginNum">
<xs:complexType>
<xs:attribute name="page" type="xs:positiveInteger" use="required"></xs:attribute>
<xs:attribute name="footnote" type="xs:positiveInteger" use="required"></xs:attribute>
<xs:attribute name="endnote" type="xs:positiveInteger" use="required"></xs:attribute>
<xs:attribute name="pic" type="xs:positiveInteger" use="required"></xs:attribute>
<xs:attribute name="tbl" type="xs:positiveInteger" use="required"></xs:attribute>
<xs:attribute name="equation" type="xs:positiveInteger" use="required"></xs:attribute>
</xs:complexType>
</xs:element>
<!--...생략...-->
</xs:sequence>
<xs:attribute name="version" type="xs:string" use="required"/>
<xs:attribute name="secCnt" type="xs:nonNegativeInteger" use="required"/>
</xs:complexType>스키마를 통해 head 요소에는 하위 요소인 beginNum이 존재하고, beginNum에는 6개의 속성이 포함된다는 것을 확인할 수 있습니다. 각 요소나 속성에 주석이 달려있지 않을 수 있기 때문에, 표준 문서 내용과 함께 보는 것이 좋습니다.
2. 표준 문서 내용 확인
[KS X 6101] [표 11] head 요소 속성
| head 요소 속성 이름 | 설명 |
|---|---|
| version | OWPML Header XML의 버전 |
| secCnt | 문서 내의 구역 개수 |
[KS X 6101] [표 12] head 하위 요소
| head 하위 요소 이름 | 설명 |
|---|---|
| beginNum | 문서 내에서 각종 객체들의 시작 번호 정보를 가지고 있는 요소 |
| refList | 본문에서 사용될 각종 데이터에 대한 맵핑 정보를 가지고 있는 요소 |
| forbiddenWordList | 금칙 문자 목록을 가지고 있는 요소 |
| compatibleDocument | 문서 호환성 설정 |
| trackchangeConfig | 변경 추적 정보와 암호 정보를 가지고 있는 요소 |
| docOption | 연결 문서 정보와 저작권 관련 정보를 가지고 있는 요소 |
| metaTag | 메타태그 정보를 가지고 있는 요소 |
[KS X 6101] [표 13] beginNum 요소 속성
| beginNum 요소 속성 이름 | 설명 |
|---|---|
| page | 페이지 시작 번호 |
| footnote | 각주 시작 번호 |
| endnote | 미주 시작 번호 |
| pic | 그림 시작 번호 |
| tbl | 표 시작 번호 |
| equation | 수식 시작 번호 |
표준 문서에 정리된 내용을 보고, head 요소와 하위 요소들이 각각 어떤 정보를 담고 있는지, beginNum 요소의 속성은 무엇을 의미하는지 알 수 있습니다.
3. 데이터 모델 작성
이전 글에서는 편의에 따라 Document라는 모델 하위에 beginNum 요소의 속성도 포함시켰지만,
# 문서의 메타 정보 및 설정값을 담을 모델
@dataclass
class Document:
sectionCount: int = 0
pageStartNum: int = 0
footnoteStartNum: int = 0
endnoteStartNum: int = 0
pictureStartNum: int = 0
tableStartNum: int = 0
equationStartNum: int = 0
caretPos: CaretPosition = field(default_factory=lambda: CaretPosition(0, 0, 0))
binaryDataCount: int = 0
hangulFontDataCount: int = 0
englishFontDataCount: int = 0 지금까지 확인한 스키마 내용과 동일하게 데이터 모델을 구성해보면, BeginNumber 데이터 클래스를 Document 클래스가 가지고 있는 형태로 설계할 수도 있습니다.
@dataclass
class BeginNumber:
pageStartNum: int = 0
footnoteStartNum: int = 0
endnoteStartNum: int = 0
pictureStartNum: int = 0
tableStartNum: int = 0
equationStartNum: int = 0본문 XML 파일 구조와 추출 데이터 모델
본문 내용을 파싱하기 위해, 이전 챕터에서 확인한 순서대로 본문의 데이터 모델을 설계해보겠습니다.
