요약
리액티브 프로그래밍의 핵심 개념을 소개하고, 이를 기반으로 WebFlux와 Project Reactor를 활용한 웹한글 편집 시스템의 실무 적용 사례를 공유합니다.
1. WebFlux & Project Reactor 전환 배경
웹한글 편집 서비스는 실시간 협업 환경에서 빈번한 I/O 작업이 발생하며, 수천 건의 편집 이벤트와 ‘붙여넣기’, ‘변경 추적’과 같은 기능을 통해 메가 바이트(MB) 단위의 데이터가 짧은 시간 안에 실시간으로 반영되어야 하므로 병목이 쉽게 발생할 수 있습니다. 이러한 처리 특성을 감당하기 위해서는 논블로킹 I/O 기반의 비동기 아키텍처가 필수적입니다.
기존에는 Vert.x 기반의 논블로킹 아키텍처를 운영해왔으나, 내부적으로 블로킹 로직이 다수 존재해 비동기 처리의 이점을 충분히 활용하지 못했고, 점점 증가하는 사용량에 따른 처리 지연과 병목 현상이 누적되면서 구조적인 한계를 체감하고 있었습니다.
이에 따라, 웹한글 백엔드를 Spring 생태계로 통합하고 유지 보수 효율성을 고려해 Spring WebFlux & Project Reactor 조합으로의 전환을 선택했습니다. 이 조합은 리액티브 스트림 표준을 따르며, 선언적이고 직관적인 방식으로 고성능 논블로킹 I/O 처리를 구현할 수 있어, 실시간 문서 편집 서비스에 보다 적합한 선택이었습니다.
2. Reactive Programming
2.1. Reactive System
리액티브 시스템은 소프트웨어가 가져야 할 목표와 특징을 정의하는 ‘아키텍처 패러다임’입니다. 이는 대규모 트래픽, 잦은 장애 등 현대적인 애플리케이션 환경에 대응하기 위해 시스템이 어떻게 설계되어야 하는지에 대한 청사진을 제시합니다.
리액티브 선언문(The Reactive Manifesto)에 따르면, 리액티브 시스템은 다음 네 가지 핵심 원칙을 반드시 지켜야 합니다.
- 응답성 (Responsive): 시스템이 항상 신속하고 일관되게 응답해야 합니다.
- 회복탄력성 (Resilient): 장애가 발생해도 시스템은 응답성을 유지해야 합니다.
- 탄력성 (Elastic): 작업 부하가 변하더라도 시스템은 응답성을 유지해야 합니다.
- 메시지 주도 (Message Driven): 컴포넌트 간 비동기 메시지를 통해 통신하여 느슨한 결합과 격리를 보장합니다.
리액티브 시스템은 우리가 ‘왜’ 리액티브하게 만들어야 하는지에 대한 철학이자 목표입니다.
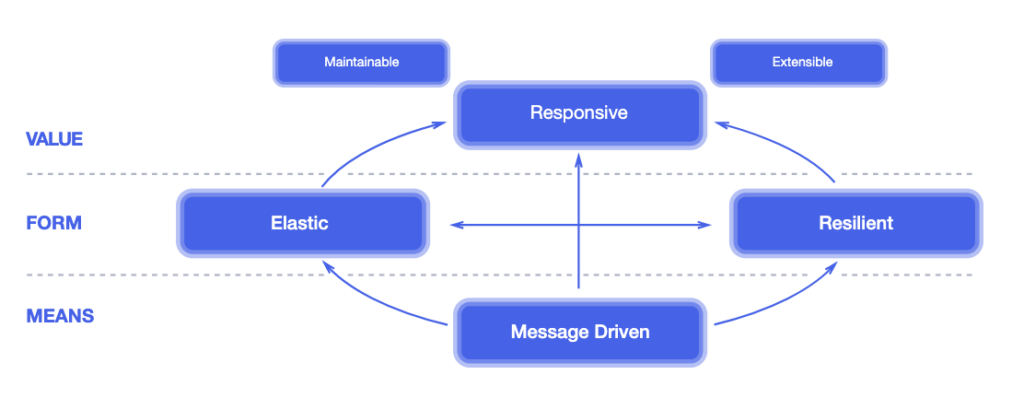
리액티브 시스템의 수단인 메시지 주도(Message Driven) 원칙은 메시지 큐(MQ) 사용 여부, 이벤트 주도 아키텍처(EDA)와 다소 헷갈릴 수 있는데 개념적 차이는 다음과 같습니다.
- 메시지 큐는 비동기 통신을 위한 ‘도구‘로 반드시 메시지 주도 원칙에 필수 요소는 아닙니다.
- 이벤트 주도 아키텍처는 ‘문단 삭제’ 같은 이벤트를 중심으로, 서비스 간의 느슨한 결합을 추구하는 설계 패턴입니다.
- 리액티브 시스템의 메시지 주도 원칙은 메시지를 유일한 통신 수단으로 삼아 컴포넌트 간 명확한 경계를 만들고, 이를 통해 장애 격리와 배압(Backpressure)까지 책임지는 것을 핵심으로 하는 아키텍처 원칙입니다.
2.2. Reactive Programming
Introduction to Reactive Programming :: Reactor Core Reference Guide 에 정의된 리액티브 프로그래밍은 데이터 스트림과 변화의 전파를 다루는 비동기 프로그래밍 패러다임입니다. 이는 곧, 사용되는 프로그래밍 언어를 통해 배열과 같은 정적인 데이터 스트림이나 이벤트 이미터와 같은 동적인 데이터 스트림을 쉽게 표현할 수 있게 된다는 것을 의미합니다.
코드로 보는 선언형 프로그래밍과 명령형 프로그램의 차이
명령형 프로그램
- “어떻게(How)” 처리할 것인지, 그 방법과 절차를 하나하나 명시적으로 지시하는 방식입니다.
- for 루프, if 조건문 등 제어문을 사용해 모든 절차를 직접 제어합니다.
// 사용할 숫자 리스트
List<Integer> numbers = Arrays.asList(1, 10, 3, 8, 5);
// 결과를 담을 새로운 리스트 생성 (상태 변경)
List<Integer> result = new ArrayList<>();
// 1. numbers 리스트의 각 요소를 하나씩 꺼낸다 (for 루프).
for (int number : numbers) {
// 2. 해당 숫자가 5보다 큰지 확인한다 (if 조건문).
if (number > 5) {
// 3. 크다면 2를 곱해서 result 리스트에 추가한다.
result.add(number * 2);
}
}
System.out.println(result); // 최종 결과: [20, 16]선언형 프로그램
- 무엇(What)을 원하는지, 즉 목표를 선언하는 방식입니다. 구체적인 방법은 컴퓨터에 위임합니다.
- “5보다 큰 것만 걸러내”, “각각 2를 곱해” 와 같이 원하는 ‘무엇’을 선언하고 어떻게 순회하고 조건을 검사할지는 스트림 API 내부에 숨겨져 있습니다.
// 사용할 숫자 리스트
List<Integer> numbers = Arrays.asList(1, 10, 3, 8, 5);
// 1. 5보다 큰 숫자들을 (filter)
// 2. 2배로 변환해서 (map)
// 3. 새로운 리스트를 만들어줘 (collect)
List<Integer> result = numbers.stream()
.filter(number -> number > 5)
.map(number -> number * 2)
.collect(Collectors.toList());
// 최종 결과: [20, 16]
System.out.println(result);2.3. Reactive Streams
Reactive Streams 는 다양한 리액티브 프로그래밍 라이브러리들이 서로 원활하게 호환될 수 있도록 만든 기술 표준 명세(Specification)입니다. 이는 라이브러리들이 지켜야 할 최소한의 소통 규칙(API)으로, 자바의 인터페이스(Interface)와 비슷한 역할을 합니다.
핵심 목표는 비동기 스트림 처리 과정에서 논블로킹 Backpressure(Non-blocking Backpressure)를 표준화하여, Publisher가 Subscriber의 처리 속도를 넘지 않도록 데이터 흐름을 안전하게 제어하는 것입니다. 이를 위해 Reactive Streams는 Publisher, Subscriber, Subscription, Processor라는 4개의 핵심 인터페이스를 정의합니다.
결과적으로 Project Reactor, RxJava, Akka Streams 같은 여러 라이브러리들이 모두 이 표준 인터페이스를 구현함으로써, 마치 JDBC 드라이버만 교체하면 다른 데이터베이스를 사용할 수 있는 것처럼 높은 상호 운용성을 확보하게 됩니다.
Reactive Streams 명세에 정의된 4가지 핵심 인터페이스는 다음과 같습니다.
1. Publisher (발행자)
- 데이터 스트림을 생성하고 발행하는 주체입니다. subscribe(Subscriber s) 메서드를 통해 Subscriber가 구독을 신청하면, 해당 Subscriber에게 데이터를 순차적으로 전달할 준비를 합니다.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}2. Subscriber (구독자)
- Publisher가 발행하는 데이터를 소비하는 주체입니다.
- onSubscribe(Subscription s): 구독이 시작될 때 최초 한 번 호출되며, Subscription 객체를 받아 데이터 요청 개수를 조절할 준비를 합니다.
- onNext(T t): Publisher로부터 새로운 데이터를 전달받았을 때 호출됩니다.
- onError(Throwable t): 데이터 처리 중 에러가 발생했을 때 호출됩니다.
- onComplete(): 모든 데이터 발행이 성공적으로 완료되었을 때 호출됩니다.
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}3. Subscription
- Publisher와 Subscriber 사이의 연결고리이며, 데이터 흐름을 제어(Backpressure) 하는 핵심적인 역할을 합니다.
- request(long n): Subscriber가 Publisher에게 처리할 수 있는 데이터의 개수(n)를 요청합니다. 이 메서드를 통해 Backpressure가 구현됩니다.
- cancel(): 구독을 취소하고 더 이상 데이터를 받지 않겠다고 Publisher에게 알립니다.
public interface Subscription {
public void request(long n);
public void cancel();
}4. Processor
- Subscriber와 Publisher의 역할을 동시에 수행하는 중간 처리자입니다. 업스트림(upstream) Publisher로부터 데이터를 구독한 뒤, 가공하여 다운스트림(downstream) Subscriber에게 다시 발행합니다.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}3. Reactive Streams에서 Spring WebFlux로: 이론에서 실전으로
지금까지 우리는 Reactive Streams가 무엇인지, 그리고 왜 필요한지에 대해 알아보았습니다. Reactive Streams는 논블로킹 Backpressure를 기반으로 라이브러리 간의 상호운용성을 보장하는 ‘기술 표준 명세(Specification)’였습니다.