1. 부속서 스키마(XSD) 확인
부속서 내용 중 본문에 해당하는 “부속서 D. Body XML 스키마”를 확인해보면,
[KS X 6101] 부속서 D. Body XML 스키마
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:hp="http://www.owpml.org/owpml/2021/paragraph" xmlns:hs="http://www.owpml.org/owpml/2021/section" targetNamespace="http://www.owpml.org/owpml/2021/section" elementFormDefault="qualified">
<xs:import namespace="http://www.owpml.org/owpml/2021/paragraph" schemaLocation="HWPMLParaListSchema.xsd"/>
<xs:element name="sec" type="hp:SectionType">
<xs:annotation>
<xs:documentation>Root Element</xs:documentation>
</xs:annotation>
</xs:element>
</xs:schema>전체 내용이 매우 짧고, 실제 데이터는 sec 요소의 type으로 정의된 쪽에 있다는 것을 알 수 있습니다.
type="hp:SectionType"에서 prefix hp에 해당하는 문서를 찾아야 하기 때문에 xs:schema의 속성을 다시 보겠습니다.
<xs:schema
xmlns:hp="http://www.owpml.org/owpml/2021/paragraph"
targetNamespace="http://www.owpml.org/owpml/2024/section" ...>xs:schema 속성을 확인해보면 hp는 "http://www.owpml.org/owpml/2021/paragraph" 의 prefix 이므로, targetNamespace가 "http://www.owpml.org/owpml/2021/paragraph"인 XML 스키마를 확인해야 합니다.
“부속서 E. ParaList XML 스키마”에서 SectionType에 해당하는 요소 정의를 확인할 수 있습니다.
[KS X 6101] 부속서 E. ParaList XML 스키마
<xs:schema targetNamespace="http://www.owpml.org/owpml/2021/paragraph"><!--...생략...--></xs:schema><xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:hp="http://www.owpml.org/owpml/2021/paragraph" xmlns:hc="http://www.owpml.org/owpml/2021/core" targetNamespace="http://www.owpml.org/owpml/2021/paragraph" elementFormDefault="qualified">
<xs:complexType name="SectionType">
<xs:sequence>
<xs:element name="p" type="hp:PType" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<!--...생략...-->
</xs:schema>SectionType은 p 하위 요소를 가지고 있습니다. 문서를 이루는 문단 개수만큼 p 요소가 존재하며, p 요소는 본문 내용을 이루는 기본 단위입니다.
p 요소의 내용은 PType에 정의되어 있습니다. p 요소 하위의 run 요소는 글자 속성 컨테이너를 의미합니다. 하나 혹은 여러 개의 글자가 가지고 있는 동일한 속성을 나타내는 구분 단위이며, 문서의 모든 콘텐츠와 제어 관련 요소들은 run 요소로 묶여서 구성됩니다.
run 요소의 실제 스키마 정의에는 더 많은 하위 요소가 있지만, 속성들과 일부 요소만 간추렸습니다.
<xs:complexType name="PType">
<xs:sequence minOccurs="1" maxOccurs="1">
<xs:element name="run" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="secPr" type="hp:SectionDefinitionType" minOccurs="0" maxOccurs="1">
<xs:annotation>
<xs:documentation>PType 하위에 하나만 존재해야 함</xs:documentation>
</xs:annotation>
</xs:element>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="ctrl">
<xs:complexType>
<xs:choice minOccurs="1" maxOccurs="1">
<xs:element name="colPr" type="hp:ColumnDefType" maxOccurs="1">
<xs:annotation>
<xs:documentation>PType 하위에 하나만 존재해야 함</xs:documentation>
</xs:annotation>
</xs:element>
<!--...생략...-->
</xs:choice>
</xs:complexType>
</xs:element>
<xs:element name="t"></xs:element>
<xs:element name="tbl" type="hp:TableType"/>
<xs:element name="pic" type="hp:PictureType"/>
<!--...생략...-->
</xs:choice>
</xs:sequence>
<xs:attribute name="charPrIDRef" type="xs:nonNegativeInteger"/>
<xs:attribute name="charTcId" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="id" type="xs:nonNegativeInteger" use="required"/>
<xs:attribute name="paraPrIDRef" type="xs:nonNegativeInteger"/>
<xs:attribute name="styleIDRef" type="xs:nonNegativeInteger"/>
<xs:attribute name="pageBreak" type="xs:boolean" default="false"/>
<xs:attribute name="columnBreak" type="xs:boolean" default="false"/>
<xs:attribute name="merged" type="xs:boolean" default="false"/>
<xs:attribute name="paraTcId" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>run 요소 하위에는 컨트롤과 텍스트가 포함되는데, 여기서 “컨트롤(Ctrl)”이란 [표], [그림], [도형] 등 개체들과 여러가지 설정 정보를 가지는 제어 관련 요소들을 총칭하는 표현입니다.