그렇다면 이 훌륭한 표준을 가지고 실제 웹 애플리케이션은 어떻게 만들 수 있을까요? 바로 이 지점에서 Spring WebFlux가 등장합니다.
WebFlux는 Reactive Streams 명세를 완벽하게 구현한 Project Reactor 라이브러리를 기반으로 만들어진 스프링의 리액티브 웹 프레임워크입니다. 즉, WebFlux는 Reactive Streams라는 ‘이론’을 스프링 생태계에서 ‘실전’에 적용할 수 있도록 만든 핵심 도구인 셈입니다.
WebFlux가 어떻게 기존의 Spring MVC와 다르며, Reactive Streams의 원칙을 통해 어떻게 더 적은 자원으로 높은 동시성 트래픽을 처리하는지 자세히 살펴보겠습니다.
3.1. Spring WebFlux의 탄생 배경과 핵심 철학
Spring 팀이 기존의 Spring MVC를 두고 WebFlux라는 새로운 리액티브 웹 프레임워크를 개발한 이유는 두 가지입니다.
- 완전한 논블로킹 스택의 필요성: Servlet(서블릿) 3.1부터 논블로킹 I/O가 가능해졌지만, Filter, getParameter 등 대부분의 서블릿 API는 여전히 동기적(synchronous)이고 블로킹(blocking) 방식으로 동작했습니다. 이로 인해 Netty와 같이 널리 쓰이는 논블로킹 서버의 장점을 온전히 활용하기 어려웠고, 어떤 논블로킹 기술 위에서도 일관되게 동작하는 새로운 공통 API가 필요했습니다.
- 함수형 프로그래밍의 부상: Java 8에 람다(Lambda) 표현식이 도입되면서, 비동기 로직을 선언적으로 구성할 수 있는 함수형 API의 가능성이 열렸습니다. 웹플럭스는 이러한 패러다임을 적극적으로 수용하여, 기존의 어노테이션 방식과 더불어 함수형 웹 엔드포인트(Functional Endpoints)를 제공하게 되었습니다.
3.2. WebFlux의 두 가지 프로그래밍 모델
WebFlux는 개발자에게 두 가지 선택지를 제공하며, 이는 하나의 애플리케이션 안에서 혼용할 수도 있습니다.
- 어노테이션 기반 컨트롤러 (Annotated Controllers): Spring MVC와 거의 동일한 @RestController, @GetMapping 등의 어노테이션을 사용합니다. 덕분에 기존 MVC 개발자들도 쉽게 적응할 수 있으며, 리액티브 타입을 반환값으로 지원하는 일관된 경험을 제공합니다.
- 함수형 엔드포인트 (Functional Endpoints): 람다 기반의 가볍고 유연한 프로그래밍 모델입니다. 개발자가 요청을 라우팅하고 처리하는 전 과정을 직접 제어할 수 있어, 보다 투명하고 명시적인 구성이 가능합니다. 주로 요구사항이 단순한 마이크로 서비스에 적합합니다.
3.3. 그래서, 언제 WebFlux를 사용해야 할까?
Spring MVC와 WebFlux는 경쟁 관계가 아니라 상호 보완적인 관계입니다. 프로젝트의 특성에 따라 적절한 기술을 선택하는 것이 중요합니다.
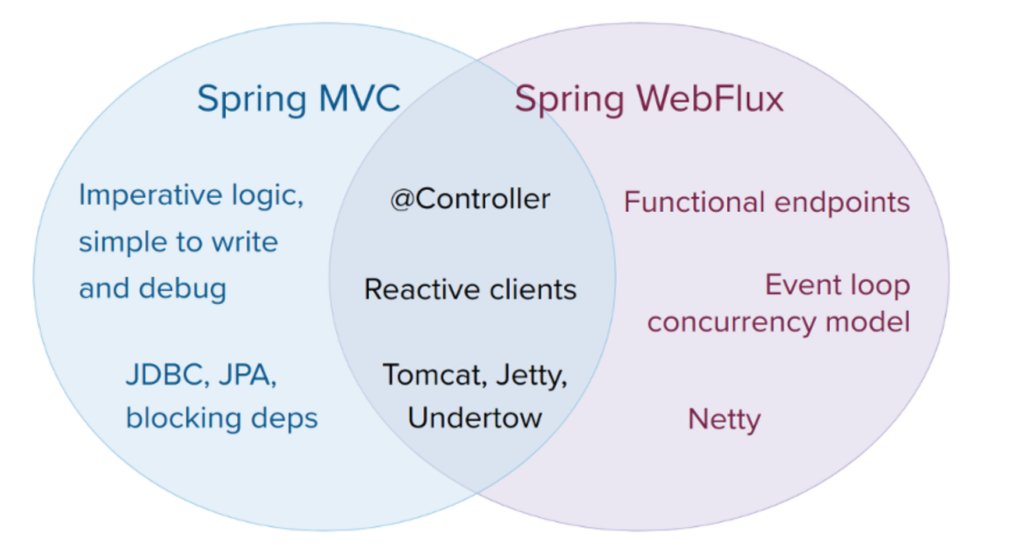
- 바꿀 필요가 없는 경우: 기존 Spring MVC 애플리케이션이 문제없이 잘 동작한다면 굳이 변경할 필요가 없습니다. 명령형 프로그래밍은 코드를 작성하고 디버깅하기 가장 쉬운 방식입니다.
- 블로킹(Blocking) 의존성이 있는 경우: JPA, JDBC와 같이 블로킹 방식으로 동작하는 라이브러리를 사용해야 한다면, Spring MVC가 여전히 최선의 선택입니다. WebFlux에서 블로킹 코드를 별도 스레드에서 실행할 수는 있지만, 이는 논블로킹 스택의 장점을 제대로 활용하지 못하는 방식입니다.
- 점진적으로 도입하고 싶을 때: 기존 MVC 애플리케이션에서 외부 서비스를 비동기적으로 호출해야 할 때, 리액티브 WebClient를 먼저 사용해 볼 수 있습니다. 이는 가장 실용적이고 점진적으로 리액티브 스택의 이점을 경험할 수 있는 방법입니다.
- 새로운 논블로킹 시스템을 구축할 때: 마이크로 서비스 아키텍처에서 높은 트래픽을 효율적으로 처리해야 하는 등 논블로킹 웹 스택이 명확하게 필요한 경우 WebFlux는 훌륭한 선택지입니다.
3.4. 성능과 스레드 모델의 핵심적인 차이
WebFlux를 사용한다고 해서 애플리케이션의 처리 속도가 무조건 빨라지는 것은 아닙니다. 핵심적인 이점은 적은 스레드와 메모리로 높은 확장성과 회복탄력성(resilience)을 확보하는 데 있습니다.
- Spring MVC: 요청마다 스레드를 할당하는 ‘thread-per-request’ 모델을 사용합니다. I/O 작업에서 스레드가 블로킹될 것을 대비해 많은 수의 스레드를 가진 스레드 풀을 사용합니다.
- Spring WebFlux: 이벤트 루프(Event Loop) 방식으로 동작하며, CPU 코어 개수만큼의 적은 스레드로 모든 요청을 처리합니다. 스레드가 절대 블로킹되지 않으므로, 적은 자원으로도 예측 가능하게 확장할 수 있어 대규모 트래픽에 더 효율적으로 대응할 수 있습니다.
3.5. 이벤트 루프의 동작 과정 Deep Dive
그렇다면 어떻게 WebFlux는 단 몇 개의 스레드만으로 수많은 요청을 효율적으로 처리할 수 있는 걸까요? 그 해답은 이벤트 루프(Event Loop)입니다.
3.5.1. WebFlux는 어떻게 Netty를 만나는가?
Spring WebFlux의 기본 서버는 논블로킹 성능이 뛰어난 Netty입니다. Reactor-Netty는 바로 이 WebFlux와 Netty를 매끄럽게 연결해 주는 핵심 라이브러리 역할을 합니다. 따라서 WebFlux의 이벤트 루프를 이해하려면, Reactor-Netty가 Netty를 어떻게 다루는지 살펴보는 것에서부터 시작해야 합니다.
해당 코드는 Spring Boot 2.7.18 버전 기준으로 작성되었습니다.
1단계: LoopResources – 이벤트 루프 설정
모든 것은 이벤트 루프의 스레드 수와 동작 방식을 정의하는 Reactor-Netty의 LoopResources 인터페이스에서 시작됩니다. 이 설정에 따라, 기본 워커 스레드 수는 CPU 코어 수와 4개 중 더 큰 값으로 결정됩니다.
// reactor.netty.resources.LoopResources
public interface LoopResources extends Disposable {
// 기본 I/O 워커 스레드 개수 정의: Math.max(CPU 코어 수, 4)
int DEFAULT_IO_WORKER_COUNT = Integer.parseInt(System.getProperty(
"reactor.netty.ioWorkerCount", "" + Math.max(Runtime.getRuntime().availableProcessors(), 4)));
static LoopResources create(String prefix, int workerCount, boolean daemon) {
// ...
return new DefaultLoopResources(prefix, workerCount, daemon);
}
// 실제 EventLoopGroup을 반환하는 메소드 (구현체에 의해 구현됨)
EventLoopGroup onServer(boolean useNative);
}2단계: NioEventLoopGroup – 객체 생성 및 그룹화
LoopResources의 설정값에 따라 Netty의 NioEventLoopGroup이 조상 클래스인 MultithreadEventExecutorGroup 생성자에서 생성됩니다. 이 단계에서는 for 루프를 돌며 설정된 수만큼 NioEventLoop 객체만 생성할 뿐, 아직 실제 스레드는 시작되지 않습니다.
// io.netty.util.concurrent.MultithreadEventExecutorGroup
protected MultithreadEventExecutorGroup(int nThreads, Executor executor, Object... args) {
// nThreads에는 LoopResources에서 결정된 값이 전달됨
children = new EventExecutor[nThreads];
for (int i = 0; i < nThreads; i++) {
// NioEventLoop 객체만 생성. 아직 스레드는 시작되지 않음.
children[i] = newChild(executor, args);
}
}3단계: SingleThreadEventExecutor – 싱글 스레드 바인딩
각 NioEventLoop가 자신만의 단일 스레드를 갖도록 보장하는 핵심 로직은 SingleThreadEventExecutor 내부에 있습니다.
public abstract class SingleThreadEventExecutor extends AbstractScheduledEventExecutor {
// 1. 자신의 전담 스레드를 저장할 유일한 필드
private volatile Thread thread;
// ...
@Override
public boolean inEventLoop() {
// 3. 현재 코드를 실행하는 스레드가 자신의 전담 스레드인지 확인
return inEventLoop(Thread.currentThread());
}
@Override
public boolean inEventLoop(Thread thread) {
// 2. 파라미터로 받은 스레드가 이전에 저장된 전담 스레드와
// 동일한 객체(인스턴스)인지 비교합니다.
return thread == this.thread;
}
}첫 작업이 execute()를 통해 요청되면(Lazy Start), doStartThread() 메서드가 내부 executor를 통해 새 스레드를 생성합니다. 새로 시작된 이 스레드는 자신을 NioEventLoop의 전담 스레드로 등록(바인딩) 하고, 곧바로 무한 루프인 run() 메서드 실행에 돌입합니다. 이로써 NioEventLoop는 모든 작업을 처리할 자신만의 고정된 싱글 스레드를 확보하여 완벽한 스레드 안전성을 보장합니다.
// io.netty.util.concurrent.SingleThreadEventExecutor
private void doStartThread() {
executor.execute(new Runnable() {
@Override
public void run() {
thread = Thread.currentThread(); // 새로 시작된 스레드의 참조 저장
SingleThreadEventExecutor.this.run(); // NioEventLoop의 run()을 호출
}
});
}4단계: NioEventLoop.run() – 비동기 처리 루프
새로 시작된 스레드는 run() 메서드의 무한 루프에 진입하여 이벤트 루프의 핵심 역할을 시작합니다. 이 루프 안에서 싱글 스레드는 Selector를 이용한 I/O 처리와 Task Queue의 일반 작업 처리라는 두 임무를 빠르게 번갈아 수행하며 논블로킹 동작을 완성합니다.
// io.netty.channel.nio.NioEventLoop의 부모 클래스에 위치한 run() 메소드
@Override
protected void run() {
for (;;) { // 무한 루프
try {
// [임무 1] I/O 이벤트 처리 (Part 1: 대기)
// Selector가 I/O 이벤트를 감지할 때까지 효율적으로 대기합니다.
select(wakenUp.getAndSet(false));
// [임무 1] I/O 이벤트 처리 (Part 2: 실행)
// 준비된 채널에서 발생한 I/O 이벤트를 빠르게 처리합니다.
processSelectedKeys();
} finally {
// [임무 2] 일반 작업(Task) 처리
// I/O 처리 후, 큐에 쌓인 다른 일반 작업들을 모두 처리합니다.
runAllTasks();
}
}
}결론적으로 WebFlux는 CPU 코어 수와 4개 중 더 큰 값만큼의 이벤트 루프를 생성하며, 각 이벤트 루프는 싱글 스레드를 기반으로 동작합니다. 이 싱글 스레드가 논블로킹(Non-blocking) 방식으로 I/O 작업을 처리하기 때문에, 스레드가 멈추는 일 없이 여러 요청을 동시에 다룰 수 있습니다. 이것이 바로 WebFlux가 적은 수의 스레드만으로 수많은 요청을 효율적으로 처리할 수 있는 핵심 원리입니다.
4. 웹한글 적용 사례
지금부터는 기본 개념 설명보다는, 실제 프로젝트를 진행하며 Project Reactor 공식 문서에는 나오지 않는 개념들과 마주쳤던 문제들, 그리고 이를 해결하며 얻은 인사이트를 공유하고자 합니다.
4.1. Spring 프레임워크와 Reactor: subscribe() 호출은 누가, 왜 하는가?
Project Reactor에서 Mono를 사용하여 간단한 코드를 만들었습니다.
public void helloMono() {
Mono.just("Hello, Mono!")
.subscribe(System.out::println);
}
// 출력 결과: Hello, Mono!이 코드에서 Mono는 데이터를 발행하는 Publisher입니다. 실제로 Mono는 Publisher 인터페이스의 구현체이므로 아래와 같이 표현할 수 있습니다.
public void helloMomo() {
Mono<String> mono = Mono.just("Hello, Mono!");
// 또는
Publisher<String> mono = Mono.just("Hello, Mono!");
}실제 계층 구조를 보면 좀 더 이해가 쉽습니다.
public abstract class Mono<T> implements CorePublisher<T> {}
public interface CorePublisher<T> extends Publisher<T> {}여기에 리액티브 프로그래밍의 가장 중요한 원칙이 담겨 있습니다. 바로 subscribe()가 호출되기 전까지는 아무 일도 일어나지 않는다는 것입니다.
Mono.just(“Hello, Mono!”)와 같은 코드는 데이터를 발행할 ‘계획’을 선언한 것에 불과합니다.
이 계획은 .subscribe()가 호출되어야만 실행에 옮겨지며, 이때 비로소 데이터가 파이프라인을 따라 흐르기 시작합니다. 이처럼 구독이 발생하기 전까지 아무 일도 일어나지 않는 동작 방식입니다.
4.1.1. Spring AMQP와 @RabbitListener
(1) 누가 Mono를 구독하는가?
Spring 환경에서 RabbitMQ 메시지를 처리할 때, 아래와 같이 코드를 작성하는 것이 일반적입니다.
@RabbitListener(...)
public Mono<DocResponse> consume(DocMessage message) {
return Mono.just("Success")
.map(l -> DocResponse.builder().result(l).build());
}Project Reactor에 익숙한 개발자라면 의문을 가질 수 있습니다. “모든 Mono나 Flux는 ‘cold’ publisher라서 subscribe()를 호출하기 전까지는 아무 일도 하지 않는데, 왜 이 코드는 동작하는가?”
정답은 “개발자가 아닌, 프레임워크가 구독(subscribe) 하기 때문입니다.”
(2) 프레임워크는 어떻게 동작하는가?
AbstractAdaptableMessageListener.handleResult 내부 코드가 바로 그 핵심적인 증거입니다. Spring AMQP의 리스너 컨테이너는 @RabbitListener가 붙은 메서드의 실행을 관리하는 주체이며, 그 흐름은 다음과 같습니다.
- 반환 타입 감지: 리스너 컨테이너는 consume 메서드가 실행된 후, 그 반환값이 Mono 타입인지 확인합니다 (MonoHandler.isMono(resultArg.getReturnValue())).
- 구독 위임 및 콜백 등록: Mono임이 확인되면, 직접 처리하지 않고 MonoHandler.subscribe()에게 Mono 객체와 함께 세 가지 핵심 동작(콜백)을 정의한 람다(lambda)를 전달하며 구독을 위임합니다.
// AbstractAdaptableMessageListener.handleResult
// 1. 프레임워크가 리스너의 반환값이 Mono 타입인지 확인합니다.
} else if (monoPresent && MonoHandler.isMono(resultArg.getReturnValue())) {
if (!this.isManualAck) {
this.logger.warn("Container AcknowledgeMode must be MANUAL for a Mono<?> return type...");
}
// 2. 확인이 되면, MonoHandler를 통해 반환된 Mono를 '구독'합니다.
MonoHandler.subscribe(resultArg.getReturnValue(),
(r) -> {
// 3-1. Mono가 성공적으로 완료되면 (onNext/onComplete)
this.asyncSuccess(resultArg, request, channel, source, r);
// RabbitMQ에 ACK 신호를 보냅니다.
this.basicAck(request, channel);
},
(t) -> {
// 3-2. Mono가 실패하면 (onError)
this.asyncFailure(request, channel, t);
// 여기서 NACK 또는 재큐(requeue) 로직이 수행됩니다.
},
() -> {
// onNext 없이 onComplete만 오는 경우 (예: Mono<Void>)
this.basicAck(request, channel);
});
} else {
// ...4.1.2. Spring WebFlux와 RouterFunction
@RabbitListener와 마찬가지로, Spring WebFlux의 함수형 엔드 포인트 모델 역시 프레임워크에 구독을 위임하는 대표적인 예시입니다.
(1) 누가 Mono를 구독하는가?
먼저, WebFlux에서 핸들러와 라우터를 정의하는 일반적인 코드입니다.
// RouterFunction: 요청을 어떤 핸들러에 연결할지 정의
@Configuration
public class Router {
@Bean
public RouterFunction<ServerResponse> routerRabbitFunction(RabbitHandler handler) {
return RouterFunctions.route()
.path("/hwp", builder -> builder
.nest(RequestPredicates.accept(MediaType.APPLICATION_JSON), hwpBuilder -> hwpBuilder
.POST("/action/put", handler::put)
)
)
.build();
}
}
// HandlerFunction: "무엇(What)"을 할 것인가 정의
@Component
public class RabbitHandler {
/**
* /hwp/action/put 경로의 POST 요청을 처리합니다.
* 간단히 성공(200 OK) 응답을 담은 Mono<ServerResponse>를 반환합니다.
*
* @param request 서버 요청 객체
* @return 성공 응답을 포함하는 Mono
*/
public Mono<ServerResponse> put(ServerRequest request) {
// 실제 로직에서는 요청 본문을 처리하고 비즈니스 로직을 수행합니다.
// 여기서는 간단히 성공(200 OK) 응답만 반환합니다.
return ServerResponse.ok().build();
}
}여기서도 handler.put 메서드는 Mono<ServerResponse>를 반환할 뿐, subscribe()를 호출하지 않습니다.
(2) 프레임워크는 어떻게 동작하는가?
HTTP 요청이 들어왔을 때, WebFlux의 중앙 처리 장치인 DispatcherHandler가 이 Mono를 받아 처리합니다. 그 흐름은 다음과 같습니다.