2. 표준 문서 내용 확인
다음으로는 위 스키마의 내용을 표준 문서에서 확인하고 각 속성과 하위 요소의 의미를 확인합니다. 이번 글에서는 본문 내용과 서식 정보를 중점적으로 다룰 예정이므로 필요한 정보만 살펴보겠습니다.
[KS X 6101] [표 96] p 요소 속성
| p 요소 속성 이름 | 설명 |
|---|---|
| id | 문단을 식별하기 위한 아이디 |
| paraPrIDRef | 문단 모양 아이디 참조값 |
| styleIDRef | 문단 스타일 아이디 참조값 |
| … | … |
[KS X 6101] [표 97] p 하위 요소
| p 하위 요소 이름 | 설명 |
|---|---|
| run | 구역 속성 정보 |
[KS X 6101] [표 98] run 요소 속성
| run 속성 이름 | 설명 |
|---|---|
| charPrIDRef | 글자 모양 설정 아이디 참조값 |
| … | … |
[KS X 6101] [표 99] run 하위 요소
| run 하위 요소 이름 | 설명 |
|---|---|
| secPr | 구역 설정 정보 |
| ctrl | 문단 제어 정보 |
| t | 텍스트 문자열 |
| tbl | 표 |
| pic | 그림 |
| … | … |
3. 데이터 모델 작성
확인한 내용을 참고하여 데이터 모델을 작성하겠습니다.
작은 단위의 데이터부터 생각해보면 [텍스트], [표] 등 실제 내용과 모양 정보를 담을 수 있는 데이터 모델이 필요합니다. 여기서는 Ctrl을 텍스트뿐만 아니라 표, 그림 등 문단을 구성하는 모든 요소들을 포괄하는 상위 개념으로 두었습니다. 이후 추가되는 요소는 Ctrl을 상속 받아서 구현하면 됩니다.
# run 및 개체, 제어 요소
@dataclass
class Ctrl:
ctrlID: int = 0
charShapeID : int = 0
# ... 생략 ...
# t 요소
@dataclass
class Text(Ctrl):
text: str = ""
Document는 여러 개의 Section으로 구성되어 있고, Section은 다시 여러 개의 Para로 나뉘기 때문에 데이터 모델도 동일한 구조로 정의합니다.
# p 요소
@dataclass
class Para:
paraInstanceID: int = 0
paraShapeID: int = 0
paraStyleID: int = 0
# ... 생략 ...
ctrlList: list[Ctrl] = field(default_factory=list)
# sec 요소
@dataclass
class Section:
paraList: list[Para] = field(default_factory=list)
# 모양 정보
@dataclass
class ShapeManager:
fontList: dict[str,list[FontData]] = field(default_factory=dict)
charshapeList: list[CharShape] = field(default_factory=list)
parashapeList: list[ParaShape] = field(default_factory=list)
@dataclass
class Document:
shapeManager: ShapeManager = field(default_factory=ShapeManager)
documentInfo: DocumentInfo = field(default_factory=DocumentInfo)
sectionList: list[Section] = field(default_factory=list)Document(문서)
가장 상위에 있는 최상위 객체로 파싱된 HWP 파일의 모든 정보를 가지고 있습니다.SectionList(구역 리스트)Document바로 아래에 위치하며 문서의 구역(Section)들을 가지고 있는 리스트입니다.ParaList(문단 리스트)
각Section은 여러 개의 문단으로 구성됩니다.ParaList는 한 구역 안에 포함된 모든 문단의 리스트를 가지고 있습니다.CtrlList(컨트롤 리스트)
문단의 실제 내용을 담고 있는 데이터 리스트입니다. 여기서 컨트롤은 눈에 보이는 텍스트뿐만 아니라 표, 그림 등 문단을 구성하는 모든 요소들을 포괄하는 개념입니다.ShapeManager(모양 정보 관리자)
문서 전체의 스타일 정보를 총괄하는 객체입니다.ShapeManager는 문서에 사용된 모든 글꼴, 글자 모양, 문단 모양 등을 리스트로 관리합니다. 각 문단이나 텍스트는 고유한 모양 정보를 직접 가지고 있는 것이 아니라,ShapeManager에 등록된 모양 정보의 ID를 참조하는 방식으로 동작합니다.
(* 이 Document의 구조는 “한/글 문서 파일 형식: Python을 통한 HWP 포맷 파싱하기 (2)”에서 확인할 수 있는 HWP 파서의 구조와 동일합니다. 다만, 각 파일 포맷에 따라 내부에 포함되는 데이터에는 차이가 있습니다.)
이렇게 구성된 Document를 HWPXReader가 처리할 수 있게 정의해둡니다.
class HWPXReader:
def __init__(self, file_path: str):
self.hwpx_file = zipfile.ZipFile(file_path, 'r')
self.doc = Document()데이터 추출
예제 코드를 통해 문서를 파싱하여 데이터를 추출하는 과정을 단계별로 살펴보겠습니다.
1. Contents/section.xml 파일 추출
먼저, section.xml 파일의 본문 내용과 서식 정보입니다.
1.1 본문 내용 추출
header.xml의 최상위 요소인 head 요소에는 문서 내의 구역이 몇 개인지 확인할 수 있는 secCnt 속성이 있습니다. 정상적인 문서에서는 이 개수만큼 section.xml 파일이 존재합니다. section0.xml부터 시작해서 secCnt의 개수만큼 파일을 읽어오고, sec 요소 하위에 존재할 p 요소를 읽도록 합니다.
# Contents/section.xml 파일 읽기
def _read_sections(self) -> bool:
for n in range(self.doc.documentInfo.sectionCount):
# XML_FILENAME_SECTION : 'Contents/section%d.xml'
section_root, ns = self._read_xml_file(XML_FILENAME_SECTION % n)
# 본문 내용
section = Section()
section.paraList = self._read_para_list(section_root, ns)
self.doc.sectionList.append(section)
return Truep 요소를 하나씩 읽어서 list에 담습니다.
def _read_para_list(self, paralist_root:ET.Element, ns:dict) -> list[Para]:
para_list = []
for para_root in paralist_root.findall('hp:p', ns):
para = self._read_para(para_root, ns)
if para:
para_list.append(para)
return para_listp 요소의 속성과 하위 요소들은 아래 함수에서 처리합니다.
def _read_para(self, para_root:ET.Element, ns:dict) -> Para:
para = Para()
# p 요소 속성
para.paraInstanceID = int(para_root.get('id'))
para.paraShapeID = int(para_root.get('paraPrIDRef'))
# ...생략...
# p 하위 요소
for run in para_root.findall('hp:run', ns):
self._create_ctrl(para, run, ns)
return para이제 핵심 내용이 담겨 있는 run 요소를 보겠습니다.
스키마와 표준 문서를 통해 확인했듯이 run 요소 하위에는 다양한 개체가 존재합니다. 지금까지는 xml.etree.ElementTree 라이브러리를 사용하면서 요소 이름을 명시적으로 전달하여 find, findall과 같은 함수를 통해 하위 요소를 꺼내왔지만, run 요소는 각 하위 요소에 맞는 파싱 함수를 호출할 수 있도록 연결해주는 과정이 필요합니다.