① 핸들러 호출 (DispatcherHandler.invokeHandler)
DispatcherHandler는 요청에 맞는 핸들러(RabbitHandler::put)를 찾은 뒤, 적절한 HandlerAdapter(HandlerFunctionAdapter)를 통해 핸들러를 호출합니다. 이 호출의 결과로 개발자가 정의한 Mono<HandlerResult> (내부에 Mono<ServerResponse>가 포함됨)를 얻습니다.
// org.springframework.web.reactive.DispatcherHandler.java
private Mono<HandlerResult> invokeHandler(ServerWebExchange exchange, Object handler) {
if (this.handlerAdapters != null) {
for (HandlerAdapter adapter : this.handlerAdapters) {
if (adapter.supports(handler)) {
// 1. HandlerFunctionAdapter가 핸들러를 실행하고 Mono<HandlerResult>를 반환한다.
return adapter.handle(exchange, handler);
}
}
}
return Mono.error(new IllegalStateException("No HandlerAdapter: " + handler));
}② 결과 처리 (DispatcherHandler.handleResult)
invokeHandler로부터 받은 Mono<HandlerResult>는 handleResult 메서드로 연결됩니다. 여기서 DispatcherHandler는 반환된 결과를 처리할 수 있는 HandlerResultHandler(ServerResponseResultHandler)를 찾아 최종 처리를 위임합니다.
// org.springframework.web.reactive.DispatcherHandler.java
private Mono<Void> handleResult(ServerWebExchange exchange, HandlerResult result) {
// 2. HandlerResult를 처리할 수 있는 HandlerResultHandler를 찾는다.
return getResultHandler(result).handleResult(exchange, result)
.onErrorResume(ex -> result.applyExceptionHandler(ex).flatMap(exceptionResult ->
getResultHandler(exceptionResult).handleResult(exchange, exceptionResult)));
}결론적으로, 개발자가 @RabbitListener나 WebFlux의 HandlerFunction에서 Mono나 Flux를 반환하면, Spring 프레임워크가 대신 subscribe()를 호출합니다. 프레임워크는 Mono의 최종 결과(성공, 실패)에 따라 메시지 ACK/NACK 또는 HTTP 응답/에러를 자동으로 처리하여, 개발자가 비동기 파이프라인의 선언적 정의에만 집중할 수 있도록 합니다.
4.2. Reactor에서 기존 블로킹(Blocking) 코드 처리 방법
외부 HTTP API 호출, 데이터베이스 조회, 파일 시스템 접근과 같은 동기식 블로킹(blocking) 작업들은 WebFlux의 메인 비동기 스레드인 이벤트 루프(Event Loop)를 직접 차단하게 됩니다. 이로 인해 해당 스레드가 다른 요청을 전혀 처리하지 못하게 되어, 시스템 전체의 성능 저하와 응답 지연을 초래합니다.
Project Reactor에서 Reactor에서 기존 블로킹(Blocking) 코드 처리 방법 은 블로킹 코드를 리액티브 스트림에 안전하게 통합하는 3단계 핵심 지침을 설명합니다.
Mono blockingWrapper = Mono.fromCallable(() -> {
return /* make a remote synchronous call */
});
blockingWrapper = blockingWrapper.subscribeOn(Schedulers.boundedElastic());블로킹 코드를 리액티브 스트림에 안전하게 통합하는 3단계 핵심 지침
- Mono.fromCallable 사용: 동기식 블로킹 코드를 Mono로 감싸서, 실제 실행을 구독 시점까지 지연시킵니다.
- 블로킹 작업 반환: fromCallable에 전달된 람다 함수는 블로킹 작업을 수행한 후 그 결괏값을 반환합니다.
- Schedulers.boundedElastic에서 실행 보장: subscribeOn()을 사용하여, 구독이 발생하면 블로킹 작업이 I/O에 최적화된 별도의 전용 스레드에서 실행되도록 지정합니다.
이 세 단계를 통해 메인 스레드를 막지 않고 안전하게 블로킹 코드를 처리할 수 있습니다.
4.2.1. 실행을 구독 시점까지 지연시키는 operator들
fromCallable, fromSupplier, fromRunnable이 받는 함수형 인터페이스의 시그니처를 통해 각 연산자의 역할과 차이점을 명확하게 이해할 수 있습니다.
① fromCallable
fromCallable은 값을 반환하면서 동시에 파일 I/O나 네트워크 통신처럼 Checked Exception이 발생할 수 있는 블로킹 작업을 래핑 하는 데 가장 적합합니다. Reactor는 call() 메서드 실행 시 발생하는 모든 예외를 onError 시그널로 변환하여 안전하게 처리해 줍니다.
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}calculateAverage와 같이 Exception을 던질 수 있고 값을 반환하는 기존의 블로킹 메서드가 있다면 Mono.fromCallable을 통해 다음과 같이 실행을 지연시킬 수 있습니다.
// 빈 리스트를 전달하면 평균 계산 시 예외를 발생시키는 Mono.fromCallable() 기반 코드
@Test
public void fromCallable_averageException() {
List<Integer> list = List.of(); // 빈 리스트
// 2. Mono.fromCallable()이 해당 예외를 onError로 전달
Mono.fromCallable(() -> calculateAverage(list))
.subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
}
// 1. 빈 리스트일 경우 .orElseThrow(...)에서 명시적으로 new Exception(...) 발생
private static double calculateAverage(List<Integer> list) throws Exception {
Logger.info("Calculating average: ", list);
return list.stream()
.mapToInt(i -> i)
.average()
.orElseThrow(() -> new Exception("List is empty, cannot calculate average"));
}
// 출력 결과
INFO <2025-07-21 10:31:49.155>[Logger:12] [main] Calculating average:
ERROR <2025-07-21 10:31:49.162>[Logger:43] [main] # onError() :
java.lang.Exception: List is empty, cannot calculate average
at com.hancom.reactive.MonoTester.lambda$calculateAverage$7(MonoTester.java:77)
at java.base/java.util.OptionalDouble.orElseThrow(OptionalDouble.java:274)
at com.hancom.reactive.MonoTester.calculateAverage(MonoTester.java:77)
at com.hancom.reactive.MonoTester.lambda$fromCallable_averageException$5(MonoTester.java:65)
at com.hancom.reactive.MonoTester.fromCallable_averageException(MonoTester.java:66)② fromSupplier
fromSupplier는 fromCallable과 비슷하게 값을 반환하지만, Checked Exception을 처리하지 않는 작업에 사용됩니다. 예외 발생 가능성이 없는 간단한 객체 생성, 캐시 조회 등 상대적으로 안전한 값의 지연 생성에 주로 사용됩니다. RuntimeException은 발생할 수 있으며, 이 경우 onError로 처리됩니다.
@FunctionalInterface
public interface Supplier<T> {
T get();
}fromCallable로 작성된 예제를 fromSupplier로 변경할 경우, Checked Exception을 처리하는 방식에 어떤 차이가 있는지 알아보겠습니다.
// 빈 리스트를 전달하면 평균 계산 시 예외를 발생시키는 Mono.fromSupplier() 기반 코드 (비추천)
@Test
public void fromSupplier_averageException() {
List<Integer> list = List.of(); // 빈 리스트
// 2. Mono.fromSupplier()는 throws Exception을 허용하지 않음
// 그래서 내부에서 checked exception이 발생할 경우
Mono.fromSupplier(() -> {
try {
return calculateAverage(list);
} catch (Exception e) {
// 3. catch 블록에서 RuntimeException으로 변환해 던지면
// Reactor는 이를 감지하고 onError(Throwable) 콜백으로 전달
throw new RuntimeException(e);
}
}).subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
}
// 1. 빈 리스트일 경우 .orElseThrow(...)에서 명시적으로 new Exception(...) 발생
private static double calculateAverage(List<Integer> list) throws Exception {
Logger.info("Calculating average: ", list);
return list.stream()
.mapToInt(i -> i)
.average()
.orElseThrow(() -> new Exception("List is empty, cannot calculate average"));
}
// 출력 결과
INFO <2025-07-21 10:26:35.835>[Logger:12] [main] Calculating average:
ERROR <2025-07-21 10:26:35.843>[Logger:43] [main] # onError() :
java.lang.RuntimeException: java.lang.Exception: List is empty, cannot calculate average
at com.hancom.reactive.MonoTester.lambda$fromSupplier_averageException$8(MonoTester.java:93)
at com.hancom.reactive.MonoTester.fromSupplier_averageException(MonoTester.java:95)
Caused by: java.lang.Exception: List is empty, cannot calculate average
at com.hancom.reactive.MonoTester.lambda$calculateAverage$7(MonoTester.java:77)
at java.base/java.util.OptionalDouble.orElseThrow(OptionalDouble.java:274)
at com.hancom.reactive.MonoTester.calculateAverage(MonoTester.java:77)
at com.hancom.reactive.MonoTester.lambda$fromSupplier_averageException$8(MonoTester.java:89)③ fromRunnable
fromRunnable은 리소스 정리, 로그 기록처럼 결괏값이 필요 없고 작업 수행 자체가 중요한 경우에 사용됩니다. 작업이 성공적으로 완료되면 onComplete 시그널을, RuntimeException 발생 시 onError 시그널을 보냅니다.
@FunctionalInterface
public interface Runnable {
public abstract void run();
}Mono.fromRunnable의 동작을 이해하려면 어떤 시그널이 발생하는지 확인하는 것이 중요합니다. Mono.fromRunnable은 값을 반환하지 않기 때문에, onNext 시그널 대신 작업 성공 시 onComplete 시그널만 발생합니다.
@Test
public void fromRunnable_voidFunctionCall() {
Mono.fromRunnable(() -> performSideEffect())
.subscribe(
Logger::onNext, // Mono<Void> 이므로 호출되지 않음
Logger::onError,
Logger::onComplete
);
}
private static void performSideEffect() {
Logger.info("Side-effect executed");
}
// 출력 결과
INFO <2025-07-21 11:12:44.719>[Logger:8] [main] # info : Side-effect executed
INFO <2025-07-21 11:12:44.722>[Logger:47] [main] # onComplete()④ defer
구독이 발생할 때마다 새로운 Publisher(Mono 또는 Flux)를 생성하고자 할 때 사용하는 연산자입니다.
public static <T> Mono<T> defer(Supplier<? extends Mono<? extends T>> supplier)
public static <T> Flux<T> defer(Supplier<? extends Publisher<T>> supplier)Mono.defer()는 구독 시점마다 Supplier.get()을 호출하여 새로운 Mono 인스턴스를 리턴하고, 그 Mono에 실제로 구독하는 과정을 명확하게 보여줍니다.
@Test
public void defer_calls_supplier_on_each_subscribe() {
AtomicInteger counter = new AtomicInteger(1);
// 구독할 때마다 supplier.get() 호출되어 새로운 Mono 생성
Mono<String> mono = Mono.defer(() -> {
String value = "Value-" + counter.getAndIncrement();
System.out.println("[Supplier] Creating Mono with: " + value);
return Mono.just(value);
});
// 첫 번째 구독
mono.subscribe(val -> System.out.println("[Subscriber 1] Received: " + val));
// 두 번째 구독
mono.subscribe(val -> System.out.println("[Subscriber 2] Received: " + val));
}
// 실행 결과
[Supplier] Creating Mono with: Value-1
[Subscriber 1] Received: Value-1
[Supplier] Creating Mono with: Value-2
[Subscriber 2] Received: Value-2웹한글 실전 패턴 I – 기존 블로킹 코드의 안전한 통합 패턴
1. 기존 블로킹 코드의 안전한 통합 패턴
기존의 블로킹 코드를 fromCallable, fromRunnable로 감싸 실행을 지연시키고, subscribeOn으로 전용 스레드 풀에 위임하여 비동기 흐름에 안전하게 통합합니다.
// 기존 블로킹 코드를 비동기 흐름으로 감싸는 경우 - fromCallable, fromRunnable, subscribeOn 연산자 복합 사용 사례
public Mono<Void> cancel(String docId) {
return Mono.fromCallable(() -> getActionEmitter(docId))
.subscribeOn(HwpSchedulers.emitterScheduler())
.flatMap(actionEmitter -> Mono.fromRunnable(actionEmitter::cancelFutures))
.then();
}2. 조건부 분기에 따른 Publisher 지연 생성 패턴
Mono.defer를 사용하여, 구독 시점의 조건(예: 트랜잭션 사용 여부)에 따라 동적으로 다른 Mono 파이프라인을 생성하고 실행합니다.
// 분기에 따라 다른 Publisher 는 생성해야 경우 - defer 연산자 사용 사례
private Mono<Void> handleAction(String docId, int revision, HwpJsonObject action, boolean isListAction) {
// useTransaction 조건에 따라 다른 Mono 가 생성
return Mono.defer(() -> useTransaction
? doActionWithTransaction(docId, revision, action, isListAction)
: doAction(docId, revision, action, isListAction))
.onErrorResume(err -> generateActionMessage("handleActionWithEmitter")
.doOnNext(msg -> log.error(msg, err))
.flatMap(msg -> Mono.error(err))
);
}리액티브 스트림의 취소 한계: fromCallable 패턴의 숨겨진 리스크
Mono.fromCallable 패턴은 블로킹 작업을 감싸기에 편리하지만, 취소가 제대로 동작하지 않는 한계가 있습니다. Reactor는 구독을 취소하면 스레드를 interrupt() 하지만, 대부분의 블로킹 I/O는 이 신호를 무시합니다. 결국 작업은 백그라운드에서 끝까지 실행되고, 필요 없는 스레드가 계속 점유됩니다. 이로 인해 스레드 풀이 고갈되면, 전체 시스템에 부하나 장애가 전파될 수 있습니다.
이를 방지하려면 timeout()을 설정해 응답 지연을 차단해야 합니다. 다만 타임아웃이 발생해도 작업 자체는 계속되므로, fromCallable 사용 시에는 신중한 설계와 방어 전략이 꼭 필요합니다.
Disposable disposable = Mono.fromCallable(() -> blockingApiCall()) // 2초 소요
.subscribeOn(Schedulers.boundedElastic())
.subscribe();
// 100ms 후에 취소를 시도하지만, blockingApiCall()은 멈추지 않고 계속 실행됩니다.
Thread.sleep(100);
disposable.dispose(); 4.3. 구독 시점까지 실행을 지연시켜야 되는 이유
경험상 구독 시점까지 실행을 지연시켜야 하는 이유를 두 가지로 들 수 있습니다.
4.3.1. 실행 시점의 안전성 확보
먼저, 명령형 if-else 구문은 어떻게 선언형으로 만들 수 있을까요?
// if-else 에 대한 명령형 코드
public void switchIfEmpty_성공_케이스_명령형() {
boolean isSuccess = true;
MongoResult mongoResult = new MongoResult(isSuccess, null);
if (mongoResult.isSuccess()) {
Logger.info("Success"); // 실행
} else {
Logger.error(mongoResult.e); // 실행되지 않음
}
}명령형 if-else 구문을 filter와 switchIfEmpty 조합으로 바꾸는 것은 흔한 리액티브 리팩토링 패턴입니다. 하지만 아래 코드를 실행해 보면 filter 조건을 통과하여 switchIfEmpty가 동작할 필요가 없는 상황임에도, 그 인자로 전달된 Mono.error() 때문에 NullPointerException이 발생하는 이유는 무엇일까요?
public void switchIfEmpty_성공_케이스_선언형_오류발생() {
boolean isSuccess = true;
MongoResult mongoResult = new MongoResult(isSuccess, null);
Mono.just(mongoResult)
.filter(MongoResult::isSuccess) // if 에 대응하는 operator
.switchIfEmpty(Mono.error(mongoResult.e)) // else 에 대응하는 operator
.subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
}
// 출력 결과
java.lang.NullPointerException: error
at java.base/java.util.Objects.requireNonNull(Objects.java:233)
at com.hancom.reactors.prototype.TransformTester.switchIfEmpty_성공_케이스_선언형_오류발생(TransformTester.java:169)NullPointerException이 발생하는 시점을 살펴보면, switchIfEmpty의 인자는 스트림 결과와 무관하게 즉시 평가(Eager Evaluation) 되기 때문에, Mono.error()가 먼저 실행되어 오류가 발생합니다. 이 문제를 해결하려면 아래와 같이 Mono.defer를 사용해 Mono.error()의 생성을 지연 평가(Lazy Evaluation) 하도록 변경해야 합니다.
웹한글 실전 패턴 II – 실행 지연
switchIfEmpty는 인자를 즉시 평가하므로, Mono.defer로 대체 로직을 감싸 필요한 시점에만 실행되도록 하여 불필요한 오류를 방지합니다.
@Test
public void switchIfEmpty_성공_케이스_선언형() {
boolean isSuccess = true;
MongoResult mongoResult = new MongoResult(isSuccess, null);
Mono.just(mongoResult)
.filter(MongoResult::isSuccess)
.switchIfEmpty(Mono.defer(() -> Mono.error(mongoResult.e))) // 실패 시 예외로 전환
.subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
}
// 출력 결과
INFO <2025-07-21 11:35:58.447>[Logger:31] [main] # onNext() : MongoResult[isSuccess=true, e=null]
INFO <2025-07-21 11:35:58.459>[Logger:47] [main] # onComplete()4.3.2. 리소스 낭비 또는 메모리 누수 방지
앞서 살펴본 예제에서 Mono.error(mongoResult.e)가 실제로 실행되지 않더라도 인자로 주어진 시점에 즉시 평가되어 NullPointerException을 유발했듯이, 리액티브 스트림에서 선언 시점에 평가(Eager Evaluation) 되는 값들은 불필요한 객체 생성, 계산 수행, 리소스 점유로 이어질 수 있습니다.
예를 들어 다음과 같은 코드가 있다고 가정해 보겠습니다.
Flux<Integer> flux = Flux.fromIterable(createLargeList()); // 선언 즉시 List 생성createLargeList()는 메모리를 많이 잡아먹는 연산이고, 실제로 구독되지 않으면 아무 의미도 없습니다. 하지만 선언 시점에 이미 리스트가 메모리에 올라가기 때문에, 이 Flux가 끝내 사용되지 않더라도 리소스는 낭비되고 GC 대상에서 누락될 수 있습니다.
이러한 경우에도 defer를 사용하면 구독 시점까지 객체 생성을 미루어 불필요한 리소스 낭비를 방지할 수 있습니다.
Flux<Integer> flux = Flux.defer(() -> Flux.fromIterable(createLargeList())); // 구독 시점까지 List 생성을 지연Eager Evaluation 와 Lazy Evaluation
Java에서 즉시 평가(Eager Evaluation)는 코드가 작성된 순서대로 즉시 값을 계산하는 기본 동작 방식이며, 지연 평가(Lazy Evaluation)는 실제로 그 값이 필요한 시점까지 계산을 미루는 프로그래밍 기법입니다.
결론적으로, 리액티브 스트림에서 실행을 구독 시점까지 지연시키는 것은 Java의 즉시 평가(Eager Evaluation)로 인해 발생할 수 있는 예기치 않은 오류를 방지하고 불필요한 리소스 낭비를 막는 핵심 전략입니다. defer와 같은 연산자는 값이나 객체의 생성마저 구독 시점까지 미루어, 스트림 전체를 안전하고 효율적인 지연 평가(Lazy Evaluation) 모델로 완성시켜 줍니다.
4.4. Reactor Schedulers 심화 전략: Prefetch와 커스텀 스레드 풀을 이용한 성능 및 안정성 제어
다양한 종류의 블로킹 I/O(DB, Redis, 외부 API 등)가 하나의 기본 boundedElastic 스레드 풀을 공유하면, 특정 시스템의 장애가 다른 시스템에 영향을 미치는 ‘자원 경합’ 및 ‘장애 전파’의 원인이 될 수 있습니다. 따라서 대규모 시스템에서는 각 워크 로드의 특성에 맞춰 실행 컨텍스트를 의도적으로 격리하고 제어하는 것이 필수적입니다.
4.4.1. 핵심 개념: 스레드 풀과 동시성(Prefetch)의 분리
본격적인 패턴을 살펴보기 앞서, Reactor의 성능을 제어하는 두 가지 독립적인 요소를 명확히 구분해야 합니다.
- Schedulers.boundedElastic() (스레드 풀)
- 블로킹 작업을 실행할 ‘worker 스레드’의 총량을 관리합니다. 이 스레드 풀의 최대 크기는 기본적으로 CPU 코어 수의 10배이며, 동시에 실행될 수 있는 작업의 물리적 한계를 결정합니다.