요소에 따라 함수를 연결하여 factory를 정의하고,
ctrl_factory = {
'secPr': _read_secdef_ctrl,
'ctrl': _read_ctrl_ctrl,
'colPr': _read_coldef_ctrl,
't': _read_text,
'tbl': _read_table,
}run 요소에서 하위 요소를 모두 읽어서, 처리된 Ctrl을 Para의 ctrlList에 append하여 list를 구성합니다.
# 각 요소에 해당하는 클래스 연결
def _get_read_func(self, tag:str):
local_name = get_localname(tag)
if not local_name:
return None
return self.ctrl_factory.get(local_name)
def _create_ctrl(self, para:Para, run_root:ET.Element, ns:dict) -> bool:
# run 요소 속성
charShapeID = run_root.get('charPrIDRef')
# ...생략...
# run 하위 요소 모두 읽기
items = run_root.findall('*', ns)
for item in items:
ctrl_type_parser = self._get_read_func(item.tag)
if ctrl_type_parser:
ctrl = ctrl_type_parser(self, item, ns)
if ctrl:
ctrl.charShapeID = charShapeID
# ...생략...
para.ctrlList.append(ctrl)
return True본문의 문자열 데이터를 담고 있는 t 요소에서 문서 내용을 확인해보겠습니다.
스키마와 표준 문서 내용을 보면 다른 요소와는 구별되는 점이 보입니다.
[KS X 6101] 부속서 E. ParaList XML 스키마
<xs:element name="t">
<xs:complexType mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="markpenBegin" minOccurs="1"></xs:element>
<xs:element name="markpenEnd" minOccurs="1"/>
<xs:element name="titleMark" minOccurs="1"></xs:element>
<xs:element name="tab" minOccurs="1"></xs:element>
<xs:element name="lineBreak" minOccurs="1"/>
<xs:element name="hyphen" minOccurs="1"/>
<xs:element name="nbSpace" minOccurs="1"/>
<xs:element name="fwSpace" minOccurs="1"/>
<xs:element name="insertBegin" type="hp:TrackChangeTag"/>
<xs:element name="insertEnd" type="hp:TrackChangeTag"/>
<xs:element name="deleteBegin" type="hp:TrackChangeTag"/>
<xs:element name="deleteEnd" type="hp:TrackChangeTag"/>
</xs:choice>
<xs:attribute name="charStyleIDRef" type="xs:nonNegativeInteger"/>
</xs:complexType>
</xs:element>[KS X 6101] 10.8.1 내용
<t> 요소는 문서의 실제 글자들을 담고 있는 요소이다. <t> 요소는 요소의 값으로 글자들을 가지게 된다. 단 Tab 글자, 줄바꿈 글자와 같이 특수 글자들은 실제 글자 대신에 하위 요소로서 가지고 있게 된다.
대부분의 요소들은 하위 요소와 속성들로 구성되어 있으나, t 요소는 mixed="true" 속성으로 인해 태그 내에 값을 가질 수 있고, 이 값 영역에 텍스트가 포함되는 형태인 것을 알 수 있습니다.
값과 하위 요소가 교차되면 텍스트가 누락될 수 있기 때문에 재귀적으로 함수를 구성해줍니다.
def _read_text(self, t:ET.Element, ns:dict) -> Text:
para_text = Text()
if t.text:
para_text.text += t.text
for child in t:
child_text = self._read_text(child, ns)
if child_text:
para_text.text += child_text.text
if child.tail:
para_text.text += child.tail
return para_text예제 코드에서는 하위 요소를 처리하지 않고 텍스트만 추출하도록 구현되어 있습니다.
1.2 서식 정보 추출
문서 내용을 이루는 기본 단위인 p 요소는 글자 모양 속성에 따라 run 요소로 구분됩니다.
아래와 같이, 글자 모양이 적용된 문단을 확인해보면 쉽게 이해할 수 있습니다.