- flatMap의 prefetch (작업 요청량)
- flatMap이 한 번에 동시적으로 처리할 내부 스트림의 개수를 제어합니다. 이 값은 reactor.bufferSize.small 시스템 프로퍼티(기본값 256)나 flatMap의 concurrency 인자로 결정되며, 백프레셔를 관리하는 역할을 합니다.
- 75% 보충 규칙: flatMap은 처음에 prefetch 개수만큼 작업을 요청하고, 그중 75%가 완료되면 다시 75%만큼의 새 작업을 요청하여 파이프라인이 멈추지 않도록 효율적으로 관리합니다.
이 두 가지는 서로 다른 것을 제어하며, prefetch 값이 스레드 풀의 크기를 직접 제한하지 않습니다.
4.4.2. 사례 분석: Prefetch 제어를 스레드 풀 제어로 오해하는 경우
아래 코드는 reactor.bufferSize.small 값을 16으로 설정하여 flatMap의 동시성을 16으로 제한합니다. 로그에서 최대 16개의 스레드가 보이는 것은, flatMap이 동시에 16개의 작업만 진행했고 각 작업이 짧아 스케줄러가 16개 이상의 스레드를 사용할 필요가 없었기 때문일 뿐, 스레드 풀 자체가 16개로 제한된 것은 아닙니다.
@Test
public void thread_on_boundedElastic() throws InterruptedException {
System.setProperty("reactor.bufferSize.small", "16"); // flatMap의 동시성을 16으로 제한
Flux.range(1, 1000)
.flatMap(i -> Mono.fromCallable(() -> {
Thread.sleep(10);
return "value is " + i;
})
.subscribeOn(Schedulers.boundedElastic()))
.subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
Thread.sleep(3000);
}로그 출력 결과를 보면 boundedElastic-1부터 boundedElastic-16까지 다양한 스레드가 사용되지만, 스레드 이름만으로는 어떤 작업인지 구별하기 어렵고, 다른 블로킹 작업과 스레드를 공유할 위험이 남아있습니다.
INFO <2025-07-23 07:56:50.063>[Logger:31] [boundedElastic-10] # onNext() : value is 10
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 1
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 2
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 3
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 4
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 5
INFO <2025-07-23 07:56:50.067>[Logger:31] [boundedElastic-10] # onNext() : value is 6
INFO <2025-07-23 07:56:50.068>[Logger:31] [boundedElastic-10] # onNext() : value is 7
INFO <2025-07-23 07:56:50.068>[Logger:31] [boundedElastic-10] # onNext() : value is 8
INFO <2025-07-23 07:56:50.068>[Logger:31] [boundedElastic-10] # onNext() : value is 9
INFO <2025-07-23 07:56:50.068>[Logger:31] [boundedElastic-10] # onNext() : value is 11
INFO <2025-07-23 07:56:50.069>[Logger:31] [boundedElastic-10] # onNext() : value is 12
INFO <2025-07-23 07:56:50.069>[Logger:31] [boundedElastic-10] # onNext() : value is 13
INFO <2025-07-23 07:56:50.069>[Logger:31] [boundedElastic-10] # onNext() : value is 14
INFO <2025-07-23 07:56:50.069>[Logger:31] [boundedElastic-10] # onNext() : value is 15
INFO <2025-07-23 07:56:50.069>[Logger:31] [boundedElastic-10] # onNext() : value is 16
...
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 932
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 929
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 942
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 943
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 930
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 931
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 933
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 934
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 935
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 936
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 937
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 944
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 938
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 939
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 940
INFO <2025-07-23 08:13:58.084>[Logger:31] [boundedElastic-16] # onNext() : value is 941
..
INFO <2025-07-23 07:56:51.050>[Logger:47] [boundedElastic-11] # onComplete()4.4.3. 해결책: newBoundedElastic을 이용한 명시적 제어
워크 로드를 안정적으로 격리하고 제어하기 위한 올바른 방법은 Schedulers.newBoundedElastic()으로 커스텀 스케줄러를 생성하는 것입니다.
@Test
public void thread_on_newBoundedElastic() throws InterruptedException {
// 최대 16개 스레드를 사용하는 "WEBHWP-THREAD"라는 이름의 커스텀 스케줄러 생성
Scheduler customScheduler = Schedulers.newBoundedElastic(16, Integer.MAX_VALUE, "WEBHWP-THREAD");
Flux.range(1, 1000)
.flatMap(i -> Mono.fromCallable(() -> {
Thread.sleep(10);
return "value is " + i;
})
.subscribeOn(customScheduler)) // 커스텀 스케줄러 사용
.subscribe(Logger::onNext, Logger::onError, Logger::onComplete);
Thread.sleep(3000);
}로그 출력 결과를 보면 WEBHWP-THREAD-1부터 WEBHWP-THREAD-16까지 (스레드 번호 랜덤) 명확한 이름으로 로그가 출력되어, 해당 작업이 ‘웹한글’ 관련 작업임을 쉽게 인지할 수 있습니다.
INFO <2025-07-23 08:06:09.861>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 10
INFO <2025-07-23 08:06:09.863>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 1
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 2
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 3
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 4
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 5
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 6
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 7
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 8
INFO <2025-07-23 08:06:09.864>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 9
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 11
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 12
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 13
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 14
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 15
INFO <2025-07-23 08:06:09.865>[Logger:31] [WEBHWP-THREAD-10] # onNext() : value is 16
..
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 591
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 576
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 578
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 579
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 581
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 583
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 584
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 585
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 586
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 587
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 588
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 589
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 590
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 577
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 593
INFO <2025-07-23 08:06:10.437>[Logger:31] [WEBHWP-THREAD-16] # onNext() : value is 582
..
INFO <2025-07-23 08:06:10.850>[Logger:47] [WEBHWP-THREAD-8] # onComplete()4.4.4. 커스텀 스케줄러의 장점
이처럼 커스텀 스케줄러를 생성하는 것은 다음과 같은 명확한 장점을 제공합니다.
- 명확한 리소스 제어: newBoundedElastic(16, …)의 첫 인자는 스레드 풀의 최대 개수를 16개로 명시적으로 제한하여 리소스 사용량을 예측하고 제어할 수 있게 합니다.
- 향상된 관찰 가능성 (Observability): 로그나 스레드 덤프 분석 시 WEBHWP-THREAD라는 이름은 해당 스레드가 어떤 작업을 수행하는지 즉시 알려주어, 문제 해결 시간을 크게 단축시킵니다.
- 장애 격리를 통한 안정성 향상: 여러 I/O 작업이 하나의 공유 스레드 풀을 사용할 때 발생하는 ‘자원 경합’ 및 ‘장애 전파’를 원천적으로 차단하여 시스템 전체의 안정성을 높입니다.
웹한글 실전 패턴 III – 커스텀 스케줄러
1. 중앙화된 목적 기반 스케줄러 설계
HwpSchedulers 클래스 예시처럼, 애플리케이션의 주요 I/O 및 비동기 작업 유형에 맞춰 커스텀 스케줄러를 중앙에서 관리하고 있습니다.
- 목적: 기본 Schedulers.boundedElastic()을 무분별하게 공유하는 대신, Redis 용, 메시지 큐 Consumer 용, 파일 I/O(Output) 용 등 워크 로드별로 전용 스레드 풀을 할당합니다.
- 기대효과:
- 장애 격리: HWP-REDIS 스레드 풀에 문제가 생겨도 다른 HWP-OUTPUT 스레드 풀에 영향을 주지 않아 시스템 전체의 안정성이 높아집니다.
- 관찰 가능성: 로그나 스레드 덤프에서 HWP-CONSUMER-S 같은 명확한 스레드 이름을 통해 문제의 원인을 신속하게 파악할 수 있습니다.
public class HwpSchedulers {
private static final Scheduler CONSUMER_SINGLE_SCHEDULER = Schedulers.newSingle("HWP-CONSUMER-S");
private static final Scheduler REDIS_SCHEDULER = Schedulers.newBoundedElastic(DEFAULT_BOUNDED_ELASTIC_SIZE,
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE, "HWP-REDIS");
private static final Scheduler DEFAULT_OUTPUT_SCHEDULER = Schedulers.newBoundedElastic(255, // gridfs
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE, "HWP-OUTPUT");
private static final Scheduler LATENCY_SCHEDULER = Schedulers.newBoundedElastic(DEFAULT_BOUNDED_ELASTIC_SIZE,
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE, "HWP-LATENCY", ACTION_REPORT_INTERVAL * 2, false);
...
}2. 파이프라인 단계별 스레드 격리
하나의 비동기 파이프라인 안에서도 작업의 성격은 다를 수 있습니다. subscribeOn과 publishOn을 함께 사용하면, 각 단계에 최적화된 스레드 모델을 적용하여 리소스 효율을 극대화할 수 있습니다.
- 목적: I/O 집약적인 ‘데이터 소스’ 작업과, 이후의 ‘데이터 처리’ 작업을 서로 다른 스레드 풀에서 실행하도록 분리합니다.
- 패턴:
- subscribeOn으로 I/O 작업을 전용 스케줄러(예: redisScheduler)에 위임합니다.
- publishOn으로 후처리 작업을 다른 스케줄러(예: outputScheduler)로 즉시 전환합니다.
- 기대효과: I/O 전용 스레드가 후처리를 기다리지 않고 바로 다른 I/O 작업을 처리하러 갈 수 있어, 시스템 전체의 처리량(Throughput)이 향상됩니다.
private static final Scheduler REDIS_SCHEDULER = Schedulers.newBoundedElastic(DEFAULT_BOUNDED_ELASTIC_SIZE,
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE, "HWP-REDIS");
private static final Scheduler DEFAULT_OUTPUT_SCHEDULER = Schedulers.newBoundedElastic(255, // gridfs
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE, "HWP-OUTPUT");
public Mono<Long> time() {
return Mono.fromCallable(otRedis::time)
.subscribeOn(HwpSchedulers.redisScheduler())
.onErrorResume(err -> generateMessage("time")
.doOnNext(msg -> log.warn(msg, err))
.map(msg -> System.currentTimeMillis())
)
.publishOn(HwpSchedulers.outputScheduler());
}3. Mongo Reactive 드라이버 연동 시 스레드 할당
Mongo reactive나 Redis reactive 같은 리액티브 드라이버를 사용할 경우, 스케줄러 사용법에 주의해야 합니다. 참고로, 웹한글은 Mongo reactive만 개발되어 있는 상태입니다.
- 핵심: 리액티브 드라이버는 이미 내부적으로 논블로킹 I/O 스레드를 효율적으로 관리하고 있습니다.
- 안티 패턴: 리액티브 드라이버 호출을 subscribeOn(Schedulers.boundedElastic())으로 감싸는 것은 불필요한 스레드 컨텍스트 스위칭을 유발하고, 오히려 성능을 저하시킬 수 있습니다. 드라이버의 논블로킹 I/O 스레드에서 처리하면 될 일을 굳이 블로킹 I/O 용 스레드로 옮기는 셈이기 때문입니다.
// GOOD: 드라이버가 스레드를 관리하도록 그대로 둡니다.
Mono<User> user = reactiveMongoRepository.findById("123");
// BAD (Anti-pattern): 불필요하게 boundedElastic 스레드로 작업을 옮깁니다.
Mono<User> user = reactiveMongoRepository.findById("123")
.subscribeOn(Schedulers.boundedElastic());단, DB 조회 후 CPU 집약적인 후처리 작업이 있다면, 그때는 publishOn을 사용해 이벤트 루프 스레드를 차단하지 않도록 작업을 분리하는 것이 좋습니다.
4. 단일 스레드 스케줄러를 이용한 순차 처리 보장
- 문제점: RabbitMQ의 prefetch 기능은 성능 향상을 위해 여러 메시지를 미리 가져오지만, 이 메시지들을 병렬로 처리하면 큐에 들어온 순서가 보장되지 않는 문제가 발생할 수 있습니다. flatMap과 같은 연산자는 기본적으로 병렬로 동작하기 때문에, 문서 수정 이력이나 트랜잭션과 같이 순서가 매우 중요한 워크 로드에는 부적합합니다.
- 해결책: 이 문제를 해결하기 위해, 각 메시지를 처리하는 리액티브 파이프라인 전체를 스레드가 하나인 전용 스케줄러에서 실행하여 순서를 강제할 수 있습니다. 단, 순서 보장이 필요한 파이프라인까지는 별도의 스케줄러를 할당하지 말아야 합니다.
@RabbitListener(..)
public Mono<DocResponse> consume(final @Payload @Valid DocMessage message, @Header(AmqpHeaders.CONSUMER_QUEUE) String queueName) {
return onMessage(message, queueName);
}
public Mono<DocResponse> onMessage(DocMessage docMessage, String queueName) {
return process(docMessage, queueName)
.subscribeOn(HwpSchedulers.consumerSingleScheduler());
}5. 복잡한 리액티브 파이프라인의 스레드 모델은 추측이 아닌 경험적 데이터로 검증
웹한글의 액션 처리처럼 긴 연산자 체인과 여러 스케줄러를 넘나드는 복잡한 파이프라인에서는, subscribeOn과 같은 스케줄링 연산자의 실제 스레드 동작을 코드만으로 완벽히 예측하기 어렵습니다.
아래 코드는 웹한글 코드의 초반 프로토타입 코드 정도인데 이러한 코드의 실제 동작을 명확히 이해하고 검증하기 위해서는, 단순한 단위 테스트를 넘어 스레드 풀과 Prefetch 버퍼 사이즈 이상의 부하를 인가하는 테스트가 필수적입니다.
private Scheduler scheduler = Schedulers.newBoundedElastic(3, 100, "elastic");
private Scheduler newScheduler = Schedulers.newBoundedElastic(3, 100, "new-elastic");
@Test
public void threadReuseWithParallelExecution() throws InterruptedException {
Mono<Void> a = runPipelineA(scheduler);
Mono<Void> b = runPipelineB(scheduler);
Mono<Void> c = runPipelineC(scheduler);
Mono<Void> d = runPipelineD(scheduler);
Flux.from(a)
.mergeWith(b)
.mergeWith(c)
.mergeWith(d)
.subscribe(
Logger::onNext,
Logger::onError,
Logger::onComplete
);
Thread.sleep(10000);
}
private Mono<Void> runPipelineA(Scheduler scheduler) {
return runPipeline("A", scheduler);
}
...
private Mono<Void> runPipeline(String name, Scheduler scheduler) {
return Mono.fromCallable(() -> {
Logger.info(name + ": run");
return name + " run";
})
.flatMap(result -> Mono.fromCallable(() -> {
Logger.info(name + ": step 1");
Thread.sleep(300);
return result + " (step 1)";
}).subscribeOn(newScheduler))
.flatMap(result -> Mono.fromCallable(() -> {
Logger.info(name + ": step 2");
return result + " (step 2)";
}))
.doOnNext(result -> Logger.info(name + " done: " + result))
.then()
.subscribeOn(scheduler);
}가벼운 부하 상태에서는 스레드가 즉시 재활용되거나 큐에 작업이 쌓이지 않아, 스케줄러의 최대 성능이나 한계 상황에서의 동작(예: 작업 큐잉, 스레드 생성 제한)을 관찰할 수 없습니다.
따라서 의도한 대로 동작하는지 검증하려면, 스레드 풀과 Prefetch 버퍼 사이즈 이상의 부하를 가하는 테스트를 통해 다음을 확인해야 합니다.
① 스레드 격리 검증
: scheduler와 newScheduler의 스레드가 실제로 분리되어 사용되는지 스레드 이름을 로그로 직접 확인합니다.
② 병목 및 한계 상황 확인
: 의도적으로 스레드 풀을 모두 사용하게 만들어, 이후의 작업들이 큐에 정상적으로 대기하는지, 또는 거부되는지를 관찰합니다.
③ 자원 효율성 검증
: 부하가 줄어들었을 때 스레드가 예상대로 재활용되거나 소멸되는지 확인합니다.
결론적으로, 복잡한 리액티브 파이프라인의 스레드 모델은 추측이 아닌 경험적 데이터로 검증해야 합니다. 실제 운영 환경과 유사한 부하를 발생시켜 로그를 통해 스레드의 움직임을 직접 눈으로 확인하는 과정은, 안정적인 시스템을 구축하기 위한 시니어 개발자의 필수적인 검증 단계입니다.
브레이크 포인트는 비동기 코드의 실행 흐름을 왜곡할 수 있으므로, 스레드와 시간 정보가 담긴 로그로 실제 순서를 파악하는 것이 훨씬 정확하고 안전합니다.
4.5. Sinks를 이용한 Graceful Shutdown 구현 전략
비동기 시스템에서 애플리케이션을 종료할 때, 메모리 버퍼(Sink)에 남아있거나 처리 중인 작업이 유실될 수 있습니다. 이 아키텍처는 스프링의 생명주기와 Reactor의 스트림 완료 시그널, 그리고 CompletableFuture를 조합하여, 모든 진행 중인 작업이 안전하게 완료될 때까지 애플리케이션 종료를 지연시키는 Graceful Shutdown 패턴을 구현했습니다.
1단계: 종료 신호 감지 (Spring Lifecycle Hook)
프로세스는 스프링 컨테이너가 종료를 시작할 때 CustomListenerEndpointRegistry의 stop() 메서드를 호출하면서 시작됩니다. RabbitListenerEndpointRegistry를 상속하여 stop 메서드를 오버라이딩함으로써, RabbitMQ 리스너가 강제로 중단되기 전에 우리가 원하는 사전 작업을 수행할 기회를 가로챕니다. 여기서 rabbitTaskManager.setShutdown(true)을 호출하여 커스텀 종료 프로세스를 트리거 합니다.
@Service
public class CustomListenerEndpointRegistry extends RabbitListenerEndpointRegistry {
private final RabbitTaskManager rabbitTaskManager;
@Override
public void stop(Runnable callback) {
// 1. RabbitMQ 리스너를 멈추기 전에 TaskManager의 종료 로직을 먼저 실행
rabbitTaskManager.setShutdown(true);
// 2. TaskManager의 작업이 모두 끝난 후, 원래의 리스너 중단 로직 실행
super.stop(callback);
}
}2단계: 작업 유입 차단 및 완료 대기
rabbitTaskManager.setShutdown(true)가 호출되면, 두 가지 중요한 동작이 수행됩니다.
- sinks.tryEmitComplete(): 더 이상 새로운 메시지가 Sink로 들어오지 못하도록 입구를 차단합니다.
- shutdownCompletableFuture.join(): 스프링의 종료 스레드를 동기적으로 블록 시킵니다. 이제 스프링은 Sink의 버퍼에 남아있는 모든 메시지가 처리될 때까지 기다리게 됩니다.
// RabbitTaskManager.java
public void setShutdown(boolean shutdown){
// ...
this.shutdown = shutdown;
// 1. Sink를 닫아 더 이상 새로운 메시지를 받지 않도록 함
Sinks.EmitResult emitResult = unicastSinks.tryEmitComplete();
try {
// 3. Consumer 파이프라인이 완료 신호를 줄 때까지 스프링 종료 스레드를 대기시킴
Boolean result = shutdownCompletableFuture
.orTimeout(...)
.join();
log.info(generateMessage(API_SHUTDOWN, "5. Shutdown completed : " + result));
} catch (Exception e) {
// ...
}
}3단계: 비동기 작업 완료 및 신호 전송
Consumer 파이프라인(init() 메서드)은 Sink가 닫히더라도 버퍼에 남아있는 모든 메시지를 계속해서 처리합니다. 마지막 메시지까지 처리가 모두 끝나고 스트림이 정상적으로 완료되면, doOnComplete 연산자가 트리거 됩니다. 이 콜백 함수는 대기하고 있던 shutdownCompletableFuture에 complete(true) 신호를 보내, 모든 비동기 작업이 안전하게 끝났음을 알려줍니다. 이 신호를 받은 setShutdown 메서드의 join()은 대기를 멈추고, 애플리케이션은 데이터 유실 없이 안전하게 종료됩니다.
// RabbitTaskManager.java
@PostConstruct
public void init() {
unicastSinks.asFlux()
.groupBy(...)
.flatMap(groupedFlux -> groupedFlux.concatMap(...))
// ... 모든 메시지 처리 ...