<!--section.xml-->
<hp:p paraPrIDRef="20" ...>
<hp:run charPrIDRef="7">
<hp:t>한글</hp:t>
</hp:run>
<hp:run charPrIDRef="0">
<hp:t>과</hp:t>
</hp:run>
<hp:run charPrIDRef="8">
<hp:t>컴퓨터</hp:t>
</hp:run>
</hp:p>section.xml 파일 내용에서 확인할 수 있듯이, 같은 글자 모양이 적용된 문자열이 run의 charPrIDRef 속성으로 구분되는 것입니다.
다음은 글자 모양과 문단 모양을 읽어오는 함수입니다.
def _read_para(self, para_root:ET.Element, ns:dict) -> Para:
para = Para()
# p 속성
# ...생략...
para.paraShapeID = int(para_root.get('paraPrIDRef'))
# ...생략...
def _create_ctrl(self, para:Para, run_root:ET.Element, ns:dict) -> bool:
# run 속성
charShapeID = run_root.get('charPrIDRef')다만, section.xml에서는 각각의 run이 서로 다른 글자 모양을 가지고 있다는 것은 알 수 있지만, run에 적용된 글자 모양이나 문단 모양이 어떤 것인지는 알 수 없습니다. p 요소와 run 요소에 어떤 문단 모양과 글자 모양이 적용되었는지 알기 위해서는 paraPrIDRef, charPrIDRef에 연결된 모양 정보를 header.xml에서 찾아야 합니다.
2. Contents/header.xml 파일 추출
header.xml 파일은 이미 “한/글 문서 파일 형식: Python을 통한 HWPX 포맷 파싱하기 (1)” 에서 다뤘기 때문에, 이번 글에서는 글자 모양과 문단 모양을 추출하고 section.xml과 어떻게 연결되는지 확인하겠습니다.
서식 정보는 refList에 존재합니다. refList에서 글자 모양과 문단 모양을 추출하겠습니다.
[KS X 6101] 부속서 C. Header XML 스키마
<xs:complexType name="HWPMLHeadType">
<xs:sequence>
<!--...생략...-->
<xs:element name="refList" type="MappingTableType" minOccurs="1"/>
<!--...생략...-->
</xs:sequence>
</xs:complexType><xs:complexType name="MappingTableType">
<xs:annotation>
<xs:documentation>
매핑 테이블. 본문에서 사용될 각종 데이터를 가지고 있는 엘리먼트.
</xs:documentation>
</xs:annotation>
<xs:sequence>
<xs:element name="fontfaces">
<xs:complexType>
<xs:sequence>
<xs:element name="fontface" type="FontfaceType" minOccurs="1" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="itemCnt" type="xs:positiveInteger" use="required"/>
</xs:complexType>
</xs:element>
<!--...생략...-->
<xs:element name="charProperties">
<xs:complexType>
<xs:sequence>
<xs:element name="charPr" type="CharShapeType" minOccurs="1" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="itemCnt" type="xs:positiveInteger" use="required"/>
</xs:complexType>
</xs:element>
<!--...생략...-->
<xs:element name="paraProperties">
<xs:complexType>
<xs:sequence>
<xs:element name="paraPr" type="ParaShapeType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="itemCnt" type="xs:positiveInteger" use="required"/>
</xs:complexType>
</xs:element>
<!--...생략...-->
</xs:sequence>
</xs:complexType>[KS X 6101] [표 14] refList 하위 요소
| refList 하위 요소 이름 | 설명 |
|---|---|
| fontfaces | 글꼴 정보 목록 |
| charProperties | 글자 모양 목록 |
| paraProperties | 문단 모양 목록 |
| … | … |
2.1 글자 모양 추출
글자 모양을 담고 있는 charProperties 요소는 목록이고, 내부에 여러 charPr 요소를 포함하고 있는 형태입니다. run 요소에서 가지고 있는 charPrIDRef는 이 charPr 요소의 id와 연결되어 글자 속성을 나타냅니다.