// 2. 파이프라인이 모든 메시지를 처리하고 완료되면 Future에 신호를 보냄
.doOnComplete(() -> {
log.info(generateMessage(API_SHUTDOWN, "3. shutdownCompletableFuture complete : sinks.doOnComplete"));
shutdownCompletableFuture.complete(true);
})
.subscribe();
}4.6. 에러 핸들링과 Context를 활용한 추적성 확보
리액티브 파이프라인이 길고 복잡해질수록, 에러가 발생했을 때 어디서, 왜 문제가 발생했는지 추적하기가 매우 어려워집니다. 긴 스택 트레이스는 익명의 람다 표현식으로 가득 차 가독성이 떨어지며, 이는 디버깅과 유지 보수를 어렵게 만드는 주된 요인입니다.
4.6.1. 전략적 에러 핸들링과 연산자 체인 분리
긴 연산자 체인은 코드 가독성을 해치고 에러 추적을 어렵게 만듭니다. 이를 해결하기 위해 메서드 분리와 목적에 맞는 에러 처리 연산자를 사용하는 것이 중요합니다.
execute 메서드는 validateRevision, handleAction 등 여러 메서드를 조합하며, 각 단계에서 onErrorResume으로 로그를 보강하고, 마지막에 onErrorMap으로 예외를 표준화하여 역할을 명확히 분리합니다.
public Mono<Void> execute(DocMessage message) {
return Mono.deferContextual(ctx ->
// 1. 각 단계를 private 메서드로 분리하여 가독성 확보
validateRevision(ctx.get(KEY_DOC_ID), ctx.get(KEY_REVISION))
.then(handleAction(ctx.get(KEY_DOC_ID), ctx.get(KEY_REVISION), ctx.get(KEY_ACTION)))
// 2. 중간 단계에서는 onErrorResume으로 로그만 보강하고 에러는 다시 전파
.onErrorResume(err -> generateQueueMessage(false)
.doOnNext(queueLogger::info)
.flatMap(msg -> Mono.error(err))
)
// 3. 필요에 따라 최종적으로 모든 내부 예외를 표준화된 도메인 예외로 변환
.onErrorMap(e -> new DocServerException(String.valueOf(determineErrorCode(e))))
)
.contextWrite(...);
}4.6.2. Context API를 이용한 로그 추적성 강화
긴 리액티브 체인에서 에러 발생 시 원인이 된 요청을 추적하기는 어렵고, 모든 메서드에 docId 같은 컨텍스트 정보를 넘기는 것은 비효율적입니다. Reactor의 Context API는 파라미터 전달 없이도 요청 범위의 데이터를 파이프라인 전체에 전파하는 ‘보이지 않는 가방’ 역할을 합니다. contextWrite로 데이터를 주입하고 deferContextual로 읽어, 모든 로그와 에러에 고유 식별자를 포함시켜 추적성을 극대화할 수 있습니다.
generateActionMessage 메서드는 shortMsg라는 단순한 인자만 받지만, Mono.deferContextual을 통해 Context에 접근하여 docId, action 등 훨씬 더 풍부한 정보를 담은 로그 메시지를 생성합니다.
// MessageBuilder.java
public static Mono<String> generateActionMessage(String shortMsg) {
// 1. deferContextual을 통해 구독 시점의 Context에 접근
return Mono.deferContextual(context -> {
// 2. Context에서 docId, action 등 요청 범위의 데이터를 꺼냄
String docId = context.getOrDefault(KEY_DOC_ID, "");
String startApiPath = context.getOrDefault(KEY_START_API_PATH, "");
String actionStr = context.getOrEmpty(KEY_ACTION)
.map(HwpJsonObject::toJson)
.orElse("");
// 3. 풍부한 정보가 담긴 로그 메시지를 생성하여 Mono로 반환
return Mono.just(generateMessage(docId, startApiPath, shortMsg, actionStr));
});
}
// ActionExecutorService.java
public Mono<Void> execute(DocMessage message) {
return Mono.deferContextual(ctx ->
// ...
// 파이프라인 어디서든 generateActionMessage를 호출하여 컨텍스트 기반 로그 생성 가능
.onErrorResume(err -> generateActionMessage("validateRevision")
.doOnNext(msg -> log.error(msg, err))
.flatMap(msg -> Mono.error(err))
)
// ...
)
// 4. 구독 체인의 마지막에서 Context에 데이터를 씀
.contextWrite(ctx -> ctx
.put(KEY_DOC_ID, message.getDocId())
.put(KEY_REVISION, message.getAction().getInteger(REVISION))
.put(KEY_ACTION, message.getAction())
);
}4.6.3.메모리 누수 추적
복잡한 리액티브 파이프라인에서 에러를 부적절하게 처리하면, 업스트림 Publisher가 cancel 시그널을 받지 못해 스트림이 끝나지 않는 ‘좀비 스트림’이 발생할 수 있습니다. 이 경우, 해당 스트림이 점유하고 있던 리소스(DB 커넥션, 캐시, 소켓 등)가 해제되지 않아 심각한 메모리 누수로 이어질 수 있습니다.
4.7. 리액티브 프로그래밍의 실무적 도전 과제
리액티브 프로그래밍은 강력한 만큼, 실제 개발 및 운영 단계에서 다음과 같은 현실적인 어려움에 직면하게 됩니다.
- 디버깅 및 오류 추적의 복잡성
- 어려운 디버깅: 비동기 스레드 전환으로 인해 브레이크 포인트를 이용한 전통적인 디버깅 방식이 거의 무력화되며, 실제 실행 흐름을 파악하기 어렵습니다.
- 긴 스택 트레이스: 긴 연산자 체인에서 예외가 발생하면, 익명의 람다로 가득 찬 거대한 스택 트레이스가 생성되어 실제 오류의 근원을 찾기가 매우 힘듭니다.
- 동작 예측의 어려움
- 경험적 검증의 필요성: 스케줄러의 스레드 동작은 이론만으로 예측하기 어렵기 때문에, 반드시 부하를 주어 로그를 직접 출력해 보는 경험적 검증이 필요합니다.
- 부분적 코드 분석의 한계: 리액티브 코드는 전체 체인이 유기적으로 연결되어 있어, 코드의 일부만 보고 전체 동작을 정확히 파악하기 어렵습니다.
- 분산 환경에서의 복잡성
- 순서 보장의 어려움: 분산 환경의 여러 컴포넌트에서 비동기적으로 발행되는 이벤트(Publisher)들을 비즈니스 로직에 맞게 정확한 순서로 조합하는 것은 고도의 설계 능력을 요구하는 복잡한 과제입니다.
Conclusion
1. Reactor 도입, 조직의 전략적 선택과 가이드
리액티브 프로그래밍, 특히 Reactor는 강력한 만큼 다루기 까다로우며, 개인의 역량을 넘어 팀 전체의 기술적 성숙도를 요구하는 도전 과제를 안고 있습니다.
비동기 스레드 전환으로 인해 브레이크 포인트를 이용한 전통적인 디버깅이 어렵고, 긴 연산자 체인에서 발생한 예외는 스택 트레이스 추적이 매우 힘듭니다. 스케줄러의 실제 동작은 예측이 어려워 반드시 부하 테스트를 통한 경험적 검증이 필요하며, 분산 환경에서는 비동기 이벤트의 순서 보장이 고도의 설계 능력을 요구하는 과제입니다.
이러한 복잡성은 아직 AI 조차 명확한 답을 주기 어려워, 오히려 동료와 함께 내부 코드를 직접 분석하는 것이 더 올바른 방향일 때가 많습니다. 결국 리액티브 프로그래밍의 도입은, 이러한 가파른 학습 곡선과 디버깅 비용을 감수해야 하는 단기적인 생산성과 직결되는 문제입니다.
그럼에도 불구하고 수많은 조직이 이 패러다임을 선택하는 이유는, 리액티브 아키텍처가 제공하는 회복성(Resilience)과 효율성(Efficiency)이라는 두 가지 명확한 비즈니스 가치 때문입니다.
스트림 기반의 에러 모델은 예측 가능한 방식으로 장애를 격리하고 제어하여, 안정적인 서비스를 제공할 수 있는 강력한 기반이 됩니다. 또한, 논블로킹 모델은 한정된 인프라 리소스로 막대한 트래픽을 감당하게 하여, 운영 비용 절감과 탁월한 확장성을 이끌어냅니다.
2. 조직 및 팀 도입을 위한 가이드
이러한 가치를 성공적으로 얻기 위해, 조직은 다음과 같은 전략적 접근이 필요합니다.
- 점진적 도입과 명확한 범위 설정: 전체 시스템을 한 번에 전환하기보다, MSA 환경에서 비교적 독립적이면서 I/O 부하가 높은 특정 서비스(예: API 게이트웨이, 데이터 스트리밍 파이프라인)에 우선적으로 적용하여 경험을 축적하는 것이 안전합니다.
- 학습 문화 조성 및 코드 리뷰 강화: Reactor의 가파른 학습 곡선을 고려하여, 팀 내 스터디, 페어 프로그래밍, 그리고 시니어 개발자가 주도하는 집중적인 코드 리뷰가 필수적입니다. 특히 에러 처리, 스케줄러 사용, StepVerifier를 이용한 테스트 케이스 작성에 대한 컨벤션을 확립하고 공유해야 합니다.
- 공통 패턴의 라이브러리화: 자주 사용되는 블로킹 I/O 처리나 에러 복구 로직 등은 팀 내 공통 라이브러리로 만들어 추상화하는 것이 좋습니다. 이를 통해 개별 개발자는 복잡한 내부 구현을 모두 알지 못해도, 안정성이 검증된 코드를 재사용하여 생산성을 높일 수 있습니다.
결론적으로, Reactor를 조직에 도입하는 것은 단순히 새로운 기술을 채택하는 것을 넘어, 학습 비용을 기꺼이 투자하고 팀의 역량을 함께 성장시켜, 시스템의 회복성과 효율성이라는 더 큰 가치를 얻겠다는 기술 리더십의 의도적인 트레이드오프(Trade-off)이자 전략적 결단입니다.
References
- https://www.reactivemanifesto.org/
- Reactive Streams
- https://docs.spring.io/spring-framework/docs/5.3.27/reference/html/web-reactive.html#webflux
- https://projectreactor.io/docs/core/release/reference/apdx-operatorChoice.html