[KS X 6101] 부속서 C. Header XML 스키마
<xs:complexType name="CharShapeType">
<xs:sequence>
<xs:element name="fontRef"><!--...생략...--></xs:element>
<!--...생략...-->
</xs:sequence>
<xs:attribute name="id" type="xs:nonNegativeInteger" use="required"></xs:attribute>
<!--...생략...-->
<xs:attribute name="textColor" type="hc:RGBColorType" default="#000000"></xs:attribute>
<!--...생략...-->
</xs:complexType>[KS X 6101] [표 45] charPr 요소 속성
| charPr 요소 속성 이름 | 설명 |
|---|---|
| id | 글자 모양 정보를 구별하기 위한 아이디 |
| textColor | 글자 색 |
| … | … |
[KS X 6101] [표 46] charPr 하위 요소
| charPr 하위 요소 이름 | 설명 |
|---|---|
| fontRef | 언어별 글꼴. 각 글꼴 타입에 맞게(한글이면 한글 글꼴 타입), 참조하는 글꼴 ID를 언어별로 기술 |
| … | … |
이러한 정보를 토대로 예제 코드를 작성해보면 다음과 같습니다.
# Contents/header.xml 파일 읽기
def _read_header(self) -> bool:
# ...생략...
# 글자 모양 정보
char_shape_list = ref_list.find('hh:charProperties', ns)
for char_pr in char_shape_list.findall('hh:charPr', ns):
char_shape = self._read_char_shape(char_pr, ns)
if char_shape:
doc.shapeManager.charshapeList.append(char_shape)# fontface 요소
@dataclass
class FontData:
fontID: int = 0
fontFace: str = ""
# ... 생략 ...
# charPr 요소
@dataclass
class CharShape:
charShapeID: int = 0
faceID: tuple = field(default_factory=lambda: (0,)*7)
textColor: dict[str, int] = field(default_factory=lambda: {'r': 0, 'g': 0, 'b': 0 })
# ... 생략 ...
def _read_char_shape(self, char_pr:ET.Element, ns:dict) -> CharShape:
char_shape = CharShape()
# charPr 요소 속성
char_shape.charShapeID = int(char_pr.get('id'))
char_shape.textColor = self.hex_to_rgb(char_pr.get('textColor'))
# ...생략...
# charPr 하위 요소
char_shape.faceID = self.lang_data_to_int_tuple(char_pr.find('hh:fontRef', ns))
# ...생략...
return char_shape2.2 문단 모양 추출
문단 모양을 담고 있는 paraProperties 요소도 마찬가지로, 내부에 여러 paraPr 요소를 포함하고 있는 형태입니다. p 요소에서 가지고 있는 paraPrIDRef는 이 paraPr 요소의 id와 연결되어 문단 속성을 나타냅니다.
[KS X 6101] 부속서 C. Header XML 스키마
<xs:complexType name="ParaShapeType">
<xs:sequence>
<xs:element name="align">
<xs:complexType>
<xs:attribute name="horizontal" use="required"><!--...생략...--></xs:attribute>
<!--...생략...-->
</xs:complexType>
</xs:element>
<!--...생략...-->
</xs:sequence>
<xs:attribute name="id" type="xs:nonNegativeInteger" use="required"/>
<!--...생략...-->
</xs:complexType>[KS X 6101] [표 73] paraPr 요소 속성
| paraPr 요소 속성 이름 | 설명 |
|---|---|
| id | 문단 모양 정보를 구별하기 위한 아이디 |
| … | … |
[KS X 6101] [표 74] paraPr 하위 요소
| paraPr 하위 요소 이름 | 설명 |
|---|---|
| align | 문단 내 정렬 설정 |
| … | … |
문단 모양 추출을 위해 작성된 예제 코드입니다.
# paraPr 요소
@dataclass
class ParaShape:
paraShapeID: int = 0
horizontalAlign: str = ''
# ... 생략 ...
def _read_para_shape(self, para_pr:ET.Element, ns:dict) -> ParaShape:
para_shape = ParaShape()
para_shape.paraShapeID = int(para_pr.get('id'))
align = para_pr.find('hh:align', ns)
para_shape.horizontalAlign = align.get('horizontal')
para_shape.verticalAlign = align.get('vertical')
return para_shape지금까지 추출한 본문 내용, 본문의 서식 정보, 글자 모양, 문단 모양을 연결하면 본문의 각 텍스트에 어떤 서식이 적용되어 있는지 알 수 있게 됩니다.
샘플 파일 분석
서식 정보 추출 시 확인한 샘플 파일을 활용해, 추출된 데이터가 실제 문서와 어떻게 연결되는지 알아보겠습니다.
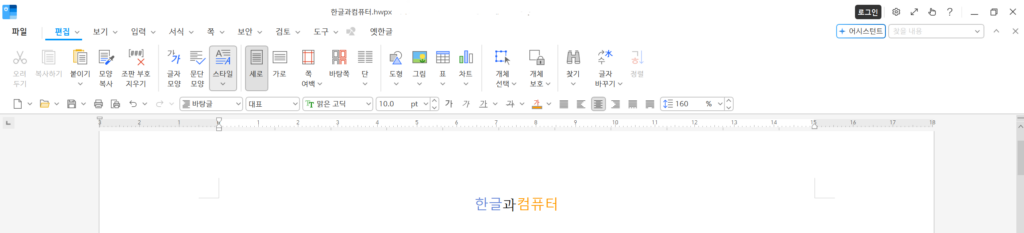
저장된 section.xml 파일 내용을 보면, 1개의 p 요소, 3개의 run이 포함되어 있는 문서인 것을 알 수 있습니다.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<hs:sec> <!--...sec 속성 생략...-->
<hp:p paraPrIDRef="20" >
<hp:run charPrIDRef="7">
<hp:secPr><!--...생략...--></hp:secPr>
<hp:ctrl><!--...생략...--></hp:ctrl>
</hp:run>
<hp:run charPrIDRef="7">
<hp:t>한글</hp:t>
</hp:run>
<hp:run charPrIDRef="0">
<hp:t>과</hp:t>
</hp:run>
<hp:run charPrIDRef="8">
<hp:t>컴퓨터</hp:t>
</hp:run>
</hp:p>
</hs:sec>- Para :
paraPrIDRef="20"hp:secPrhp:ctrl- “한글” :
charPrIDRef="7" - “과” :
charPrIDRef="0" - “컴퓨터” :
charPrIDRef="8"
해당 문단과 각 run에 적용된 문단 모양과 글자 모양이 보입니다. 연결된 서식 정보는 header.xml에서 확인할 수 있습니다.
문단 모양부터 추출하고,
<hh:paraPr id="20" tabPrIDRef="0" condense="0" fontLineHeight="0" snapToGrid="1" suppressLineNumbers="0" checked="0" textDir="LTR">
<hh:align horizontal="CENTER" vertical="BASELINE" />
<!--...생략...-->
</hh:paraPr>paraPrIDRefid="20"hh:alignhorizontal="CENTER"
다음으로는 글자 모양을 추출합니다.
<hh:charPr id="7" textColor="#6182D6">
<hh:fontRef hangul="0" latin="0" hanja="0" japanese="0" other="0" symbol="0" user="0" />
</hh:charPr>charPrid="7"textColor : #6182D6hh:fontRefhangul="2"
폰트 정보도 hh:fontRef에 연결된 ID로 찾을 수 있습니다.
<hh:fontface lang="HANGUL" fontCnt="3">
<hh:font id="0" face="맑은 고딕" type="TTF" isEmbedded="0">
<hh:typeInfo familyType="FCAT_GOTHIC" weight="5" proportion="3" contrast="2" strokeVariation="0" armStyle="0" letterform="2" midline="0" xHeight="4" />
</hh:font>
<!--...생략...-->
</hh:fontface>fontfacelang="HANGUL"hh:fontid="0"face="맑은 고딕"
다른 run도 동일한 방식으로 접근해서 속성 정보를 가져오면, 아래와 같이 추출된 데이터를 정리할 수 있습니다.

마치며
이번 글에서는 문서의 핵심 정보인 본문 데이터를 중심으로, 데이터를 추출하고 추출된 데이터가 서식 정보와 어떻게 연결되는지 실제 문서와 예시 코드를 통해 살펴보았습니다. HWPX 문서에서 section.xml과 header.xml 간의 참조 관계를 이해하고 활용하는 데 도움이 되었길 바랍니다.